简述
IO操作不外乎读和写,但是不同场景对读写有不同的需求,例如网络中同时监控多个文件句柄,例如关键数据希望一路刷到存储设备而不是扔到cache就返回。
怎么读,怎么写,等不等结果返回,是否等获取到数据才发返回,组成了不同的IO模型,分别适用于不同的场景。
根据同步与异步,阻塞与非阻塞,可以把IO模型如下分类:
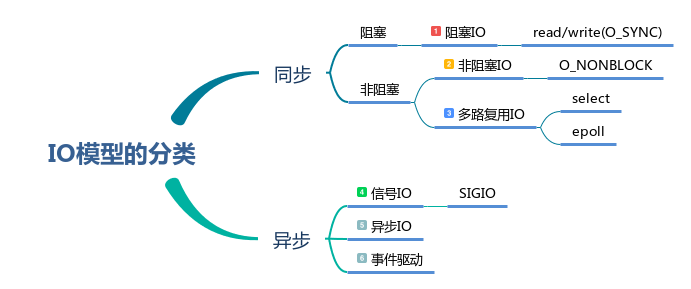
同步/异步与阻塞/非阻塞怎么理解呢?
同步与异步,就是IO发起人是否等待数据操作结束。发起一次IO请求后,发起IO的进程死等操作结束才继续往下跑,就是同步。发起一次IO请求后,不等结束直接往下跑,就是异步。
阻塞与非阻塞,就是没有数据时是否等到有数据才返回。如果没有数据,就让IO进程干等,直到有数据再返回,就是阻塞。如果看到没有数据,直接就返回了,就是非阻塞。
什么情况下会没有数据呢?一个文件就这么大,除非读到文件末尾了,不然怎么会说没有数据呢?实际上,阻塞与非阻塞并不指磁盘上常规的文件读写,而是指socket或者pipe之类的特殊文件。这些特殊文件并没有明确意义上的大小,就是说,理论上他们的数据是无限大的,只要有人往里面写数据,你就能无限读出数据。这种特殊文件有数据的前提,就是有人往里面”灌“数据。如果你读的太快,别人写得太慢,就会出现池子里面没有数据的情况。这情况并不表示文件读到末端了,只表示暂时还没有数据。这时候你等呢?还是不等呢?这就是阻塞与非阻塞。
如果是同步/异步是IO发起人是否主动想等待,阻塞/非阻塞就是没有数据时读是否被动等待。
本文并不会严格按上图依次介绍6种IO模型,相信网上有一大堆的资料。本文尝试从常规读写、多路复用的2个常用场景介绍IO模型。
上图中的信号IO,需要内核在某个时机向用户空间传递SIGIO信号,且用户空间在捕抓到此信号后进行IO处理。这做法并不常见,本文不会展开介绍。且由于是需要被动通知后才会执行IO操作,因此被我归类为异步IO。
上图中的事件驱动依赖于某些特定的库。其原理类似于为某些事件注册钩子函数,由库函数实现事件监控。在事件触发时调用钩子函数解决。这些函数库屏蔽了平台之间的差异,例如Linux中通过epoll()来监控多个fd。不同库有不同的使用方法,本文也不会展开介绍。
常规read()和write()
读操作
/* 同步阻塞 */
fd = open("./test.txt", O_RDONLY); // 常规文件
ret = read(fd, buf, len);
/* 同步非阻塞 */
int fds[2];
ret = pipe2(fds, O_NONBLOCK); // 无名管道
ret = read(fds[0], buf, len);
/* 同步非阻塞 */
fd = open("./fifo", O_RDONLY | O_NONBLOCK); // 有名管道
ret = read(fd, buf, len);
在大多数场景下,我们系统调用read()正确返回时就表示已经读到数据了,此次的IO操作已经结束了。毫无疑问,大多数情况下的读操作,都是同步的。
是否要阻塞,取决于open()时是否有O_NONBLOCK参数。
总的来说,我们系统调用read(),除非指定O_NONBLOCK,否则都是同步且阻塞的。
写操作
/* 异步 */
fd = open("./test.txt", O_WRONLY);
ret = write(fd, buf, len);
/* 同步 */
fd = open("./test.txt", O_WRONLY | O_SYNC);
ret = write(fd, buf, len);
阻塞与非阻塞主要针对读数据,写数据主要区分同步还是异步
由于Linux的IO栈中,有专门为IO准备的Cache层。在正常情况下,写操作只是把数据直接扔到了Cache就返回了,此时数据并没回刷到磁盘。要不等到系统回刷线程主动回刷,要不应用主动调用fsync(),否则数据一直都在Cache层,此时掉电数据就丢了。
写操作是同步还是异步,主要看open()时,是否带O_SYNC参数。带O_SYNC就是同步写,否则就是异步写。
本文开头就提到,同步/异步是IO发起人是否主动想等待IO结束,这里的写IO结束,指的是数据完全写入到磁盘,而非write()返回。
在没有O_SYNC情况下,数据只是写到了Cache,需要内核线程定期回刷,所以此时的write是并没有结束的,因此是异步的。相反,如果有O_SYNC,write()操作会一直等到数据完全写入到磁盘后再返回,所以是同步的。
从写性能角度来说,异步写会优于同步写。由内核IO调度算法,对写请求进行合并与排序,再一次性写入,效率绝对高于东一块西一块的随机写。因此,除非是担心掉电丢失的关键数据,否则建议使用异步写
多路复用
多路复用常用于网络开发,例如每个客户端由一个socket与服务器进行远程通信,此时这个服务程序需要同时监控多个socket,为了避免资源损耗和提高响应速率,就会使用多路复用。
多路复用是怎么一回事呢?我们假设一下有100个socket,在某一时间可能只有个别socket是有数据的,即客户端向服务端发送的请求数据。此时服务程序怎么监控这100个socket,找出有数据的socket,并做出响应?有一种做法,就是非阻塞读每个socket,没数据直接返回读下一个,有数据(请求)就响应,以此实现轮询。还有一种做法,创建100个进程/线程,每个线程,进程对应一个socket。
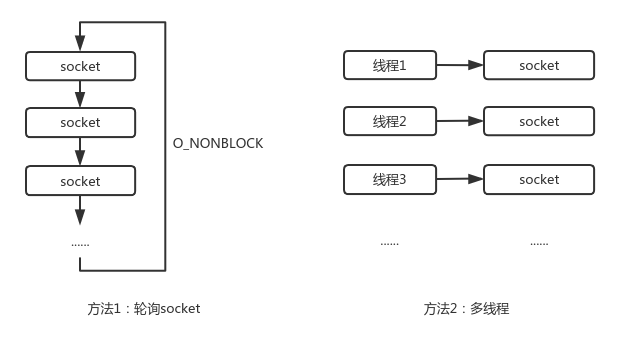
对少量的文件还行,如果文件数量一多,数百个,上千个socket逐一轮询,或者创建上千个线程,这效率得多低啊。可不可以批量等待,当哪怕有一个socket有数据时,内核直接告诉应用那个socket来数据了?可以!这就是内核支持的多路复用的系统调用select()和epoll()
/* select 函数原型 */
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
/* epoll 函数原型 */
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
他们原理大抵相似:
- 创建一个文件句柄集合,把要监视的文件句柄按顺序整合到一起
- 在有数据时置位对应的标识后返回
- 应用通过检查标识就可以知道是哪个socket有数据了,此时读socket即可直接获取数据
具体的使用方法不在这里详细介绍,网上有总多资料,可以参考《UNIX环境高级编程》。
本文顺便记录下select()与epoll()的优缺点对比:
select()
- 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
- 每次调用select,都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
- select支持的文件描述符数量太小了,默认是1024
epoll()
- epoll不仅仅一个函数,而是切分为3个函数,使得监控新的fd时,不需要拷贝所有的fd集合,只需要拷贝新的fd到内核即可。
- epoll采取回调的形式,当某个fd就绪了,就会调用回调,而在回调中,把就绪的fd加入就绪链表
- epoll没有数量,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048
可以发现,epoll()是对select()存在的问题进行针对性的解决。