在 hankcs 大神开源的HanLP里面提供了很多分词算法,其中有一个维特比算法分词,于是查了一些资料发现:维特比算法用来求解隐马尔可夫模型的第二个问题:给定一个模型和某个特定的输出序列,找到最可能产生这个输出序列的状态序列---参考《数学之美 隐马尔可夫模型 章节》
于是就寻找各种隐马模型的资料,发现了很多写得好的文章,自己就没有必要造一些质量差的轮子了……^~^
本文就是在上面两篇文章的基础上,记录一下 前向算法 的实现细节,毕竟前向算法和维特比算法一样,都有着动态规划的思想在里面。
引用原博文中的定义:
对于HMM模型,首先我们假设Q是隐藏状态的集合,V是观测状态的集合:
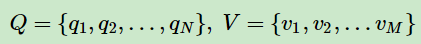
也即:某个隐藏状态只能是集合Q中的某个元素,Q一共有N个元素,也即:假设一共有N个隐藏状态。同理,一共有M个观测状态。
对于一个长度为T的序列,用 I 表示状态序列,用 O 表示观察序列:
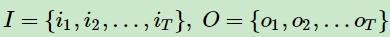
首先解释一下状态转换概率aij,在 t 时刻隐藏状态 it 取值为qi,经过状态转换,在 t+1 时刻 it+1 变成了 qj
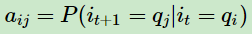 (其中 qi 和 qj 都是 隐藏状态集合Q 中的元素)
(其中 qi 和 qj 都是 隐藏状态集合Q 中的元素)
从状态转换概率ai,j可看出:它是一个条件概率,t+1时刻的状态 只与 t 时刻的状态有关。这个就是齐次马尔可夫链假设。
由于一共有N个隐藏状态,每个隐藏状态之间都可能相互转换,因此状态转换矩阵A 是一个 N*N维的矩阵。
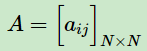
再解释一下观测状态概率bj(k) 它表示 隐藏状态 qj 生成 观测状态 vk 的概率。根据 观测独立性假设:任意时刻的观察状态只仅仅依赖于当前时刻的隐藏状态。即:t 时刻观测状态ot的取值,只与 t时刻 的隐藏状态 it 的取值有关。隐藏状态 it 取值为qj 时,观测序列ot 取值为vk 的概率用 bj(k) 表示。
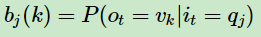
因为,对于隐藏状态集合Q里面任何一个隐藏状态qj ,它都以一定的概率生成一个观测序列vk
由于一共有N个隐藏状态,一共有M个观测状态。故生成概率的矩阵B 是一个N*M维的矩阵。

另外,再加上隐藏状态的初始分布∏,就构成了隐马尔可夫模型了。
文章第三小节中还举了个HMM模型的示例:从盒子中取球。
从盒子中取出来的球是红色的,还是白色的,取出来的球是我们看到的结果,也即观测序列。它为:O={红,白,红}
而{盒子1,盒子2,盒子3}则是隐藏序列。球是从盒子中产生的,比如说:对于盒子1而言,它有可能产生所有的观测序列:红 或者 白;产生 红球的概率为0.5,产生白球的概率也为0.5
文章中第四小节讲了观测序列的生成过程,首先由初始状态概率分布产生 第1时刻 的隐藏状态,这一步相当于:首先从哪个盒子中拿球
然后一个循环从1到T:知道了从哪个盒子中取球后,取出来的球是红色还是白色?这个就是 由隐藏状态 it 生成 观测状态 ot 的过程。
接下来,隐藏状态按照 状态转换矩阵 转换到下一个隐藏状态,用图画出来就是下面这样:
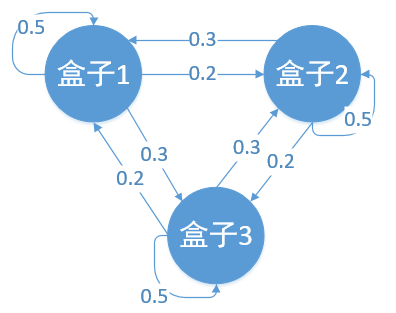
然后,下一个隐藏状态 再 按照 观测状态概率矩阵 产生 观测序列。
总之:某个盒子 相当于 一个隐藏状态,产生的一个 红球或者白球相当于 一个观测序列
文中第5小节介绍了HMM模型的三个问题:
第一个是评估观察序列的概率。也就是这篇文章:隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
因此,我就接着这篇文章隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 来记录一下我对前向算法的理解。
我们有了隐马尔可夫模型,用λ来表示,现在给定一个观测序列O,要求解观测序列O在 λ 下的概率P(O|λ)
有两种求解方法:第一种是暴力法,如下:
对于任意一个隐藏序列 I,出现的概率是:
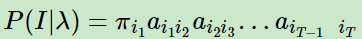
为什么呢?这个公式描述的是:
πi1 是初始隐藏状态分布概率值,以πi1 概率 选择了某个隐藏状态qi1,然后,经过状态转移概率ai1,i2 从隐藏状态qi1 转移到了qi2
由于长度为T,经转移概率 不断地转换:从隐藏状态 qi2 经转移概率 ai2,i3 转换到了 qi3……最终产生了 T个隐藏状态。
那对于一个长度为T的 隐藏序列,它的取值一共有多少种呢?前面提到:隐藏状态集合Q的大小是N,故一共有 NT 种不同的隐藏序列!
现在有了隐藏序列 I ,在这个隐藏序列 I 下,观察序列 O={o1,o2,……oT} 出现的概率是:
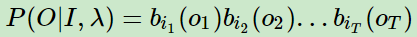
为什么呢?
根据:观测独立性假设,任意时刻的观察序列只依赖于当前时刻的隐藏序列。那么 隐藏状态 qi1 产生 观测状态o1 的概率为:bi1(o1) ,这正是 生成概率矩阵干的事儿。
根据概率论中的乘法原理:把所有的这些概率乘起来,就是P(O|I,λ)
再根据贝叶斯公式:P(A,B)=P(B)*P(A|B)
(A,B) 相当于 (O,I | λ)
B相当于 (I | λ)
A|B 相当于 (O| I,λ)
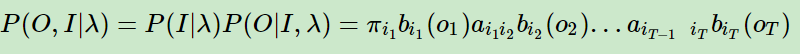
而这就是在条件λ下 关于 O 和 I 的联合概率分布。有了联合概率分布,通过对 I 求和,得到边缘概率分布P(O|λ) 就是隐马尔可夫模型第一个问题的解。
【隐马尔可夫模型第一个问题定义:给定一个HMM模型,计算某个特定的输出序列的概率】
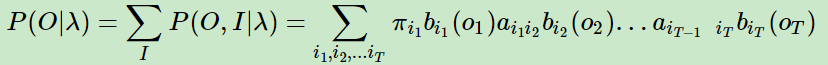
由于一共有NT种隐藏序列,上面式子两两相乘,一共有 (2T-1)*NT 乘法操作,故时间复杂度O(TNT)
可以看到,暴力法是个指数级复杂度算法。因此,前向算法 就出场了。
在使用前向算法求解HMM的观测序列概率时,先定义了 前向概率αt(i):
在隐马模型λ下,定义时刻 t 的隐藏状态为qi 观测序列为o1 o2 ...ot 的概率如下:

其实我这里有个关于前向概率和后向概率的疑问:前向概率关于 t 时刻的隐藏状态qi是联合概率,但后向概率 关于时刻t的隐藏状态qi是条件概率。好不,不管了,接着说。
由于前向算法是一个动态规划算法,而动态规划讲究:将原问题分解成 规模更小的子问题。怎么分解的呢?通俗地讲,就是通过递归表达式分解的,这个递归表达式在动态规划中称为状态转移方程。这也是这篇文章隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率中提到的 “递归表达式”
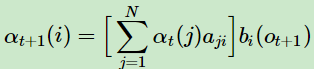
αt(j)*ai,j 表示什么?其实原文已经讲得很清楚了。我再解释一下:核心地讲:在 t 时刻,隐藏状态为 qj, 经状态转移概率ai,j 转移成了t+1 时刻的 qi
既然 t+1 时刻的隐藏状态是 qi了,而我们知道:t+1时刻的隐藏状态qi 是可以从 t 时刻的任何一个“潜在”的隐藏状态 转移 而来的
隐藏状态的集合为Q={q1,q2,...qN}因此:需要 对 j 从1到N求和 。
再进一步,t+1 时刻的隐藏状态 qi 再乘以 在 qi状态下 产生 观测序列 ot+1 的概率 bi(ot+1),那就是在 t+1 时刻观测到 o1 o2 ...ot+1 的概率了。
解释完了上面的递归表达式,再来说说,为什么动态规划降低了时间复杂度。
在动态规划中,原问题规模 是 t+1 时刻的 前向概率αt+1(i),子问题则是:t 时刻的 前向概率,t 相比于 t+1, 问题的规模更小了。
从递归方程中可看出:要想求解 αt+1 需要知道 αt,而要想求解 αt ,又需要知道 αt-1……
因此,动态规划中都有一个初始值概率 α1:

从初始值概率开始,把每步计算出来的 α1 存起来放在一个表里,通过“查表”的方式计算下一步α2的概率……
而暴力算法则是:穷举所有的 隐藏状态的序列,对所有的 隐藏状态序列生成的 观察序列O 的概率值求和,得到P(O|λ)。
总结:
目前大致把HMM模型的第一个问题的求解方法(前向算法)了解了。后向算法和前向算法思路差不多,但是还是有点小疑问,先这样了。另外得学习一下Latex语法和Markdown了。截图片太low了。~^~^~
上面很多内容参考了这二篇博文:
写这篇文章主要是防止自己以后又把整个推导过程给忘了,故写下来记录一下。以后提醒下自己先把上面的两篇博文看上几次,再来看自己写的这篇文章吧。
继续接着隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列 这篇文章开始:)
这篇文章的第一小节部分:讲到了使用“近似算法”来求解 HMM的隐状态序列。这个近似算法其实是一个贪心算法,也就是说:在 t 时刻(t=1,2,...T),得到最可能的隐藏状态i*t,
这种思路是:在t=1时刻,求出最可能的隐藏状态i*1,在t=2时刻,求出最可能的隐藏状态i*2,……在t=T时刻,求出最可能的隐藏状态i*T,再将每个时刻求得的隐藏状态作为 t=1,2,3...T的 最优隐藏状态序列。
然而,每一步都做当前最好的选择,并不能保证全局是最优的。
因此,隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列 的第二部分讲到:用维特比算法,将隐藏状态序列作为整体来考虑,从而求解 全局最优解。
维特比算法的实现思路 和 前向算法 的实现思路非常相似:都是先定义一个公式(概念),然后基于该公式寻找 递归表达式。
在前向算法中,定义了一个“前向概率” 公式,基于该公式 得出一个递归表达式。
维特比算法中,定义了一个“局部状态”:在时刻 t 隐藏状态为 i(值为qi) 的 所有可能状态转移路径i1, i2, ... it 中的最大值δi(t)。然后基于δi(t) 得出一个递归表达式。
而这两个算法 推导 递归表达式的过程 基本上是一样的:都是基于 齐次马尔可夫链 假设 乘以状态转移概率,然后再基于 观测独立性假设 乘以 相应的生成概率 得出递归表达式。
另外,值得一提的是:在维特比算法中,还要记录“概率最大的转移路径节点的隐藏状态Φt(i)”,这主要是用于动态规划过程中的“回溯”,因为动态规划算法按照递归表达式将所有路径给计算出来了,然后再通过“回溯” 来得出最优的那条路径。关于“回溯”可参考《算法导论》里讲解 动态规划求解 “最长公共子序列”的示例(求解两个字符串的最长公共子序列)。
隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列 中的第四部分还给出了一个维特比算法的一个具体的求解示例,真的是非常的详细具体。至此,基本上把HMM模型的“前向算法”和“维特比算法”了解了一下。全都是自己的理解,如有错误,还请批评指正。
原文:http://www.cnblogs.com/hapjin/p/8409163.html