Time:2012-12-20
mail:jibo.tiger@gmail.com
Blog:http://blog.csdn.net/tigerjb/article/details/8450995
转载请注明出处。
前言:
1.基本概念:
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
2. 常用的构造散列函数的方法
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位。散列表的常用构造方法有:
(1)直接定址法
(2)数字分析法
(3)平方取中法
(4)折叠法
(5)随机数法
(6)除留余数法
3、处理冲突的方法
散列表函数设计好的情况下,可以减少冲突,但是无法完全避免冲突。常见有冲突处理方法有:
(1)开放定址法
(2)再散列法
(3)链地址法(拉链法)
(4)建立一个公共溢出区
4. 散列表查找性能分析
散列表的查找过程基本上和造表过程相同。一些关键码可通过散列函数转换的地址直接找到,另一些关键码在散列函数得到的地址上产生了冲突,需要按处理冲突的方法进行查找。在介绍的三种处理冲突的方法中,产生冲突后的查找仍然是给定值与关键码进行比较的过程。所以,对散列表查找效率的量度,依然用平均查找长度来衡量。
查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。因此,影响产生冲突多少的因素,也就是影响查找效率的因素。影响产生冲突多少有以下三个因素:
1. 散列函数是否均匀;
2. 处理冲突的方法;
3. 散列表的装填因子。
散列表的装填因子定义为:α= 填入表中的元素个数 / 散列表的长度。
α是散列表装满程度的标志因子。由于表长是定值,α与“填入表中的元素个数”成正比,所以,α越大,填入表中的元素较多,产生冲突的可能性就越大;α越小,填入表中的元素较少,产生冲突的可能性就越小。实际上,散列表的平均查找长度是装填因子α的函数,只是不同处理冲突的方法有不同的函数。
一.Linux内核哈希表数据结构
hash最重要的是选择适当的hash函数,从而平均的分配关键字在桶中的位置,从而优化查找 插入和删除所用的时间。然而任何hash函数都会出现冲突问题。内核采用的解决哈希冲突的方法是:拉链法拉链法解决冲突的做法是:将所有关键字为同义词的结点链接在同一个链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针(struct hlist_head name)组成的指针数组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α(装填的元素个数/数组长度)可以大于 1,但一般均取α≤1。当然,用拉链法解决hash冲突也是有缺点的,指针需要额外的空间。
1. 其代码位于include/linux/list.h中,3.0内核中将其数据结构定义放在了include/linux/types.h中
哈希表的数据结构定义:
如图: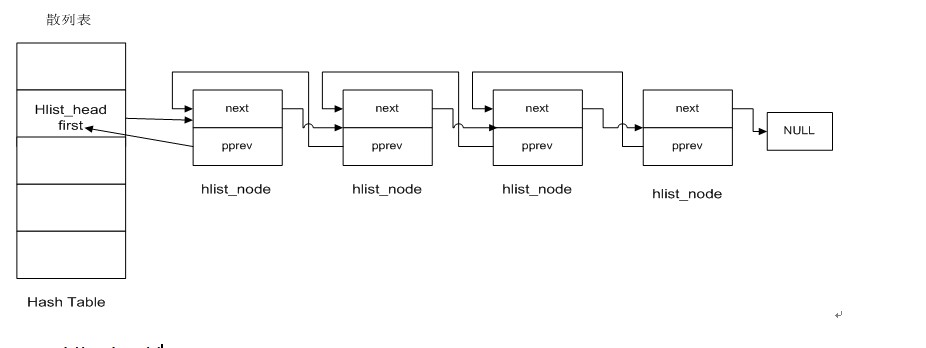
struct hlist_head{
struct hlist_node *first;
}
struct hlist_node {
struct hlist_node *next,**pprev;
}
1>hlist_head表示哈希表的头结点。哈希表中每一个entry(list_entry)所对应的都是一个链表(hlist).hlist_head结构体只有一个域,即first。First指针指向该hlist链表的第一个结点。
2>hlist_node结构体有两个域,next和pprev。
(1)next指向下个hlist_node结点,倘若改结点是链表的最后一个节点,next则指向NULL
(2)pprev是一个二级指针,它指向前一个节点的next指针。
2.Linux 中的hlist(哈希表)和list是不相同的,在list中每个结点都是一样的,不管头结点还是其它结点,使用同一个结构体表示,但是在hlist中,头结点使用的是struct hlist_head来表示的,而对于其它结点使用的是strcuct hlist_node这个数据结果来表示的。还有list是双向循环链表,而hlist不是双向循环链表。因为hlist头结点中没有prev变量。为什么要这样设计呢?
散列表的目的是为了方便快速的查找,所以散列表通常是一个比较大的数组,否则“冲突”的概率会非常大,这样就失去了散列表的意义。如何来做到既能维护一张大表,又能不占用过多的内存呢?此时只能对于哈希表的每个entry(表头结点)它的结构体中只能存放一个指针。这样做的话可以节省一半的指针空间,尤其是在hash bucket很大的情况下。(如果有两个指针域将占用8个字节空间)
3.hlist的结点有两个指针,但是pprev是指针的指针,它指向的是前一个结点的next指针,为什么要采用pprev,二不采用一级指针?
由于hlist不是一个完整的循环链表,在list中,表头和结点是同一个数据结构,直接用prev是ok的。在hlist中,表头中没有prev,只有一个first。
1>为了能统一地修改表头的first指针,即表头的first指针必须修改指向新插入的结点,hlist就设计了pprev。list结点的pprev不再是指向前一个结点的指针,而是指向前一个节点(可能是表头)中的next(对于表头则是first)指针,从而在表头插入的操作中可以通过一致的node->pprev访问和修改前结点的next(或first)指针。
2>还解决了数据结构不一致,hlist_node巧妙的将pprev指向上一个节点的next指针的地址,由于hlist_head和hlist_node指向的下一个节点的指针类型相同,就解决了通用性。
二.哈希表的声明和初始化宏
1.对哈希表头结点进行初始化
实际上,struct hlist_head只定义了链表结点,并没有专门定义链表头,可以使用如下三个宏
#define HLIST_HEAD_INIT { .first = NULL}
#define HLIST_HEAD(name) struct hlist_head name = {.first = NULL}
#define INIT_HLIST_HEAD(ptr) ((ptr->first)=NULL))
1>name 为结构体 struct hlist_head{}的一个结构体变量。
2>HLIST_HEAD_INIT 宏只进行初始化
Eg: struct hlist_head my_hlist = HLIST_HEAD_INIT
调用HLIST_HEAD_INIT对my_hlist哈希表头结点只进行初始化,将表头结点的fist指向空。
3>HLIST_HEAD(name)函数宏既进行声明并且进行初始化。
Eg: HLIST_HEAD(my_hlist);
调用HLIST_HEAD函数宏对my_hlist哈希表头结点进行声明并进行初始化。将表头结点的fist指向空。
4>HLIST_HEAD宏在编译时静态初始化,还可以使用INIT_HLIST_HEAD在运行时进行初始化
Eg:
INIT_HLIST_HEAD(&my_hlist);
调用INIT_HLIST_HEAD俩将my_hlist进行初始化,将其first域指向空即可。
2.对哈希表结点进行初始化
1>Linux 对哈希表结点初始化提供了一个接口:
static iniline void INIT_HLIST_NODE(struct hlist_node *h)
(1) h:为哈希表结点
2>实现:
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}
改内嵌函数实现了对struct hlist_node 结点进行初始化操作,将其next域和pprev都指向空,实现其初始化操作。
三.哈希链表的基本操作(插入,删除,判空)
1.判断哈希链表是否为空
1>function:函数判断哈希链表是否为空,如果为空则返回1.否则返回0
2>函数接口:
static inline int hlist_empty(const struct hlist_head *h)
h:指向哈希链表的头结点。
3>函数实现:
static inline int hlist_empty(const struct hlist_head *h)
{
return !h->first;
}
通过判断头结点中的first域来判断其是否为空。如果first为空则表示该哈希链表为空。
2.判断节点是否在hash表中
1>function:判断结点是否已经存在hash表中。
2>函数接口:
static inline int hlist_unhashed(const struct hlist_node *h)
h:指向哈希链表的结点
3>函数实现:
static inline int hlist_unhashed(const struct hlist_node *h)
{
return !h->pprev
}
通过判断该结点的pprev是否为空来判断该结点是否在哈希链表中。 h->pprev等价于h节点的前一个节点的next域。如果前一个节点的next域为空,说明 改节点不在哈希链表中。
3.哈希链表的删除操作
1>function:将一个结点从哈希链表中删除。
2>函数接口:
static inline void hlist_del(struct hlist_node *n)
n: 指向hlist的链表结点
static inline void hlist_del_init(struct hlist_node *n)
n: 指向hlist的链表结点
3>函数实现
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
*pprev = next;
if (next)
next->pprev = pprev;
}
Step1:首先获取n的下一个结点next
Step2: n->pprev指向n的前一个结点的next指针的地址,这样*pprev就代表n前一个节点的下一个结点的地址(目前指向n本身)
Step3:*pprev=next,即将n的前一个节点和n的下一个结点关联起来。
Step4:如果n是链表的最后一个结点,那么n->next即为空,则无需任何操作;否则,next->pprev=pprev,将n的下一个结点的pprev指向n的pprev(既修改后结点的pprev数值)
此时,我们可以假设 在hlist_node 中采用单级指针,那么该如何进行操作呢?
此时在进行Step3操作时,就需要判断结点是否为头结点。可以用n->prev是否为NULLL来区分头结点和普通结点。
Eg:
struct my_hlist_node *next = n->next ;
struct my_hlist_node *prev = n->prev ;
if(n->prev)
n->prev->next = next ;
else
n->prev = NULL ;
if(next)
next->prev = prev ;
那为什么不进行以上的操作?
(1)代码不够简洁。使用hlist_node结点的话,头结点和普通结点是一致的;
static inline void hlist_del(struct hlist_node *n)
{
__hlist_del(n);
n->next = LIST_POISON1;
n->pprev = LIST_POISON2;
}
Step1:调用__hlist_del(n),删除哈希链表结点n(即修改n的前一个结点和后一个结点的之间的关系)
Step2和Step3:将n结点的next和pprev域分别指向LIST_POISON1和LIST_POISON2。这样设置是为了保证不在链表中的结点项不能被访问。
static inline void hlist_del_init(struct hlist_node *n)
{
if (!hlist_unhashed(n)) {
__hlist_del(n);
INIT_HLIST_NODE(n);
}
}
Step1:先判断该结点是否在哈希链表中,如果不在则不进行删除。如果是则进行第二步
Step2:调用__hlist_del删除结点n
Step3:调用INIT_HLIST_NODE,将结点n进行初始化。
说明:
hlist_del和hlist_del_init都是调用__hlist_dle来删除结点n。唯一不同的是对结点n的处理,前者是将n设置为不可用,后者是将其设置为一个空的结点。
4.添加哈希结点
1>function:将一个结点添加到哈希链表中。
hlist_add_head:将结点n插在头结点h之后。
hlist_add_before:将结点n插在next结点的前面(next在哈希链表中)
hlist_add_after:将结点next插在n之后(n在哈希链表中)
3.0内核新添加了hlist_add_fake函数。
2>Linux 内核提供了三个接口:
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
struct hlist_node *n: n为将要插入的哈希结点
struct hlist head *h: h为哈希链表的头结点。
static inline void hlist_add_before(struct hlist node *n,struct hlist_node *next)
struct hlist node *n: n为将要插入的哈希结点.
struct hlist node *next :next为原哈希链表中的哈希结点。
static inline void hlist_add_after(struct hlist node *n,struct hlist_node *next)
struct hlist node *n: n与原哈希链表中的哈希结点
struct hlist node *next: next为将要插入的哈希结点
注:在3.0内核中新添加了hlist_add_fake
static inline void hlist_add_fake(struct hlist_node *n)
struct hlist_node *n :n链表哈希结点
3>函数实现:
static inline void hlist_add_head(struct hlist_node *n,struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first;
}
Step1: first = h->first。获得当前链表的首个结点.
Step2: 将first赋值给n结点的next域。让n的next与first关联起来。
Step3: 如果first不为空,则将first的pprev指向n的next域。此时完成了first结点的关联。
如果fist为空,则不进行操作。
Step4: h->first = n; 将头结点的fist域指向n,使n成为链表的首结点。
Step5: n->pprev = &h->first; 将n结点的pprev指向链表的fist域,此时完成了对n结点的关联。
/*next must be !=NULL*/
static inline void hlist_add_before(struct hlist_node *n, struct hlist_node *next)
{
n->pprev = next->pprev;
n->next = next;
next->pprev = &n->next;
*(n->pprev) =n ;
}
Step1: n->pprev = next->prev;将next的pprev赋值给n->pprev。使n的pprev 指向next的前一个结点的next。
Step2: n->next = next;将n结点的next指向next,完成对n结点的关联。
Step3: next->pprev = &n->next;此时修改next结点的pprev,使其指向n的next的地址。此时完成next结点的关联。
Step4: *(n->pprev) =n;此时*(n->pprev)即n结点前面的next,使其指向n。完成对n结点的关联。
注:
(1)next不能为空(next即哈希链表中原有的结点)
(2)n为新插入的结点。
static inline void hlist_add_after(struct hlist_node *n, struct hlist_node *next )
{
next->next = n->next;
n->next = next;
next->pprev = &n->next;
if (next->next)
next->next->pprev = &next->next;
}
n为原哈希链表中的结点, next新插入的结点。 将结点next插入到n之后(next是新插入的节点)
Step1: next->next = n->next; 将next->next指向结点n的下一个结点。
Step2: n->next = next; 修改n结点的next,使n指向next。
Step3: next->pprev = &n->next; 将next的pprev指向n的next
Step4: 判断next后的结点是否为空如果,为空则不进行操作,否则将next后结点的pprev指向自己的next 处。
static inline void hlist_add_fake(struct hlist_node *n)
{
n->pprev =&n->next;
}
对这个函数的含义不太明白,望高人指点。
三.哈希链表的其他操作
1.哈希链表的移动
1>function:将以个哈希聊表的头结点用new结点代替,将以前的头结点删除。
2>接口:
static inline void hlist_move_list(struct hlist_head *old, struct hlist_head *new)
struct hlist_head *old:原先哈希链表的头结点
struct hlist_head *new:新替换的哈希链表的头结点
3>实现:
static inline void hlist_move_list(struct hlist_head *old, struct hlist_head *new)
{
new->first = old->first;
if (new->first)
new->fist->pprev = &new->first;
old->first = NULL;
}
Step1: 将new结点的first指向old的第一个结点
Step2: 判断链表头结点后是否有哈希结点。如果为空,则不操作。否则,将表头后的第一个结点的pprev指向新表头结点的first.
Step3:将原先哈希链表头结点的first指向空。
四.哈希链表的遍历
为了方便核心应用遍历链表,linux链表将遍历操作抽象成几个宏。在分析遍历宏之前,先分析下如何从链表中访问到我们所需要的数据项
1.hlist_entry(ptr,type,member)
1>function:通过成员指针获得整个结构体的指针
Linux链表中仅保存了数据项结构中hlist_head成员变量的地址,可以通过hlist_entry宏通过hlist_head成员访问到作为它的所有者的结点数据
2>接口:
hlist_entry(ptr,type,member)
ptr:ptr是指向该数据结构中hlist_head成员的指针,即存储该数据结构中链表的地址值。
type:是该数据结构的类型。
member:改数据项类型定义中hlist_head成员的变量名。
3>hlist_entry宏的实现
#define hlist_entry(ptr, type, member)
container_of(ptr, type, member)
hlist_entry宏调用了container_of宏,关于container_of宏的用法见:
2.遍历操作
1>function:实际上就是一个for循环,从头到尾进行遍历。由于hlist不是循环链表,因此,循环终止条件是pos不为空。使用hlist_for_each进行遍历时不能删除pos(必须保证pos->next有效),否则会造成SIGSEGV错误。而使用hlist_for_each_safe则可以在遍历时进行删除操作。
2>接口:
Linux内核为哈希链表遍历提供了两个接口:
hlist_for_each(pos,head)
pos: pos是一个辅助指针(即链表类型struct hlist_node),用于链表遍历
head:链表的头指针(即结构体中成员struct hlist_head).
hlist_for_each_safe(pos,n,head)
pos: pos是一个辅助指针(即链表类型struct hlist_node),用于链表遍历
n :n是一个临时哈希结点指针(struct hlist_node),用于临时存储pos的下一个链表结点。
head:链表的头指针(即结构体中成员struct hlist_head).
3>函数实现:
(1)#define hlist_for_each(pos, head)
for(pos = (head)->first; pos ; pos = pos->next)
pos是辅助指针,pos是从第一个哈希结点开始的,并没有访问哈希头结点,直到pos为空时结束循环。
(2)#define hlist_for_each_safe(pos,n,head)
for(pos = (head)->first,pos &&({n=pos->next;1;}) ; pos=n)
hlist_for_each是通过移动pos指针来达到遍历的目的。但如果遍历的操作中包含删除pos指针所指向的节点,pos指针的移动就会被中断,因为hlist_del(pos)将把pos的next、prev置成LIST_POSITION2和LIST_POSITION1的特殊值。当然,调用者完全可以自己缓存next指针使遍历操作能够连贯起来,但为了编程的一致性,Linxu内核哈希链表要求调用者另外提供一个与pos同类型的指针n,在for循环中暂存pos下一个节点的地址,避免因pos节点被释放而造成的断链。
此循环判断条件为pos && ({n = pos->next;1;});
这条语句先判断pos是否为空,如果为空则不继续进行判断。如果pos为真则进行判断({n=pos->next;1;})—》该条语句为复合语句表达式,其数值为最后一条语句,即该条语句永远为真,并且将post下一条结点的数值赋值给n。即该循环判断条件只判断pos是否为真,如果为真,则继续朝下进行判断。
({n-pos->next;1;})此为GCC 特有的C扩展,如果你不懂的话,可以参考GCC扩展
五.用链表外的结构体地址来进行遍历,而不用哈希链表的地址进行遍历
Linux提供了从三种方式进行遍历,一种是从哈希链表第一个哈希结点开始遍历;第二种是从哈希链表中的pos结点的下一个结点开始遍历;第三种是从哈希链表中的当前结点开始进行遍历。
1.从哈希链表第一个哈希结点开始进行遍历
1>function: 从哈希链表的第一个哈希结点开始进行遍历。hlist_for_each_entry在进行遍历时不能删除pos(必须保证pos->next有效),否则会造成SIGSEGV错误。而使用hlist_for_each_entry_safe则可以在遍历时进行删除操作。
2>Linux提供了两个接口来实现从哈希表第一个结点开始进行遍历
hlist_for_each_entry(tpos, pos, head, member)
tpos: 用于遍历的指针,只是它的数据类型是结构体类型而不是strut hlist_head 类型
pos: 用于遍历的指针,只是它的数据类型是strut hlist_head 类型
head:哈希表的头结点
member: 该数据项类型定义中hlist_head成员的变量名
hlist_for_each_entry_safe(tpos, pos, n, head, member)
tpos: 用于遍历的指针,只是它的数据类型是结构体类型而不是strut hlist_head 类型
pos: 用于遍历的指针,只是它的数据类型是strut hlist_head 类型
n: 临时指针用于占时存储pos的下一个指针,它的数据类型也是struct hlist_list类型
head: 哈希表的头结点
member: 该数据项类型定义中hlist_head成员的变量名
3>实现
#define hlist_for_each_entry(tpos,pos,head,member)
for (pos = (head)->first;
pos &&
({tpos = hlist_entry(pos, typeof(*tpos),member);1;});
pos = pos->next)
#define hlist_for_each_entry_safe(tpos, pos, n, head, member)
for (pos = (head)->first;
pos && ({ n = pos->next;1;}) &&
({tpos = hlist_entry(pos, typeof(*tpos),member);1;});
pos = n)
2. 从哈希链表中的pos结点的下一个结点开始遍历
1>function:从pos结点的下一个结点进行遍历。
2>函数接口:
hlist_for_each_entry_continue(tpos ,pos, member)
tpos: 用于遍历的指针,只是它的数据类型是结构体类型而不是strut hlist_head 类型
pos: 用于遍历的指针,只是它的数据类型是strut hlist_head 类型
member: 该数据项类型定义中hlist_head成员的变量名
3>函数实现:
#define hlist_for_each_entry_continue(tpos, pos, member)
for (pos = (pos)->next;
pos &&
({tpos = hlist_entry(pos,typeof(*tpos),member);1;});
pos = pos->next)
3.从哈希链表中的pos结点的当前结点开始遍历
1>function:从当前某个结点开始进行遍历。hlist_for_entry_continue是从某个结点之后开始进行遍历。
2>函数接口:
hlist_for_each_entry_from(tpos, pos, member)
tpos: 用于遍历的指针,只是它的数据类型是结构体类型而不是strut hlist_head 类型
pos: 用于遍历的指针,只是它的数据类型是strut hlist_head 类型
member: 该数据项类型定义中hlist_head成员的变量名
3>实现
#define hlist_for_each_entry_from(tpos, pos, member)
for (; pos &&
({tpos = hlist_entry(pos,typeof(*tpos),member);1;});
pos = pos->next)