MongoDB中有几种日志?
任何一种数据库都有各种各样的日志,MongoDB也不例外。MongoDB中有4种日志,分别是系统日志、Journal日志、oplog主从日志、慢查询日志等。这些日志记录着MongoDB数据库不同方面的踪迹。下面分别介绍这几种日志。
一、系统日志
系统日志在MongoDB数据库中很重要,它记录着MongoDB启动和停止的操作,以及服务器在运行过程中发生的任何异常信息。
配置系统日志的方法比较简单,在启动mongod时指定logpath参数即可
mongod -logpath=/data/log/mongodb/serverlog.log -logappend
系统日志会向logpath指定的文件持续追加。
二、Journal日志
journaling(日记) 日志功能则是 MongoDB 里面非常重要的一个功能 , 它保证了数据库服务器在意外断电 、 自然灾害等情况下数据的完整性。它通过预写式的redo日志为MongoDB增加了额外的可靠性保障。开启该功能时,MongoDB会在进行写入时建立一条Journal日志,其中包含了此次写入操作具体更改的磁盘地址和字节。因此一旦服务器突然停机,可在启动时对日记进行重放,从而重新执行那些停机前没能够刷新到磁盘的写入操作。
MongoDB配置WiredTiger引擎使用内存缓冲区来保存journal记录,WiredTiger根据以下间隔或条件将缓冲的日志记录同步到磁盘
- 从MongoDB 3.2版本开始每隔50ms将缓冲的journal数据同步到磁盘
- 如果写入操作设置了j:true,则WiredTiger强制同步日志文件
- 由于MongoDB使用的journal文件大小限制为100MB,因此WiredTiger大约每100MB数据创建一个新的日志文件。当WiredTiger创建新的journal文件时,WiredTiger会同步以前journal文件
MongoDB达到上面的提交,便会将更新操作写入日志。这意味着MongoDB会批量地提交更改,即每次写入不会立即刷新到磁盘。不过在默认设置下,系统发生崩溃时,不可能丢失超过50ms的写入数据。
数据文件默认每60秒刷新到磁盘一次,因此Journal文件只需记录约60s的写入数据。日志系统为此预先分配了若干个空文件,这些文件存放在/data/db/journal目录中,目录名为_j.0、_j.1等
长时间运行MongoDB后,日志目录中会出现类似_j.6217、_j.6218的文件,这些是当前的日志文件,文件中的数值会随着MongoDB运行时间的增长而增大。数据库正常关闭后,日记文件会被清除(因为正常关闭后就不在需要这些文件了).
向mongodb中写入数据是先写入内存,然后每隔60s在刷盘,同样写入journal,也是先写入对应的buffer,然后每隔50ms在刷盘到磁盘的journal文件
使用WiredTiger,即使没有journal功能,MongoDB也可以从最后一个检查点(checkpoint,可以想成镜像)恢复;但是,要恢复在上一个检查点之后所做的更改,还是需要使用Journal
如发生系统崩溃或使用kill -9命令强制终止数据库的运行,mongod会在启动时重放journal文件,同时会显示出大量的校验信息。
上面说的都是针对WiredTiger引擎,对于MMAPv1引擎来说有一点不一样,首先它是每100ms进行刷盘,其次它是通过private view写入journal文件,通过shared view写入数据文件。这里就不过多讲解了,因为MongoDB 4.0已经不推荐使用这个存储引擎了。
从MongoDB 3.2版本开始WiredTiger是MongoDB推荐的默认存储引擎
需要注意的是如果客户端的写入速度超过了日记的刷新速度,mongod则会限制写入操作,直到日记完成磁盘的写入。这是mongod会限制写入的唯一情况。
固定集合(Capped Collection)
在讲下面两种日志之前先来认识下capped collection。
MongoDB中的普通集合是动态创建的,而且可以自动增长以容纳更多的数据。MongoDB中还有另一种不同类型的集合,叫做固定集合。固定集合需要事先创建好,而且它的大小是固定的。固定集合的行为类型与循环队列一样。如果没有空间了,最老的文档会被删除以释放空间,新插入的文档会占据这块空间。
创建固定集合:
db.createCollection("collectionName",{"capped":true, "size":100000, "max":100})
创建了一个大小为100000字节的固定大小集合,文档数量为100.不管先到达哪个限制,之后插入的新文档就会把最老的文档挤出集合:固定集合的文档数量不能超过文档数量限制,也不能超过大小限制。
固定集合创建之后就不能改变,无法将固定集合转换为非固定集合,但是可以将常规集合转换为固定集合。
db.runCommand({"convertToCapped": "test", "size" : 10000});
固定集合可以进行一种特殊的排序,称为自然排序(natural sort),自然排序返回结果集中文档的顺序就是文档在磁盘的顺序。自然顺序就是文档的插入顺序,因此自然排序得到的文档是从旧到新排列的。当然也可以按照从新到旧:
db.my_capped_collection.find().sort({"$natural": -1});固定集合Capped collections的特点,它的插入速度非常快,基本和磁盘的写入速度差不多,并且支持按照插入顺序高效的查询操作。Capped collections的大小是固定的,它的工作方式很像环形缓冲器(circular buffers), 当剩余空间不足时,会覆盖最先插入的数据。
Capped collections的特点是高效插入和检索,所以最好不要在Capped collections上添加额外的索引,否则会影响插入速度。Capped collections可以用于以下场景:
- 存储日志: Capped collections的first-in-first-out特性刚好满足日志事件的存储顺序;
- 缓存小量数据:因为缓存的特点是读多写少,所以可以适当使用索引提高读取速度。
Capped collections的使用限制:
- 如果更新数据,你需要为之创建索引以防止collection scan;
- 更新数据时,文档的大小不能改变。比如说name属性为'abc',则只能修改成3个字符的字符串,否则操作将会失败;
- 数据不允许删除,如果非删除不可,只能drop collection
- 不支持sharding
- 默认只支持按自然顺序(即插入顺序)返回结果
Capped collections可以使用$natural操作符按插入顺序的正序或反序返回结果:
db['oplog.rs'].find({}).sort({$natural: -1})
三、oplog简介
3.1、oplog简介
oplog主从日志
Replica Sets复制集用于在多台服务器之间备份数据。MongoDB的复制功能是使用操作日志oplog实现的,操作日志包含了主节点的每一次写操作。oplog是主节点的local数据库中的一个固定集合。备份节点通过查询这个集合就可以知道需要进行复制的操作。
一个mongod实例中的所有数据库都使用同一个oplog,也就是所有数据库的操作日志(插入,删除,修改)都会记录到oplog中
每个备份节点都维护着自己的oplog,记录着每一次从主节点复制数据的操作。这样,每个成员都可以作为同步源给其他成员使用。
如图所示,备份节点从当前使用的同步源中获取需要执行的操作,然后在自己的数据集上执行这些操作,最后再将这些操作写入自己的oplog,如果遇到某个操作失败的情况(只有当同步源的数据损坏或者数据与主节点不一致时才可能发生),那么备份节点就会停止从当前的同步源复制数据。
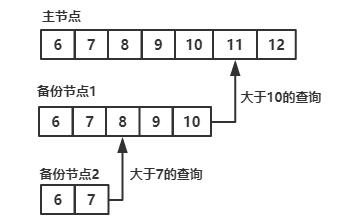
oplog中按顺序保存着所有执行过的写操作,replica sets中每个成员都维护者一份自己的oplog,每个成员的oplog都应该跟主节点的oplog完全一致(可能会有一些延迟)
如果某个备份节点由于某些原因挂了,但它重新启动后,就会自动从oplog中最后一个操作开始进行同步。由于复制操作的过程是想复制数据在写入oplog,所以备份节点可能会在已经同步过的数据上再次执行复制操作。MongoDB在设计之初就考虑到了这种情况:将oplog中的同一个操作执行多次,与只执行一次的效果是一样的。
由于oplog大小是固定的,它只能保持特定数量的操作日志。通常,oplog使用空间的增长速度与系统处理写请求的速率几乎相同:如果主节点上每分钟处理了1KB的写入请求,那么oplog很可能也会在一分钟内写入1KB条操作日志。
但是,有一些例外:如果单次请求能够影响到多个文档(比如删除多个文档或者多文档更新),oplog中就会出现多条操作日志。如果单个操作会影响多个文档,那么每个受影响的文档都会对应oplog的一条日志。因此,如果执行db.student.remove()删除了10w个文档,那么oplog中也就会有10w条操作日志,每个日志对应一个被删除的文档。如果执行大量的批量操作,oplog很快就会被填满。
Oplog是一种特殊的Capped collections,特殊之处在于它是系统级Collection,记录了数据库的所有操作,集群之间依靠Oplog进行数据同步。Oplog的全名是local.oplog.rs,位于local数据下。由于local数据不允许创建用户,如果要访问Oplog需要借助其它数据库的用户,并且赋予该用户访问local数据库的权限,例如:
db.createUser({ user: "play-community", pwd: "******", "roles" : [ { "role" : "readWrite", "db" : "play-community" }, { "role" : "read", "db" : "local" } ] })
Oplog记录的操作记录是幂等的(idempotent),这意味着你可以多次执行这些操作而不会导致数据丢失或不一致。例如对于$inc操作,Oplog会自动将其转换为$set操作,例如原始数据如下:
{
"_id" : "0",
"count" : 1.0
}
执行如下$inc操作:
db.test.update({_id: "0"}, {$inc: {count: 1}})
Oplog记录的日志为:
{
"ts" : Timestamp(1503110518, 1),
"t" : NumberLong(8),
"h" : NumberLong(-3967772133090765679),
"v" : NumberInt(2),
"op" : "u",
"ns" : "play-community.test",
"o2" : {
"_id" : "0"
},
"o" : {
"$set" : {
"count" : 2.0
}
}
}
这种转换可以保证Oplog的幂等性。另外Oplog为了保证插入性能,不允许额外创建索引。
oplog是local库下的一个固定集合,Secondary就是通过查看Primary 的oplog这个集合来进行复制的。每个节点都有oplog,记录这从主节点复制过来的信息,这样每个成员都可以作为同步源给其他节点。
Timestamps格式
MongoDB有一种特殊的时间格式Timestamps,仅用于内部使用,例如上面Oplog记录:
Timestamp(1503110518, 1)
Timestamps长度为64位:
- 前32位是time_t值,表示从epoch时间至今的秒数
- 后32位是ordinal值,该值是一个顺序增长的序数,表示某一秒内的第几次操作
3.2、副本集数据同步的过程
副本集中数据同步的详细过程:Primary节点写入数据,Secondary通过读取Primary的oplog得到复制信息,开始复制数据并且将复制信息写入到自己的oplog。如果某个操作失败(只有当同步源的数据损坏或者数据与主节点不一致时才可能发生),则备份节点停止从当前数据源复制数据。如果某个备份节点由于某些原因挂掉了,当重新启动后,就会自动从oplog的最后一个操作开始同步,同步完成后,将信息写入自己的oplog,由于复制操作是先复制数据,复制完成后再写入oplog,有可能相同的操作会同步两份,不过MongoDB在设计之初就考虑到这个问题,将oplog的同一个操作执行多次,与执行一次的效果是一样的。可以简单的将其视作Mysql中的binlog。
3.3.1、同步类型
initial sync(初始化):这个过程发生在当副本集中创建一个新的数据库或其中某个节点刚从宕机中恢复,或者向副本集中添加新的成员的时候,默认的,副本集中的节点会从离它最近的节点复制oplog来同步数据,这个最近的节点可以是primary也可以是拥有最新oplog副本的secondary节点。
replication(复制):在初始化后这个操作会一直持续的进行着,以保持各个secondary节点之间的数据同步。
3.3.2、Oplog大小:
capped collection是MongoDB中一种提供高性能插入、读取和删除操作的固定大小集合,当集合被填满的时候,新的插入的文档会覆盖老的文档。
在64位的Linux,Solaris,FreeBSD以及Windows系统上,MongoDB会分配磁盘剩余空间的5%作为oplog的大小,如果这部分小于1GB则分配1GB的空间
在64的OS X系统上会分配183MB
在32位的系统上则只分配48MB
3.3.3、oplog的增长速度
oplog是固定大小,他只能保存特定数量的操作日志,通常oplog使用空间的增长速度跟系统处理写请求的速度相当,如果主节点上每分钟处理1KB的写入数据,那么oplog每分钟大约也写入1KB数据。如果单次操作影响到了多个文档(比如删除了多个文档或者更新了多个文档)则oplog可能就会有多条操作日志。db.testcoll.remove() 删除了1000000个文档,那么oplog中就会有1000000条操作日志。如果存在大批量的操作,oplog有可能很快就会被写满了。
3.3.4、oplog的监控
## 查看 oplog 的状态
shard1:PRIMARY> rs.printReplicationInfo()
configured oplog size: 1674.7353515625MB
log length start to end: 102397secs (28.44hrs)
oplog first event time: Tue Oct 09 2018 18:17:42 GMT+0800 (CST)
oplog last event time: Wed Oct 10 2018 22:44:19 GMT+0800 (CST)
now: Wed Oct 10 2018 22:44:23 GMT+0800 (CST
## 查看集群 Oplog 使用情况
shard1:PRIMARY> db.getReplicationInfo()
{
"logSizeMB" : 1674.7353515625,
"usedMB" : 0.33,
"timeDiff" : 102307,
"timeDiffHours" : 28.42,
"tFirst" : "Tue Oct 09 2018 18:17:42 GMT+0800 (CST)",
"tLast" : "Wed Oct 10 2018 22:42:49 GMT+0800 (CST)",
"now" : "Wed Oct 10 2018 22:42:52 GMT+0800 (CST)"
}
## 查看集群延迟情况
shard1:PRIMARY> db.printSlaveReplicationInfo()
source: 10.100.25.42:27001
syncedTo: Wed Oct 10 2018 22:40:39 GMT+0800 (CST)
0 secs (0 hrs) behind the primary
四、慢查询日志
MongoDB中使用系统分析器(system profiler)来查找耗时过长的操作。系统分析器记录固定集合system.profile中的操作,并提供大量有关耗时过长的操作信息,但相应的mongod的整体性能也会有所下降。因此我们一般定期打开分析器来获取信息。
默认情况下,系统分析器处于关闭状态,不会进行任何记录。可以在shell中运行db.setProfilingLevel()开启分析器
db.setProfilingLevel(level,<slowms>) 0=off 1=slow 2=all
第一个参数是指定级别,不同的级别代表不同的意义,0表示关闭,1表示默认记录耗时大于100毫秒的操作,2表示记录所有操作。第二个参数则是自定义“耗时过长"标准,比如记录所有耗时操作500ms的操作
db.setProfilingLevel(1,500);
如果开启了分析器而system.profile集合并不存在,MongoDB会为其建立一个大小为若干MB的固定集合(capped collection)。如希望分析器运行更长时间,可能需要更大的空间记录更多的操作。此时可以关闭分析器,删除并重新建立一个新的名为system.profile的固定集合,并令其容量符合要求。然后在数据库上重新启用分析器。
可以通过db.system.profile.stats()查看集合的最大容量
转自:https://www.cnblogs.com/leoyang63/articles/12023731.html