事务并发带来的问题前文已经描述得非常仔细了。事务的隔离级别就是为了针对并发出现的问题,不同的级别可以保证不同的一致性。
为了解决上面讲到的并发事务处理带来的问题,SQL标准提出了4个等级的事务隔离级别。不同的隔离级别在同样的环境下会出现不同的结果。
|
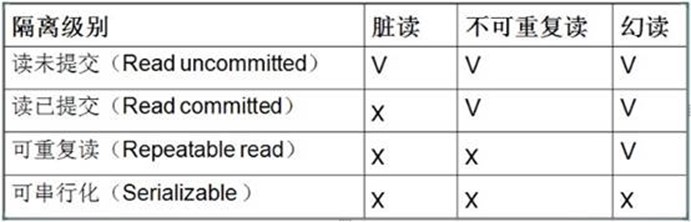
隔离级别 |
读数据一致性 |
脏读 |
不可重复读 |
幻读 |
|
未提交读(Read uncommitted) |
最低级别,只能保证不读取物理上损坏的数据 |
是 |
是 |
是 |
|
已提交读(Read committed) |
语句级 |
否 |
是 |
是 |
|
可重复读(Repeatable read) |
事务级 |
否 |
否 |
是 |
|
可序列化(Serializable) |
最高级别,事务级 |
否 |
否 |
否 |
1. DEFAULT: 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
2. READ_UNCOMMITTED: 这是事务最低的隔离级别,它充许令外一个事务可以看到这个事务未提交的数据。
3. READ_COMMITTED: 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据
4.REPEATABLE_READ: 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。
它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
5. SERIALIZABLE 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。
当前正要执行的事务不在另外一个事务里,那么就起一个新的事务,总之要求在事务里面。
比如说,ServiceB.methodB的事务级别定义为PROPAGATION_REQUIRED, 那么由于执行ServiceA.methodA的时候,
ServiceA.methodA已经起了事务,这时调用 .methodB,ServiceB.methodB看到自己已经运行在ServiceA.methodA
的事务内部,就不再起新的事务。而假如ServiceA.methodA运行的时候发现自己没有在事务中,他就会为自己分配一个事务。
这样,在ServiceA.methodA或者在ServiceB.methodB内的任何地方出现异常,事务都会被回滚。即使ServiceB.methodB的事务已经被
提交,但是ServiceA.methodA在接下来fail要回滚,ServiceB.methodB也要回滚。[关键点:是同一个事务]
class1.fun1--->class2.fun2: fun1调用fun2 ,无论在fun1还是fun2里发生unchecked异常[不论是否catch处理异常],都会触发整个方法的回滚.
这个就比较绕口了。 比如我们设计ServiceA.methodA的事务级别为PROPAGATION_REQUIRED,ServiceB.methodB的事务级别为PROPAGATION_REQUIRES_NEW,
那么当执行到ServiceB.methodB的时候,ServiceA.methodA所在的事务就会挂起,ServiceB.methodB会起一个新的事务,等待ServiceB.methodB的事务完成以后,
他才继续执行。他与PROPAGATION_REQUIRED 的事务区别在于事务的回滚程度了。因为ServiceB.methodB是新起一个事务,那么就是存在
两个不同的事务。如果ServiceB.methodB已经提交,那么ServiceA.methodA失败回滚,ServiceB.methodB是不会回滚的。[关键点:2个事务是单独的,没有依赖关系]如果ServiceB.methodB失败回滚,
如果他抛出的异常被ServiceA.methodA捕获,ServiceA.methodA事务仍然可能提交。
class1.fun1--->class2.fun2: fun1调用fun2 ,
如果fun2抛出异常且被catch处理,则fun2回滚,fun1不回滚.
如果fun2抛出异常且没被catch处理,则fun2,fun1都回滚.
如果fun1抛出异常,则fun1回滚,fun2不回滚.
如果当前在事务中,即以事务的形式运行,如果当前不再一个事务中,那么就以非事务的形式运行
当前不支持事务。比如ServiceA.methodA的事务级别是PROPAGATION_REQUIRED ,而ServiceB.methodB的事务级别是PROPAGATION_NOT_SUPPORTED ,
那么当执行到ServiceB.methodB时,ServiceA.methodA的事务挂起,而他以非事务的状态运行完,再继续ServiceA.methodA的事务。
必须在一个事务中运行。也就是说,他只能被一个父事务调用。直接调用,他就要抛出异常
不能在事务中运行。假设ServiceA.methodA的事务级别是PROPAGATION_REQUIRED, 而ServiceB.methodB的事务级别是PROPAGATION_NEVER ,
理解Nested的关键是savepoint。他与REQUIRES_NEW的区别是,REQUIRES_NEW另起一个事务,将会与他的父事务相互独立,
而Nested的事务和他的父事务是相依的,他的提交是要等和他的父事务一块提交的。也就是说,如果父事务最后回滚,他也要回滚的。而Nested事务的好处是他有一个savepoint。
class1.fun1--->class2.fun2: fun1调用fun2,
如果fun2抛出异常且在fun1里catch处理了,则fun2回滚,fun1不回滚, 如果没有catch,则fun1也回滚.
如果fun1抛出异常,则fun1和fun2都回滚.
我们知道,应用中的一个业务逻辑,往往由多条语句组合完成。那么我们就可以简单地将事务理解为一组SQL语句的集合,要么这个集合全部成功集合,要么这个集合就全部失败退回到第一句之前的状态。
1. 开启事务start transaction,可以简写为 begin
4. 如果所有的sql都执行成功,则提交,将sql的执行结果持久化到数据表内。
6. 如果存在失败的sql,则需要回滚,将sql的执行结果,退回到事务开始之时
7. 无论回滚还是提交,都会关闭事务!需要再次开启,才能使用。
语法说完了,浮躁的人也不用继续看下去了。下面简单说一下事务的基本原理吧。
如果我们不开启事务,只执行一条sql,马上就会持久化数据,可以看出,普通的执行就是立即提交。
也就是说,开启事务,实际上就是关闭了自动提交的功能,改成了commit手动提交!
我们可以通过简单的对是否自动提交加以设置,完成开启事务的目的!
自动提交的特征是保存在服务的一个autocommit的变量内。可以进行修改:

还需要注意一点,就是事务类似于外键约束,只被innodb引擎支持。
下面来说说事务的特点ACID。也就是原子性,一致性,隔离性和持久性。
事务并发会带来一些问题,所以才有了不同的事务隔离级别。要想了解事务的隔离级别,就必须首先了解事务并发会带来的问题。
一个事务正在对一条记录做修改,但未提交,另一个事务读取了这些脏数据,并进一步处理,就会产生未提交的数据依赖。
|
时间 |
转账事务A |
取款事务B |
|
T1 |
开始事务 |
|
|
T2 |
开始事务 |
|
|
T3 |
查询账户余额为1000元 |
|
|
T4 |
取出500元把余额改为500元 |
|
|
T5 |
查询账户余额为500元(脏读) |
|
|
T6 |
撤销事务余额恢复为1000元 |
|
|
T7 |
汇入100元把余额改为600元 |
|
|
T8 |
提交事务 |
|
时间 |
取款事务A |
转账事务B |
|
T1 |
开始事务 |
|
|
T2 |
开始事务 |
|
|
T3 |
查询账户余额为1000元 |
|
|
T4 |
查询账户余额为1000元 |
|
|
T5 |
取出100元把余额改为900元 |
|
|
T6 |
提交事务 |
|
|
T7 |
查询账户余额为900元(和T4读取的不一致) |
幻读和不可重复读的概念类似,都是不同时间数据不一致,只不过幻读是针对新增数据,而不可重复读是针对更改数据。
|
时间 |
统计金额事务A |
转账事务B |
|
T1 |
开始事务 |
|
|
T2 |
开始事务 |
|
|
T3 |
统计总存款数为10000元 |
|
|
T4 |
新增一个存款账户,存款为100元 |
|
|
T5 |
提交事务 |
|
|
T6 |
再次统计总存款数为10100元(幻象读) |
|
时间 |
取款事务A |
转账事务B |
|
T1 |
开始事务 |
|
|
T2 |
开始事务 |
|
|
T3 |
查询账户余额为1000元 |
|
|
T4 |
查询账户余额为1000元 |
|
|
T5 |
汇入100元把余额改为1100元 |
|
|
T6 |
提交事务 |
|
|
T7 |
取出100元将余额改为900元 |
|
|
T8 |
撤销事务 |
|
|
T9 |
余额恢复为1000元(丢失更新) |