对于要替换的词是随机选择的,因此一种直观感受是,如果一些重要词被替换了,那么增强后文本的质量会大打折扣。这一部分介绍的方法,则是为了尽量避免这一问题,所实现的词替换技术,姑且称之为「基于非核心词替换的数据增强技术」。
我们最早是在 google 提出 UDA 算法的那篇论文中发现的这一技术 [6],是否在更早的文献中出现过,我们没有再深究了,有了解的同学请留言告知。
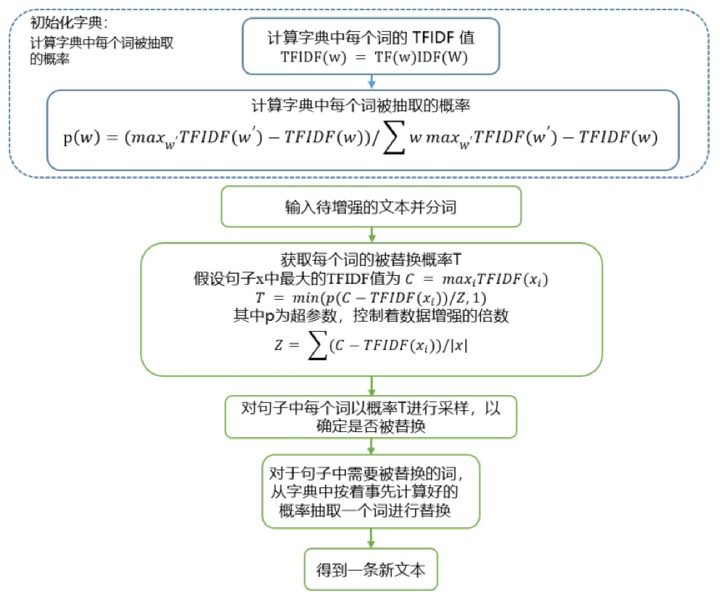
整个技术的核心点也比较简单,用词典中不重要的词去替换文本中一定比例的不重要词,从而产生新的文本。
我们知道在信息检索中,一般会用 TF-IDF 值来衡量一个词对于一段文本的重要性,下面简单介绍一下 TF-IDF 的定义:
TF(词频)即一个词在文中出现的次数,统计出来就是词频 TF,显而易见,一个词在文章中出现很多次,那么这个词可能有着很大的作用,但如果这个词又经常出现在其他文档中,如「的」、「我」,那么其重要性就要大打折扣,后者就是用 IDF 来表征。
IDF(逆文档频率),一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。

TF-IDF = TF×IDF,通过此公式可以有效衡量一个词对于一段文本的重要性。当我们知道一个词对于一个文本的重要性之后,再采用与 TF-IDF 负相关的概率去采样文中的词,用来决定是否要替换,这样可以有效避免将文本中的一些关键词进行错误替换或删除。
UDA 论文中所提出的具体实现方式如下: