堆Heap
二叉堆 Binary Heap
满二叉树:除了叶子节点,其他所有节点 左右孩子均不为空
性质:
-
二叉堆是一棵完全二叉树 ( 若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数(x层:2^(x-1)个),第 h 层所有的结点都连续集中在最左边,这就是完全二叉树 )

-
二叉堆是 最大堆(堆中某个节点的值总是不大于其父节点的值)。即根节点的元素是最大的。(从堆中去除元素只能取堆顶的元素)
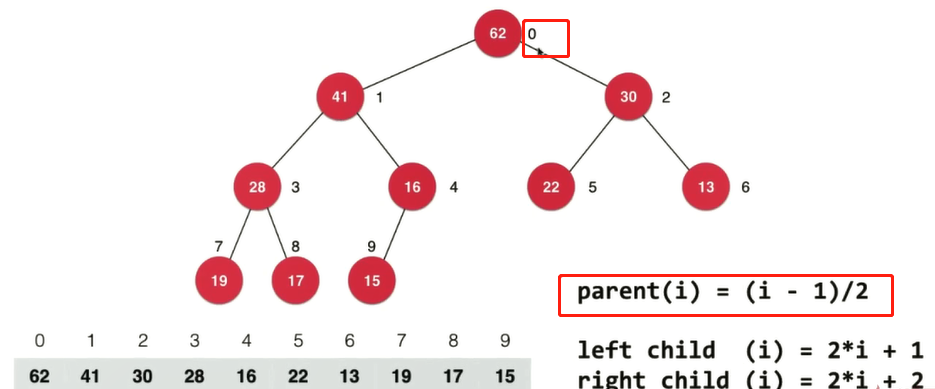
可以将这个 二叉堆(最大堆) 用 数组 来表示。一层一层元素从左往右放入数组。
1. 最大堆的实现:
用 数组 来实现
private Array<E> data;
public MaxHeap(int capacity){
data = new Array<>(capacity);
}
//将数组直接传入转换为最大堆
public MaxHeap(E[] arr){
data = new Array<>(arr);
for(int i = parent(arr.length - 1) ; i >= 0 ; i --)
siftDown(i);
}
// 返回堆中的元素个数
public int size(){
return data.getSize();
}
// 返回一个布尔值, 表示堆中是否为空
public boolean isEmpty(){
return data.isEmpty();
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的父亲节点的索引
private int parent(int index){
if(index == 0)
throw new IllegalArgumentException("index-0 doesn't have parent.");
return (index - 1) / 2;
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引
private int leftChild(int index){
return index * 2 + 1;
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引
private int rightChild(int index){
return index * 2 + 2;
}
其中 [siftDown()](#下沉 siftDown()) 函数 见下面解释 。
2. 添加元素 O(logn)
add() 方法。
在堆中添加元素,应该把元素添加在最后面,即相当于数组末端添加。
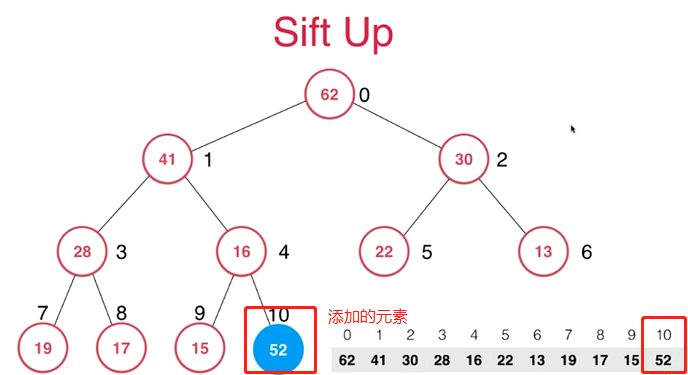
上浮 siftUp()
添加之后,需要进行判断排序。调用 siftUp() 函数来上浮:
-
先将元素添加到 堆 的最后。可知,这里的最后,即为堆最深一层第一个为空的节点。
-
开始讲该节点上浮,进行循环判断。
-
k > 0 即节点未到堆顶,并且 父节点 小于 该节点 的值 时 ,交换 位置
-
以此循环
// 向堆中添加元素 public void add(E e){ data.addLast(e); siftUp(data.getSize() - 1); } private void siftUp(int k){ // while(k > 0 && data.get(parent(k)).compareTo(data.get(k)) < 0 ){ data.swap(k, parent(k)); k = parent(k); } }
3. 堆元素的取出 O(logn)
extract() 。只取堆顶最大的元素。
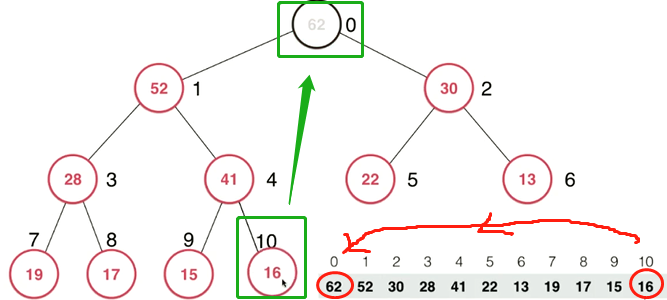
思路:
- 将堆最后面的那个元素移到堆顶,保持完全二叉树的状态不变;
- 将这个完全二叉树变成最大堆。用堆顶元素和左右孩子进行比较,如果左右孩子更大的元素比该堆顶元素还大,就交换位置;
- 循环下沉,与左右孩子比较直到左右孩子均小于这个元素。
下沉 siftDown()
// 看堆中的最大元素
public E findMax(){
if(data.getSize() == 0)
throw new IllegalArgumentException("Can not findMax when heap is empty.");
return data.get(0);
}
// 取出堆中最大元素
public E extractMax(){
E ret = findMax();
data.swap(0, data.getSize() - 1);
data.removeLast();
siftDown(0);
return ret;
}
//下沉
private void siftDown(int k){
//节点值未超出最大值
while(leftChild(k) < data.getSize()){
int j = leftChild(k); // 在此轮循环中,data[k]和data[j]交换位置
if( j + 1 < data.getSize() &&
data.get(j + 1).compareTo(data.get(j)) > 0 )
j ++;
// data[j] 是 leftChild 和 rightChild 中的最大值
if(data.get(k).compareTo(data.get(j)) >= 0 )
break;
data.swap(k, j);
k = j;
}
}
4. heapify O(n)
将任意 数组 整理成 堆 的形状。
本例在构造函数里用。
如果采用一个一个 add(), 那时间复杂度就是 O(nlogn)
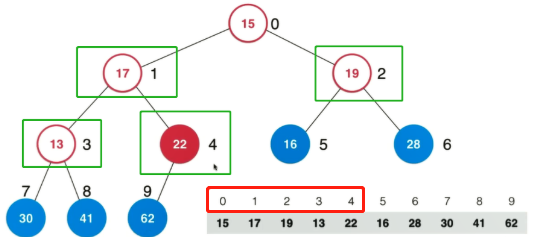
采用以下方法:从倒数第二层开始,时间复杂度 O(n)
思路:
-
先把数组顺序当成完全二叉树
-
从最后一个非叶子节点
int i = parent(arr.length - 1)开始,按坐标递减,逐层往上对所有元素进行siftDown()
public MaxHeap(E[] arr){
data = new Array<>(arr);
//
for(int i = parent(arr.length - 1) ; i >= 0 ; i --)
siftDown(i);
}
5. replace
取出最大元素后,放入一个新元素。
实现:
可以直接将堆顶元素替换以后Sift Down,一次O(logn)的操作
//取出堆中的最大元素,并且替换成元素e
public E replace(E e){
E ret = findMax();
data.set(0, e);
siftDown(0);
return ret;
}
优先队列

public class PriorityQueue<E extends Comparable<E>> implements Queue<E>
继承 Comparable< E > 类,实现compareTo() 方法。 来进行优先级的比较。
对于一个最大堆来说,堆顶是优先级最高的元素。元素越大,优先级越高;相反,最小堆,元素越小,优先级越高
这里用堆来实现的。
最大堆和最小堆实现 ,compareTo() 方法将返回相反的值


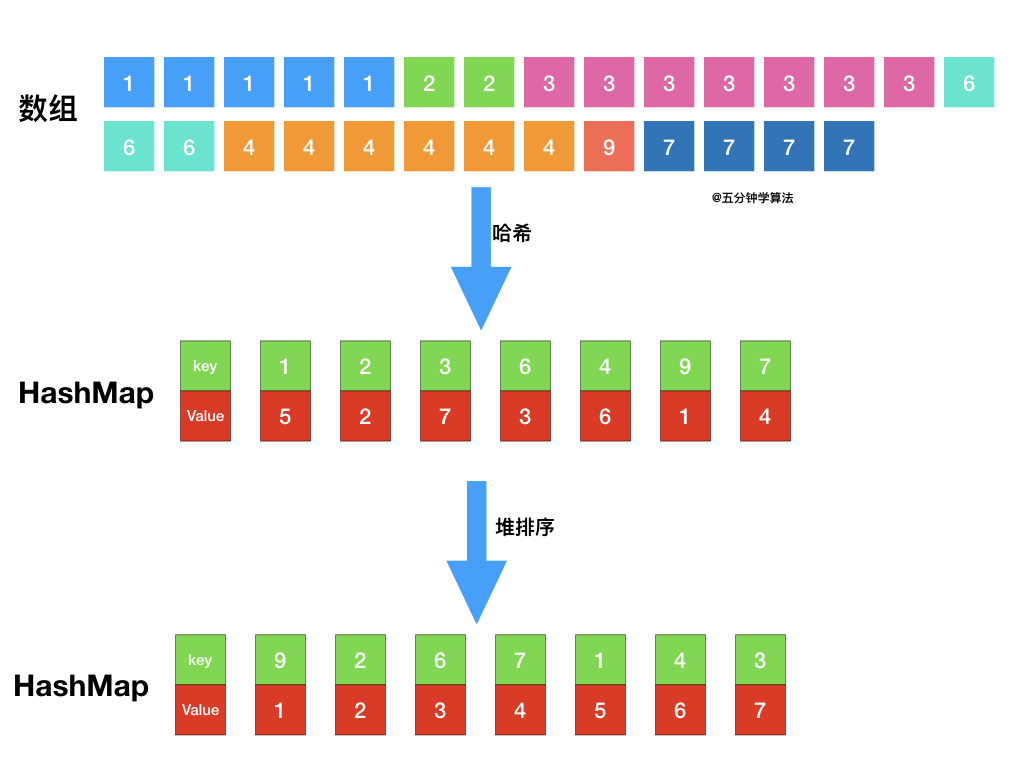
topK 问题
LeetCode347
题目最终需要返回的是前 kk 个频率最大的元素,可以想到借助堆这种数据结构,对于 kk 频率之后的元素不用再去处理,进一步优化时间复杂度。
具体操作为:
- 借助 哈希表 来建立数字和其出现次数的映射,遍历一遍数组统计元素的频率
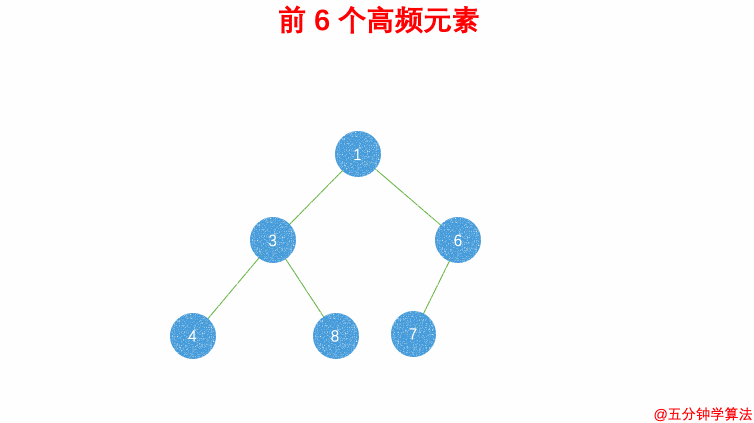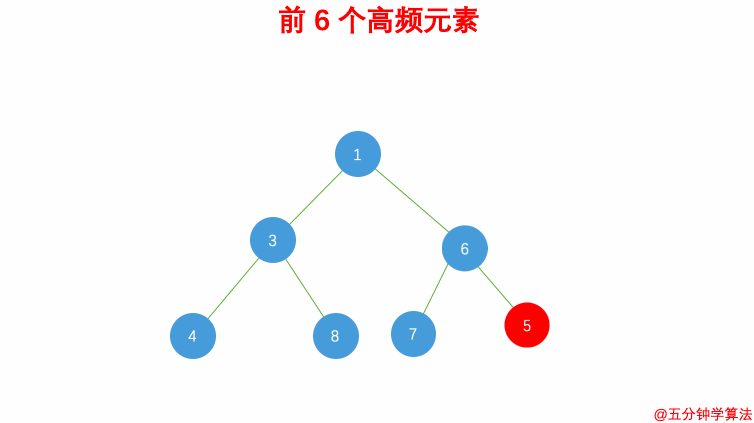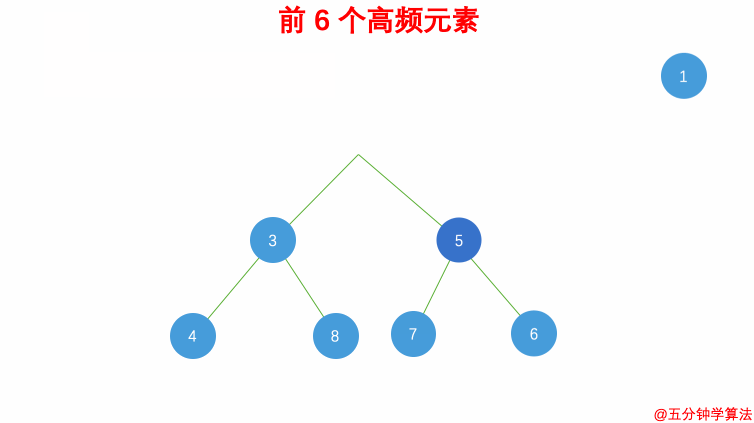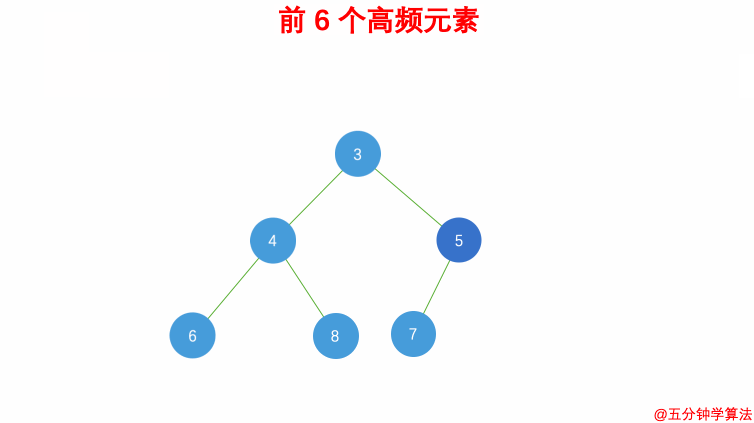
- 维护一个元素数目为 k 的最小堆
- 每次都将新的元素与堆顶元素(堆中频率最小的元素)进行比较
- 如果新的元素的频率比堆顶端的元素大,则弹出堆顶端的元素,将新的元素添加进堆中
- 最终,堆中的 kk 个元素即为前 kk 个高频元素
扩展:
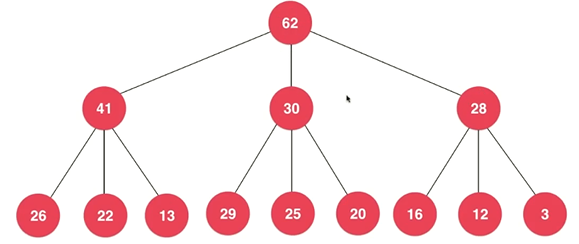
1. d 叉堆 (d-aray heap) :
2. 索引堆:
3. 二项堆:
4. 斐波那契堆:
5. 广义队列
栈,也可以看做是队列
普通队列, 优先队列, 随机队列