linux系统常见日志采集
系统日志
/var/log/messages
安全日志
/var/log/secure
审计日志
/var/log/audit/audit.log
组件介绍
filebeat采集日志,然后发送到消息队列kafka,然后logstash去获取,利用filter功能过滤格式,然后存储到elasticsearch中,最后通过kibana展示。
filebeat
轻量级的日志收集工具,本地文件的日志数据采集器。 作为服务器上的代理安装,Filebeat监视日志目录或特定日志文件,并将它们转发给kafka或Elasticsearch、Logstash等。
kafka
kafka使用Scala语言编写,Kafka是一个分布式、分区的、多副本的、多订阅者的消息中间件,在ELK日志系统中用于日志的暂存,。
logstash
用于对日志进行收集、过滤,对数据进行格式化处理,并将所搜集的日志传输到相关系统进行存储。Logstash是用Ruby语言开发的,由数据输入端、过滤器和输出端3部分组成。其中数据输入端可以从数据源采集数据,常见的数据源如Kafka等;过滤器是数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式;数据输出端是将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。
elasticsearch
ElasticSearch是一个基于Lucene构建的开源的分布式的搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。ELK中主要用于数据的永久性存储。
kibana
一款针对Elasticsearch开源分析以及可视化平台,使用node.js开发,可以用来搜索,展示存储在Elasticsearch中的数据。同时提供了丰富的图标模板,只需要通过简单的配置就可以方便的进行高级数据分析和绘制各种图表。在Kibana界面可以通过拖拽各个图表进行排版,同时Kibana也支持条件查询、过滤检索等,还支持导入相应插件的仪表盘。
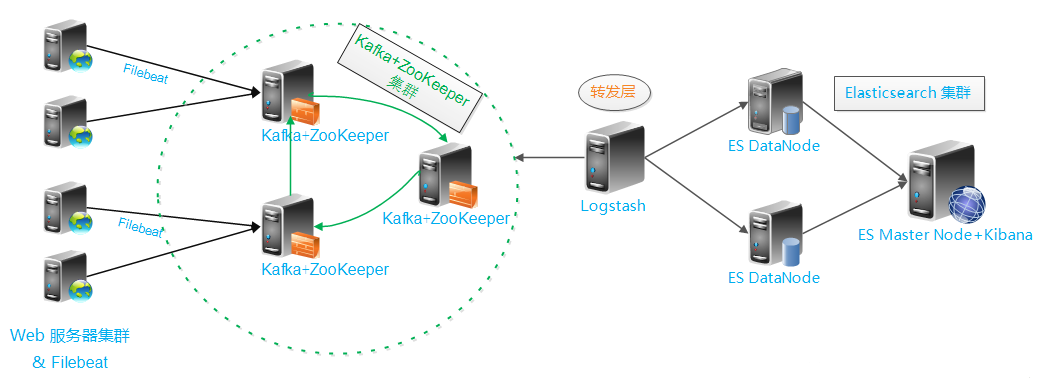
架构图
日志的处理流程为:filebeat --> kafka --> logstash --> elasticsearch。
架构图如下所示:
配置示例
filebeat配置
filebeat从日志文件读写日志,输出到kafka。
filebeat.inputs:
#------- 系统相关日志 ----------
- type: log
paths:
- /var/log/messages*
fields:
logtopic: messages
fields_under_root: true
- type: log
paths:
- /var/log/secure*
fields:
logtopic: secure
fields_under_root: true
- type: log
paths:
- /var/log/audit/audit.log*
fields:
logtopic: audit
fields_under_root: true
- type: log
paths:
- /var/log/history.log*
fields:
logtopic: history
fields_under_root: true
#-----------tomcat日志 ----------
- type: log
paths:
- /opt/tomcat/logs/catalina.out*
fields:
logtopic: tomcat-catalina-log
fields_under_root: true
multiline.pattern: ^[
multiline.negate: true
multiline.match: after
- type: log
json.keys_under_root: true
json.overwrite_keys: true
paths:
- /opt/tomcat/logs/tomcat_access_log.log
fields:
logtopic: tomcat-access-log
fields_under_root: true
#-----------apache日志 ----------
- type: log
json.keys_under_root: true
json.overwrite_keys: true
paths:
- /var/log/httpd/access_log
fields:
logtopic: apache-access-log
fields_under_root: true
#-----------nginx日志 ----------
- type: log
json.keys_under_root: true
json.overwrite_keys: true
paths:
- /usr/local/nginx/logs/access.log
fields:
logtopic: nginx-access-log
fields_under_root: true
- type: log
paths:
- /usr/local/nginx/logs/error.log
fields:
logtopic: nginx-error-log
fields_under_root: true
#-----------mysql日志 ----------
- type: log
paths:
- /alidata/mysql/logs/mysql-slow.log
fields:
logtopic: mysql-slow-log
fields_under_root: true
multiline.pattern: '^(# Time)'
multiline.negate: true
multiline.match: after
- type: log
paths:
- /var/log/mysqld-error.log
fields:
logtopic: mysqld-error-log
fields_under_root: true
#msyql的binlog需先使用maxwell工具输出为 json格式的file,也可以直接输出到kafka
- type: log
json.keys_under_root: true
json.overwrite_keys: true
paths:
- /alidata/mysql/logs/mysql_binlog_data.log
fields:
logtopic: mysqld-binlog
fields_under_root: true
#------- 全局设置 ------------
fields:
host: 主机IP
fields_under_root: true
#-------输出到kafka ----------
output.kafka:
enabled: true
hosts: ["kafka_ip:port"]
topic: "elk-%{[logtopic]}"
partition.round_robin:
reachable_only: true
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logstash配置
logstash作为消费者从kafka消费日志,经过格式化处理后输出到elasticsearch。
input {
kafka {
topics_pattern => "elk-.*"
bootstrap_servers => "x.x.x.x:9092"
auto_offset_rest => "latest"
codec => json {
charset => "UTF-8"
}
group_id => "xxxxx"
client_id => "xxxx"
consumer_threads => 5
decorate_events => true //此属性会将当前topic、offset、group、partition等信息也带到message中
}
}
filter{
if[logtopic] == "tomcatlog"{
grok{
........
}
}
if[logtopic] == "history"{
grok{
........
}
}
}
output {
elasticsearch {
hosts => ["x.x.x.x:9200"]
#index => "elk-%{logtopic}-%{+YYYY.MM.dd}"
index => "%{[@metadata][kafka][topic]}-%{+YYYY.MM.dd}"
}
#stdout { codec => rubydebug }
}