引用:https://blog.csdn.net/rl529014/article/details/51556707 感谢感谢!
1. 软件测试基本分类
一般地,我们将软件测试活动分为以下几类:黑盒测试、白盒测试、静态测试、动态测试、手动测试、自动测试等等。
黑盒测试
黑盒测试又叫功能测试、数据驱动测试或给予需求规格说明书的功能测试。这种测试注重于测试软件的功能性需求。
采用这种测试方法,测试工程师把测试对象看作一个黑盒子,不需要考虑程序内部的逻辑结构和特性,只需要依据程序的需求规格说明书,检查程序的功能是否符合它的功能说明。黑盒测试能更好更真实的从用户角度来考察被测系统的功能性需求实现情况。在软件测试的各个阶段,如单元测试、集成测试、系统测试及确认测试等阶段都发挥着重要作用。尤其在系统测试和确认测试中,其作用是其他测试方法无法取代的。
白盒测试
白盒测试又称结构测试、逻辑驱动测试或基于程序代码内部结构的测试。此时,需要深入考察程序代码的内部结构、逻辑设计等等。白盒测试需要测试工程师具备很深的软件开发工地,精通相应的开发语言,一般的软件测试工程师难以胜任该工作。
静态测试
静态测试,顾名思义,就是静态的、不执行被测对象程序代码而寻找缺陷的过程。通俗地讲,静态测试就是用眼睛看,阅读程序代码,文档资料等,与需求规格说明书中的需求进行比较,找出程序代码中设计的不合理,以及文档资料中的错误。
在进行代码的静态测试时,可以采用一些代码走查的工具,如 QA C++、C++ Test等。
动态测试
动态测试即为实际的执行被测对象的程序代码,输入事先设计好的测试用例,检查程序代码运行的结果与测试用例中设计的预期结果之间是否差异,判定实际结果与预期结果是否一致,从而检验程序的正确性、可靠性和有效性,并分析系统运行效率和健壮性等性能状况。
动态测试由四部分组成:设计测试用例、执行测试用例、分析比较输出结果、输出测试报告。
动态测试结合使用白盒测试和黑盒测试。
2. 测试方法
对于白盒测试,常用的测试方法有:语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、多重条件覆盖等等。黑盒测试较为知名的测试方法有:等价类划分、边界值分析、因果图分析、错误猜测等。本章将对这些测试方法进行一些简单的介绍。
2.1 白盒测试
白盒测试关注的是测试用例执行的程度或覆盖程序逻辑结构(源代码) 的程度。如完全的白盒测试是将程序中每条路径都执行到,然而对一个带有循环的程序来说,完全的路径测试并不切合实际。
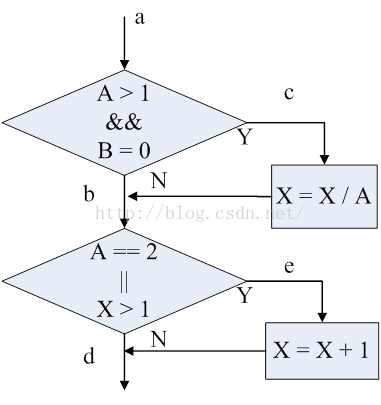
图 2‑1被测试的小程序
2.1.1 语句覆盖
如果完全从路径测试中跳出来看,那么有价值的目标似乎就是将程序中的每条语句至少执行一次。遗憾的是,这恰是合理的白盒测试中较弱的准则。图2‑1描述了这种思想。假设图2‑1 代表了一个将要进行测试的小程序,其等价的代码段如下:
Public void foo(int a, int b, int x)
{
if (a > 1 &&b == 0)
{
x = x/ a;
}
if (a == 2 || x > 1)
{
X = x +1;
}
}
通过编写单个的测试用例遍历程序路径 ace,可以执行到每一条语句。也就是说,通过在点 a 处设置 A=2,B=0,X=3,每条语句将被执行一次(实际上,X 可被赋任何值)。
遗憾的是,这个准则相当不足。举例来说,也许第一个判断应是“或”,而不是 “与” 。 如果这样, 这个错误就会发现不到。另外, 可能第二个判断应该写成 “X>0” ,这个错误也不会被发现。还有,程序中存在一条 X 未发生改变的路径(路径 abd),如果这是个错误,它也不会被发现。换句话说,语句覆盖这条准则有很大的不足,以至于它通常没有什么用处。
2.1.2 判定(分支)覆盖
判定覆盖或分支覆盖是较强一些的逻辑覆盖准则。该准则要求必须编写足够的测试用例,使得每一个判断都至少有一个为“真”和为“假”的输出结果。换句话说,也就是每条分支路径都必须至少遍历一次。分支或判定语句的例子包括switch,do-while 和 if-else 语句。
判定覆盖通常可以满足语句覆盖。由于每条语句都是在要么从分支语句开始,要么从程序入口点开始的某条子路径上,如果每条分支路径都被执行到了,那么每条语句也应该被执行到了。但是,仍然有些例外情况:
• 程序中不存在判断。
• 程序或子程序/方法有着多重入口点。只有从程序的特定入口点进入时,某条特定的语句才能执行到。
我们的探讨仅针对有两个选择的判断或分支,当程序中包含有多重选择的判断时,判定/分支覆盖准则的定义就必须有所改变。典型的例子有包含select(case)语句的 Java 程序,包含算术 (三重选择) IF 语句、计算或算术 GOTO 语句的 FORTRAN 程序,以及包含可选 GOTO 语句或 GO-TO-DEFENDING-ON 语句的 COBOL 程序。对于这些程序,判定/分支覆盖准则将所有判断的每个可能结果都至少执行一次,以及将程序或子程序的每个入口点都至少执行一次。
在图2‑1 中,两个涵盖了路径 ace 和 abd,或涵盖了路径 acd 和 abe 的测试用例就可以满足判定覆盖的要求。如果我们选择了后一种情况,两个测试用例的输入是 A=3,B=0,X=3 和 A=2,B=1,X=1。
判定覆盖是一种比语句覆盖更强的准则,但仍然相当不足。举例来说,我们仅有 50%的可能性遍历到那条 X 未发生变化的路径(也即, 仅当我们选择前一种情况) 。
如果第二个判断存在错误(例如把 X>1 写成了 X<1,那么前面例子中的两个测试用例都无法找出这个错误。
2.1.3 条件覆盖
比判定覆盖更强一些的准则是条件覆盖。在条件覆盖情况下,要编写足够的测试用例以确保将一个判断中的每个条件的所有可能的结果至少执行一次。因为,就如同判定覆盖的情况一样,这并不总是能让每条语句都执行到,因此作为对这条准则的补充就是对程序或子程序。举例来说,分支语句
DO K=0 to 50 WHILE (J+K<QUEST)
包含两种情况:K 是否小于或等干 50?以及 J+K 是否小于 QUEST? 因此,需要针对K <= 50、 K >50 (达到循环的最后一次迭代)以及J+K<QUEST、 J+K>=QUEST的情况设计测试用例。
图 2‑1 有四个条件:A>1、B=0、A=2 以及 X>1。因此需要足够的测试用例,使得在点 a 处出现 A=2、A<2、X>1 及 X<=1 的情况。有足够数量的测试用例满足此准则,用例及其遍历的路径如下所示:
1.A=2,B=0,X=4 ace
2.A=1,B=1,X=1 adb
请注意,尽管在本例中生成的测试用例数量是一样的,但条件覆盖通常还是要比判定覆盖更强一些。因为,条件覆盖可能(但并不总是这样)会使判断中的各个条件都取到两个结果(“真”和“假” ) ,而判定覆盖却做不到这一点。举例来说,在相同的分支语句
DO K=0 to 50 WHILE(J+K<QUEST)
中,存在一个两重分支(执行循环体,或者跳过循环体) 。如果使用的是判定覆盖测试,将循环从 K= 0 执行到 K = 51 即可满足该准则,但从未考虑到 WHILE子句为假的情况。如果使用的是条件覆盖准则,就需要设计一个测试用例为J+K<QUEST 产生一个为假的结果。
虽然条件覆盖准则乍看上去似乎满足判定覆盖准则,但并不总是如此。如果正在测试判断条件 IF (A&B),条件覆盖准则将要求编写两个测试用例:A为真,B为假;A 为假,B 为真。但是这并不能使 IF 语句中的 THEN 被执行到。对图2‑1 所示例子所进行的条件覆盖测试涵盖了全部判断结果,但这仅仅是偶然情况。举例来说,两个可选的测试用例:
1. A=2,B=0,X=3
2. A=1,B=1,X=1
涵盖了全部的条件结果,却仅涵盖了四个判断结果中的两个(这两个测试用例都涵盖到了路径 abe,因而不会执行第一个判断结果为真的路径,以及第二个判断结果为假的路径) 。
2.1.4 判定/条件覆盖
显然,解决上面左右为难局面的办法就是所谓的判定/条件覆盖准则。这种准则要求设计出充足的测试用例。将一个判断中的每个条件的所有可能的结果至少执行一次,将每个判断的每个条件的所有可能的结果至少执行一次,将每个判断的所有可能的结果至少执行一次,将每个入口点都至少调用一次。
判定/条件覆盖准则的一个缺点是尽管看上去所有条件的所有结果似乎都执行到了,但由于有些特定的条件会屏蔽掉其他的条件,常常并不能全部都执行到。请参见图2‑2来观察此种情况。图2‑2 中的流程图描述的是编译器将图2‑1中的程序编译生成机器代码的过程。源程序中的多重条件判断被分解成单个的判断和分支,因为大多数的机器都没有能执行多重条件判断的单独指令。那么,更为完全的测试覆盖似乎是将每个基本判断的全部可能的结果都执行到,而前两个判定覆盖的测试用例都做不到这点,它们未能执行到判断 I 中的结果为 “假”的分支, 以及判断 K 中结果为“真”的分支。
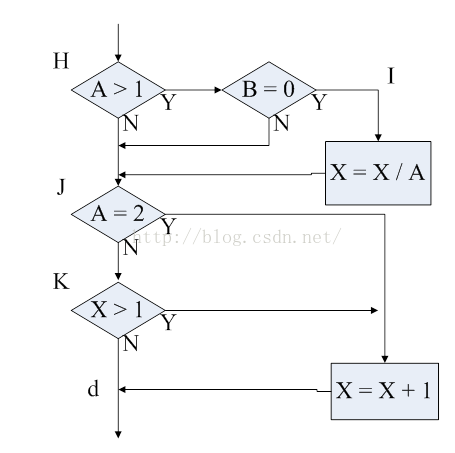
图 2‑2 图 2‑1中程序的机器码
如图2‑2所示,其中的原因是“与”和“或”表达式中某些条件的结果可能会屏蔽掉或阻碍其他条件,的判断。举例来说,如果“与”表达式中有个条件为“假”,那么就无须计算该表达式中的后续条件。 同样, 如果 “或”表达式中有个条件为 “真” ,那么后续条件也无须计算。因此,条件覆盖或判定/条件覆盖谁都不一定会发现逻辑表达式中的错误。
2.1.5 多重条件覆盖
所谓的多重条件覆盖准则能够部分解决这个问题。该准则要求编写足够多的测试用例,将每个判定中的所有可能的条件结果的组合,以及所有的入口点都至少执行一次。举例来说,考虑下面的伪代码程序;
NOTFOUND=TRUE;
DO I=1 TO TABSIZE WHILE (NOTFOUND); /*SEARCHTABLE*/
……searching logic……;
END
要测试四种情况:
1. I<=TABSIZE,并且 NOTFOUND 为真;
2. I<=TABSIZE,并且 NOTFOUND 为假(在到达表格尾部前查询指定条目) ;
3. I>TABSIZE,并且 NOTFOUND 为真(查询了整个表格,未找到指定条目) ;
4. I>TABSIZE,并且 NOTFOUND 为假(指定条目位于表格的最后位置) 。
很容易发现,满足多重条件覆盖准则的测试用例集,同样满足判定覆盖准则、条件覆盖准则以及判定/条件覆盖准则。
再次回到图2‑1中,测试用例必须覆盖以下 8 种组合:
1. A > 1, B = 0
2. A > 1, B != 0
3. A <= 1,B = 0
4. A <= 1, B != 0
5. A = 2, X > 1
6. A = 2, X <= 1
7. A != 2, X > 1
8. A != 2, X <= 1
注意,第 5 至8 组合表示了第二个 if 语句的值。由于 X可能在该 if 语句之前发生了改变,因此这个 if 语所需的值必需对程序逻辑进行回溯,以找到相对应的输入值,要测试的这 8 种组合并不一定意味着需要设计出 8 个测试用例。实际上,用 4 个测试用例就可以覆盖它们。下面是这些测试用例的输入,以及它们覆盖的组合:
A=3,B=0,X=4 覆盖组合 1,5
A=2,B=1,X=1 覆盖组合 2,6
A=1,B=0,X=2 覆盖组合 3,7
A=1,B=1,X=1 覆盖组合 4,8
图 2‑1的程序存在 4 条不同的路径,需要 4 个测试用例,这样的情况纯属巧合。事实上,这 4 个用例也没有覆盖到每条路径,路径 acd 就被遗漏掉了。
举例来说,对于如下所示的判断语句,尽管它只包舍两条路径,仍可能需要 8个测试用例:
if (x==y && length(z)==0 && FLAG)
{
j=1 ;
}
Else
{
i=1;
}
在存在循环的情况下,多重条件覆盖准则所需要的测试用例的数量通常会远远小于其路径的数量。
总的来说,对于包含每个判断只存在一种条件的程序,最简单的测试准则就是设计出足够数量的测试用例,实现:(1)将每个判断的所有结果都至少执行一次;(2)将所有的程序入口都至少调用一次,以确保全部的语句都至少执行一次。而对于包含多重条件判断的程序,最简单的测试准则是设计出足够数量的测试用例,将每个判断的所有可能的条件结果的组合,以及所有的入口点都至少执行一次(加入“可能”二字,是因为有些组合情况难以生成)。
2.1.6 路径覆盖
在以上测试用例中,我们发现漏掉了路径acd。路径覆盖则要求覆盖程序所有可能的路径,路径覆盖需要对所有可能的路径进行测试(包括循环、条件组合、分支选择等)。那么需要设计大量、复杂的测试用例,使得工作量呈指数级增长。而在有些情况下,一些执行路径是不可能被执行的。
从这个简单的例子可以看出,要想充分测试一个程序是很困难的。同时,测试条件越强,测试的代价越高。测试时应分主次,在测试代价和测试充分性之间做出平衡。
2.2 黑盒测试
2.2.1 等价划分
一个好的测试用例描述为具有相当高的可能性发现某个错误来,此外对程序的穷举输入测试是无法实现的。因此,当测试某个程序时,我们就被限制在从所有可能的输入中努力找出某个小的子集。理所当然,我们要找的子集必须是正确的,并且是可能发现最多错误的子集。确定这个子集的一种方法,就是要意识到一个精心挑选的测试用例还应具备另外两个特性:
1. 严格控制测试用例的增加,减少为达到“合理测试”的某些既定目标而必须设计的其他测试用例的数量。
2. 它覆盖了大部分其他可能的测试用例。也就是说,它会告诉我们,使用或不使用这个特定的输入集合,哪些错误会被发现,哪些会被遗漏掉。
虽然这两个特性看起来很相似,但描述的却是截然不同的两种思想。第一个特性意味着,每个测试用例都必须体现尽可能多的不同的输入情况,以使最大限度地减少测试所需的全部用例的数量。而第二个特性意味着应该尽量将程序输入范围进行划分,将其划分为有限数量的等价类,这样就可以合理地假设(但是,显然不能绝对肯定)测试每个等价类的代表性数据等同于测试该类的其他任何数据。也就是说,如果等价类的某个测试用例发现了某个错误,该等价类的其他用例也应该能发现同样的错误。相反,如果测试用例没能发现错误,那么我们可以预计,该等价类中的其他测试用例不会出现在其他等价类中,因为等价类是相互交迭的。
这两种思想形成了称为等价划分的黑盒测试方法。第二种思想可以用来设计一个“令人感兴趣的”输入条件集合以供测试,而第一个思想可以随后用来设计涵盖这些状态的一个最小测试用例集。
使用等价划分方法设计测试用例主要有两个步骤:(1)确定等价类; (2)生成测试用例。
表2‑1等价类列举表
|
输入条件 |
有效等价类 |
无效等价类 |
1.确定等价类
确定等价类是选取每一个输入条件(通常是规格说明中的一个句子或短语)并将其划分为两个或更多的组。可以使用表2‑1中的表格来进行划分。注意,我们确定了两类等价类:有效等价类代表对程序的有效输入,而无效等价类代表的则是其他任何可能的输入条件(即不正确的输入值)。这样,我们遵循了测试原则,即要注意无效和未预料到的输入情况。
在给定了输入或外部条件之后,确定等价类大体上是一个启发式的过程。下面给出了一些指导原则:
1. 如果输入条件规定了一个取值范围(例如,“数量可以是从1到999”),那么就应确定出一个有效等价类 (1<数量<999 ) ,以及两个无效等价类 (数量<1,数量>999) 。
|
输入条件 |
有效等价类 |
无效等价类 |
|
取值范围 |
1<数量<999 |
数量<1,数量>999 |
2. 如果输入条件规定了取值的个数(例如,“汽车可登记一至六名车主”),那么就应确定出一个有效等价类和两个无效等价类(没有车主,或车主多于六个)。
|
输入条件 |
有效等价类 |
无效等价类 |
|
取值个数 |
1至六名车主 |
没有车主,车主多于六个 |
3. 如果输入条件规定了一个输入值的集合,而且有理由认为程序会对每个值进行不同处理(例如,“交通工具的类型必须是公共汽车、卡车、出租车、火车或摩托车” ) ,那么就应为每个输入值确定一个有效等价类和一个无效等价类(例如,“拖车” ) 。
|
输入条件 |
有效等价类 |
无效等价类 |
|
输入值集合 |
公共汽车,卡车,出租车,火车,摩托车 |
拖车 |
4. 如果存在输入条件规定了“必须是”的情况,例如“标识符的第一个字符必须是字母”,那么就应确定一个有效等价类(首字符是字母)和一个无效等价类(首字符不是字母) 。
|
输入条件 |
有效等价类 |
无效等价类 |
|
第一个字符 |
首字符是字母 |
首字符不是字母 |
如果有任何理由可以认为程序并未等同地处理等价类中的元素,那么应该将这个等价类再划分为小一些的等价类。
2.生成测试用例
第二步是使用等价类来生成测试用例,我们以上述第一个例子来说明,其过程如下:
1. 为每个等价类设置一个不同的编号。
2. 编写新的测试用例,尽可能多地覆盖那些尚未被涵盖的有效等价类,直到所有的有效等价类都被测试用例所覆盖(包含进去)。
3. 编写新的用例,覆盖一个且仅一个尚未被覆盖的无效等价类,直到所有的无效等价类都被测试用例所覆盖。
用单个测试用例覆盖无效等价类,是因为某些特定的输入错误检查可能会屏蔽或取代其他输入错误检查。举例来说,如果规格说明规定了“请输入书籍类型(硬皮、软皮或活页)及数量(l~999 )”,代表两个错误输入(书籍类型错误,数量错误)的测试用例“XYZ 0”,很可能不会执行对数量的检查,因为程序也许会提示“XYZ 是未知的书籍类型”,就不检查输入的其余部分了。
这里将上述的第4个例子进行一下扩展,然后进行示范说明如何用等价类划分的思想来设计测试用例:
规定标识符的第一个字符必须是字母,标识符只能使用字母、数字和下划线。
第一步:划分等价类,为每一个等价类编号。
|
输入条件 |
有效等价类 |
无效等价类 |
|
第一个字符 |
首字符是字母(1) |
首字符不是字母(2) |
|
字符限制 |
仅使用字母、数字和下划线(3) |
使用了其他字符(4) |
第二步:设计测试用例,覆盖所有有效等价类,用尽可能少的用例覆盖最多的有效等价类。
测试用例:Test_1 覆盖(1)(3)
第三步:设计测试用例,覆盖所有无效等价类。每新增一个测试用例,只覆盖一个无效等价类。
测试用例:123test 覆盖(2)
测试用例:Test#¥ 覆盖(4)
2.2.2 边界值分析
经验证明,考虑了边界条件的测试用例与其他没有考虑边界条件的测试用例相比,具有更高的测试回报率。所谓边界条件,是指输入和输出等价类中那些恰好处于边界、或超过边界、或在边界以下的状态。边界值分析方法与等价划分方法存在两方面的不同:
1. 与从等价类中挑选出任意一个元素作为代表不同,边界值分析需要选择一个或多个元素,以便等价类的每个边界都经过一次测试。
比如要求输入职工年龄,规定输入为18 – 45。根据等价类划分思想,一个有效等价类:18<= 年龄 <=45 ,两个无效等价类:年龄<18 和 年龄>45。这样选取 10 ,30 ,50即可满足覆盖。但是等价类的思想没有从边界值方面来分析问题,从边界值角度分析,我们就会再添加17、18、19 、44、45、46这样的边界值。
2. 与仅仅关注输入条件(输入空间)不同,还需要考虑从结果空间(输出等价类)设计测试用例。
比如ATM机取款手续费为取款额%1,最低2元,最高50元。从输出等价类来考虑边界值,就要设计用例来测试手续费会不会低于2元,会不会高于50元。
很难提供一份如何进行边界值分析的“详细说明’,因为这种方法需要一定程度的创造性,以及对问题采取一定程度的特殊处理办法(因此,就像测试的许多其他方面一样,这更多的是项智力工作,并非其他的什么)。
2.2.3 因果图
边界值分析和等价划分的一个弱点是未对输入条件的组合进行分析。边界值测试不一定能检查出此类错误。
对输入组合进行测试并不是简单的事情,因为即使对输入条件进行了等价划分,这些组合的数量也是个天文数字。如果在选择输入条件的子集时没有采用一个系统的方法,很可能选择出一个任意的输入条件子集, 这样会使测试没有什么成效。
因果图有助于用一个系统的方法选择出高效的测试用例集。它还有一个额外的好处,就是可以指出规格说明的不完整性和不明确之处。
这里不对因果图这种方法进行详细介绍,有兴趣的同事可以查阅《软件测试的艺术》相关章节。
2.2.4 错误猜测
常常可以看到这种情况,有些人似乎天生就是测试的能手。这些人没有用到任何特殊的方法(比如对因果图进行边界值分析),却似乎有着发现错误的诀窍。
对此的一个解释是这些人更多是在下意识中,实践着一种称为错误猜测的测试用例设计技术。接到具体的程序之后,他们利用直觉和经验猜测出错的可能类型,然后编写测试用例来暴露这些错误。
由于错误猜测主要是一项依赖于直觉的非正规的过程,因此很难描述出这种方法的规程。其基本思想是列举出可能犯的错误或错误易发情况的清单,然后依据清单来编写测试用例。例如,程序的输入中出现 0 这个值就是一种错误易发情况。因此,可以编写测试用例,检查特定的输入值中有 0,或特定的输出值被强制为 0 的情况。同样, 在出现输入或输出的数量不定的地方 (如某个被搜索列表的条目数量)。数量为“没有”和“一个” (例如空列表,仅包含一个条目的列表)也是错误易发情况。另一个思想是,在阅读规格说明时联系程序员可能做的假设来确定测试用例(即规格说明中的一些内容会被忽略,要么是由于偶然因素,要么是程序员认为其显而易见)。