一、Beats
Beats平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向Logstash或Elasticsearch发送数据。常用的Beats有Filebeat(收集文件)、Metricbeat(收集服务、系统的指标数据)、Packetbeat(收集网络包)等。这里主要介绍Filebeat插件。
1、架构图

2、安装Filebeat
官网地址: https://www.elastic.co/cn/products/beats
下载并安装Filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.3.2-linux-x86_64.tar.gz
tar -xzf filebeat-6.3.2-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local/
ln -s filebeat-6.3.2-linux-x86_64 filebeat3、自定义配置文件
① 默认的filebeats配置文件
cd /usr/local/filebeat/
cat > test.yml << END
filebeat.inputs:
- type: stdin
enabled: true
setup.template.settings:
index.number_of_shards: 3
output.console:
pretty: true
enable: true
END
#启动filebeat,启动filebeat的时候用户需要用filebeat用户或者root用户
./filebeat -e -c test.yml
#测试
启动好后输入任意字符串,如hello,即可输出对应信息。
#启动参数说明:./filebeat -e -c test.yml
-e:输出到标准输出,默认输出到syslog和logs下
-c:指定配置文件②添加收集日志的filebeats配置文件
cd /usr/local/filebeat/
cat > test.yml << END
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
- /var/log/messages
exclude_lines: ['^DBG',"^$",".gz$"]
setup.template.settings:
index.number_of_shards: 3
output.console:
pretty: true
enable: true
END
#启动filebeat
./filebeat -e -c test.yml③添加自定义字段的收集日志的filebeats配置文件
cd /usr/local/filebeat/
cat > test.yml << END
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
- /var/log/messages
exclude_lines: ['^DBG',"^$",".gz$"]
tags: ["web","item"] #自定义tags
fields: #添加自定义字段
from: itcast_from #值随便写
fields_under_root: true #true为添加到根节点中,false为添加到子节点中
setup.template.settings:
index.number_of_shards: 3
output.console:
pretty: true
enable: true
END
#启动filebeat
./filebeat -e -c test.yml
#如果有tags字段在logstash中的书写格式
if "web" in [tags] { }④添加收集nginx日志文件输出到ES或者logstash中的filebeats配置文件
cd /usr/local/filebeat/
cat > nginx.yml << END
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/local/nginx/access/*.log
exclude_lines: ['^DBG',"^$",".gz$"]
document_type: filebeat-nginx_accesslog
tags: ["web","nginx"]
fields:
from: nginx
fields_under_root: true
setup.template.settings:
index.number_of_shards: 3
output.elasticsearch:
hosts: ["192.168.0.117:9200","192.168.0.118:9200","192.168.0.119:9200"]
#output.logstash:
# hosts: ["192.168.0.117:5044"]
END
#启动filebeat
./filebeat -e -c nginx.yml4、Filebeat收集各个日志到logstash,然后由logstash将日志写到redis,然后再写入到ES
filebeat配置文件
cat > dashboard.yml << END
filebeat.inputs:
- input_type: log
paths:
- /var/log/*.log
- /var/log/messages
exclude_lines: ['^DBG',"^$",".gz$"]
document_type: filebeat-systemlog
- input_type: log
paths:
- /usr/local/tomcat/logs/tomcat_access_log.*.log
exclude_lines: ['^DBG',"^$",".gz$"]
document_type: filebeat-tomcat-accesslog
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
- type: log
enabled: true
paths:
- /usr/local/nginx/access/*.log
exclude_lines: ['^DBG',"^$",".gz$"]
document_type: filebeat-nginx-accesslog
output.logstash:
hosts: ["192.168.0.117:5044"]
enabled: true
worker: 3
compression_level: 3
END
##启动
./filebeat -e -c dashboard.ymllogstash配置文件
①将logstash收集的日志写入到redis中
cat > beats.conf << END
input {
beats {
port => "5044"
#host => "192.168.0.117"
}
}
output {
if [type] == "filebeat-systemlog" {
redis {
data_type => "list"
host => "192.168.0.119"
db => "3"
port => "6379"
password => "123456"
key => "filebeat-systemlog"
}
}
if [type] == "filebeat-tomcat-accesslog" {
redis {
data_type => "list"
host => "192.168.0.119"
db => "3"
port => "6379"
password => "123456"
key => "filebeat-tomcat-accesslog"
}
}
if [type] == "filebeat-nginx-accesslog" {
redis {
data_type => "list"
host => "192.168.0.119"
db => "3"
port => "6379"
password => "123456"
key => "filebeat-nginx-accesslog"
}
}
}
END②从redis中读取日志写入ES
cat > redis-es.conf << END
input {
redis {
data_type => "list"
host => "192.168.0.119"
db => "3"
port => "6379"
password => "123456"
key => "filebeat-systemlog"
type => "filebeat-systemlog"
}
redis {
data_type => "list"
host => "192.168.0.119"
db => "3"
port => "6379"
password => "123456"
key => "filebeat-tomcat-accesslog"
type => "filebeat-tomcat-accesslog"
}
redis {
data_type => "list"
host => "192.168.0.119"
db => "3"
port => "6379"
password => "123456"
key => "filebeat-nginx-accesslog"
type => "filebeat-nginx-accesslog"
}
}
output {
if [type] == "filebeat-systemlog" {
elasticsearch {
hosts => ["192.168.0.117:9200","192.168.0.118:9200","192.168.0.119:9200"]
index => "logstash-systemlog-%{+YYYY.MM.dd}"
}
}
if [type] == "filebeat-tomcat-accesslog" {
elasticsearch {
hosts => ["192.168.0.117:9200","192.168.0.118:9200","192.168.0.119:9200"]
index => "logstash-tomcat-accesslog-%{+YYYY.MM.dd}"
}
}
if [type] == "filebeat-nginx-accesslog" {
elasticsearch {
hosts => ["192.168.0.117:9200","192.168.0.118:9200","192.168.0.119:9200"]
index => "logstash-nginx-accesslog-%{+YYYY.MM.dd}"
}
}
}
END
二、Logstash
Logstash是Elastic Stack的中央数据流引擎,用于收集、丰富和统一所有数据,而不管格式或模式。当与Elasticsearch,Kibana,及 Beats 共同使用的时候便会拥有特别强大的实时处理能力。
简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
logstash是一个数据分析软件,主要目的是分析log日志,Logstash常用于日志关系系统中做日志采集设备。整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。
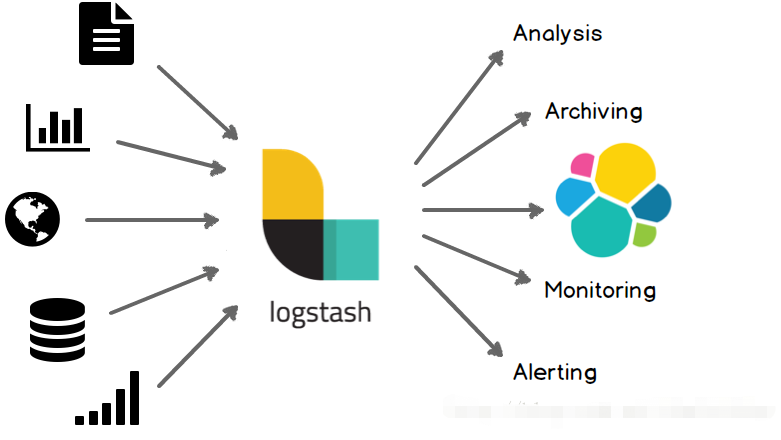
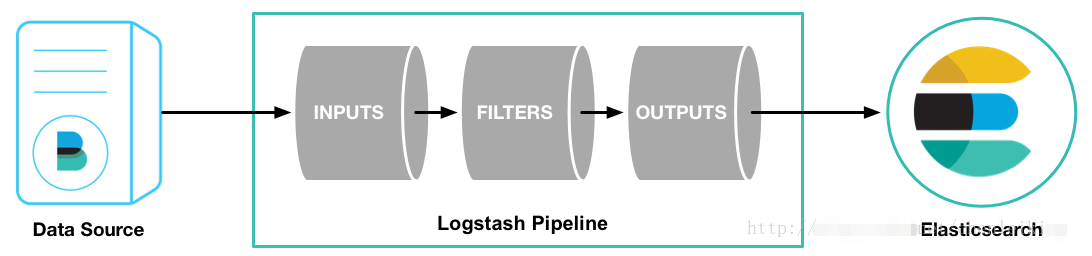
Logstash的事件(logstash将数据流中等每一条数据称之为一个event)处理流水线有三个主要角色完成:inputs –> filters –> outputs:
输入(inpust):必须,负责产生事件(Inputs generate events),常用:File、syslog、redis、beats(如:Filebeats)
Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
过滤器(filters):可选,负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip
过滤器能实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 简化整体处理,不受数据源、格式或架构的影响
输出(outpus):必须,负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、statsd
Logstash 提供众多输出选择,可以将数据发送到指定的地方,并且能够灵活地解锁众多下游用例
其中inputs和outputs支持codecs(coder&decoder)在1.3.0 版之前,logstash 只支持纯文本形式输入,然后以过滤器处理它。但现在,我们可以在输入 期处理不同类型的数据,所以完整的数据流程应该是:input | decode | filter | encode | output;codec 的引入,使得 logstash 可以更好更方便的与其他有自定义数据格式的运维产品共存,比如:graphite、fluent、netflow、collectd,以及使用 msgpack。
1、安装部署logstash
下载指定版本的logstash并解压
curl -O https://download.elasticsearch.org/logstash/logstash/logstash-2.1.1.tar.gz
tar zxvf logstash-2.1.1.tar.gz
在终端中,像下面这样运行命令来启动 Logstash 进程:
- 进入logstash的bin目录 cd logstash-2.1.1/bin
- 执行命令 ./logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
然后你会发现终端在等待你的输入。没问题,敲入Hello World,回车,然后看看会返回什么结果!
- ./logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
- hello world
- {
- "message" => "hello world",
- "@version" => "1",
- "@timestamp" => "2015-11-30T09:07:18.529Z",
- "host" => "atman081.atmandomain"
- }
没错!你搞定了!这就是全部你要做的。
2、简单场景-监控日志文件并以消息形式输出至Kafka
-
定义一个stdout_kafka.conf文件,配置内容为
- input
- {
- file {
- path => ["/var/log/diagonAlley/diagonAlley.log"]
- type => "log4j"
- start_position => "beginning"
- }
- }
- output
- {
- kafka {
- bootstrap_servers => "192.168.1.181:9092,192.168.1.181:9093,192.168.1.181:9094"
- topic_id => "logstash"
- compression_type => "gzip"
- }
- }
-
将stdout_kafka.conf文件放至bin目录
-
运行如下命令,并查看控制台输出
./logstash -f stdout_kafka.conf &
3、简单场景-监控Kafka消息并输出值Elasticsearch
-
定义一个stdout_elasticsearch.conf文件,配置内容为
- input
- {
- kafka {
- zk_connect => "192.168.1.181:2181"
- topic_id => "logstash"
- }
- }
- output {
- elasticsearch {
- hosts => ["192.168.1.181:9100"]
- index => "logstash-%{type}-%{+YYYY.MM.dd}"
- workers =>
- }
- }
-
将stdout_elasticsearch.conf文件放至bin目录
-
运行如下命令,并查看控制台输出
./logstash -f stdout_elasticsearch.conf &
4、logstash使用的几种典型的应用场景
①通过logstash将syslog日志原始日志转发
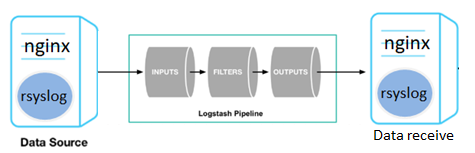
在logstash的bin目录下新建配置文件
vi test-pipeline.conf
编辑input和output
input {
stdin{
type => "test-log"
}
syslog{
type => "test-log"
port => 514
}
}
output
{
stdout {
codec => rubydebug
}
syslog{
host => "192.168.2.185"
port => 514
}
}
这样就相当于把日志转发到了192.168.2.185这台机器的514端口
编辑好配置文件以后执行./logstash -f test-pipeline.conf --config.test_and_exit 对配置文件进行检查,如果配置文件写得有问题,将会有错误提示。
配置文件检查没有问题后就可以启动logstash执行了./logstash -f test-pipeline.conf --config.reload.automatic
用udpsender工具往这台机器上发送日志信息,可以看到日志转发到192.168.2.185这台机器上了。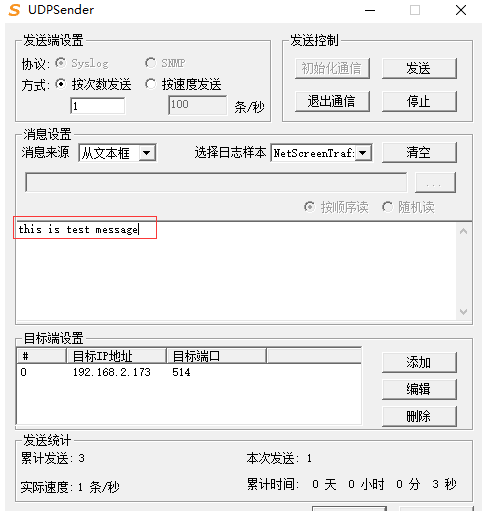
在控制台可以看到192.168.2.185,接收到了192.168.2.173转发过来的日志
②通过rsyslog、logstash采集nginx等中间件的日志送到ES
logstash可以与rsyslog、filebeat等无缝结合采集nginx等中间件日志,送给数据存储。
③通过logstash将日志入kafka再入mysql或ES

数据先放到kafka队列里缓存削峰,然后从kafka队列里读取数据到mysql或其他存储系统中进行保存。
④通过logstash进行日志补全后再转发或入库
采集原始日志以后,需要对原始日志进行调整合补齐,比如最常见的是根据IP来补齐IP的经纬度等信息。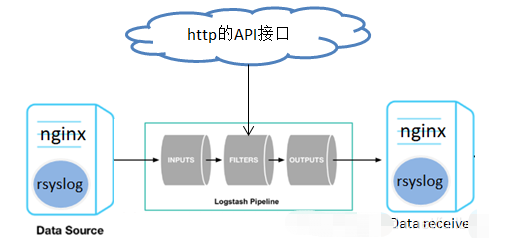
这里就可以用logstash的geotip,也可以用其他的外部API接口,为了更具代表性的说明,这里调用的是第三方的http接口
参考配置文件如下:
input {
stdin { }
syslog {
port => "514"
}
}
filter {
grok{
#匹配获取IP
match => {"message" => "%{IPV4:ip}"}
}
http {
#调用外部接口获取IP的详细信息
url => "http://ip-api.com/json/%{ip}"
verb => "GET"
add_field => {
"new_field" => "new_static_value"
}
}
mutate {
replace => {
#这里对原始日志数据进行补全,如加了新的字段及从接口中获取的信息
"message" => "%{message}|%{ip}: My new message|%{new_field}|%{[body][as]}"
}
}
}
output {
stdout { }
syslog {
host => "192.168.2.173"
port => "7514"
}
}
通过http接口调用API取得数据,然后通过mutate重新组合补全信息,这里通过调用获取IP地址信息的API获取IP的信息,然后补全到原始日志中。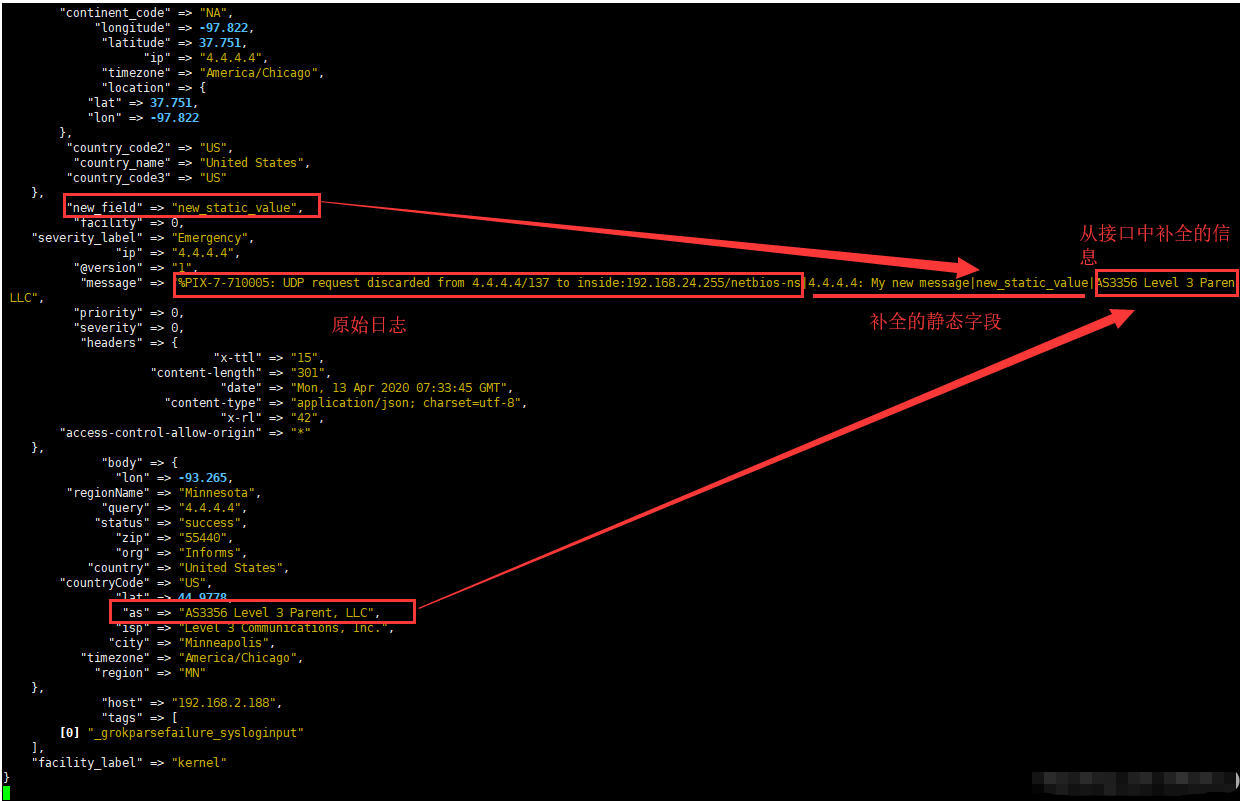
可以看出logstash是一个非常灵活好用的数据采集框架工具,可以通过简单的配置满足绝大多数数据采集场景的需求。
三、ElasticSearch
Elasticsearch 是一个开源的分布式RESTful搜索和分析引擎,能够解决越来越多不同的应用场景。
从数据获取,存储计算到可视化,ES 开发了一整套解决方案,Logstash 、Beat 负责数据抓取,ES 负责存储计算,kibana 对数据进行展示分析。另外还有收费的 X-Pack 可以实现安全、告警、监控和 ML 等更丰富的功能。ES 在搜索、日志分析、指标分析和安全分析等领域应用广泛。从前端到后端到数据分析,从云服务到最流行的机器学习,ES 都提供了一整套解决方案。
elastcsearch 从设计之初就不是用来像mysql, oracle...那样存数据的。es不支持事务
它是搜索引擎...
重要的数据别放里面!
elasticSearch的安装配置请自行百度,可以直接使用postman调用es的接口网es中put数据,也可以和其他框架集成来使用,比如和springboot集成来完成CRUD ES。
**小刘最近在做搜索相关的事,但一直很苦恼。他之前在用数据库,如MySQL,来做搜索的业务,如知识库管理、问答和文档搜索等。在这过程中,他发现数据库并不能很好的满足他的需求。
1.响应时间
MySQL
背景:
小刘在做测试时,发现当数据库中的文档数仅仅上万条时,关键词查询就比较慢了。如果一旦到企业级的数据,响应速度就会更加不可接受。
原因:
在数据库做模糊查询时,如LIKE语句,它会遍历整张表,同时进行字符串匹配。
例如,当小刘在数据库查询“市场”时,数据库会在每一条记录去匹配“市场”这两字是否出现。实际上,并不是所有记录都包含“市场”,所以做了很多无用功。
这两个步骤都不高效,而且随着数据量的增大,消耗的资源和时间都会线性的增长。
Elasticsearch
提升:
小刘使用了云搜索服务后,发现这个问题被很好解决,TB级数据在毫秒级就能返回检索结果,很好地解决了痛点。
原因:
而Elasticsearch是基于倒排索引的,例子如下。
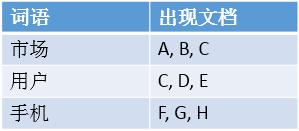
当小刘搜索“手机”时,Elasticsearch就会立即返回文档F,G,H。这样就不用花多余的时间在其他文档上了,因此检索速度得到了数量级的提升
2.分词
MySQL
背景:
在做中文搜索时,小刘发现组合词检索在数据库是很难完成的。
例如,当用户在搜索框输入“四川火锅”时,数据库通常只能把这四个字去进行全部匹配。可是在文本中,可能会出现“推荐四川好吃的火锅”,这时候就没有结果了。
原因:
数据库并不支持分词。如果人工去开发分词功能,费时费精力。
Elasticsearch
提升:
小刘使用云搜索服务后,就不用太过于关注分词了,因为Elasticsearch支持中文分词插件,很好地解决了问题。
原因:
当用户使用Elasticsearch时进行搜索时,Elasticsearch就自动帮他分好词了。
例如当小刘输入“四川火锅”时,Elasticsearch会自动做下面两件事
(1) 将“四川火锅”分词成“四川”和“火锅”
(2) 查找包含这两个词的文档
3.相关性
MySQL
背景:
在用数据库做搜索时,结果经常会出现一系列文档。小刘不禁思考:
· 到底什么文档是用户真正想要的呢?
· 怎么才能把用户想看的文档放在搜索列表最前面呢?
原因:
数据库并不支持相关性搜索。
例如,当用户搜索“咖啡厅”的时候,他很可能更想知道附近哪里可以喝咖啡,而不是怎么开咖啡厅。
Elasticsearch
提升:
小刘使用了云搜索服务后,发现Elasticsearch能很好地支持相关性评分。通过合理的优化,云搜索服务能够返回精准的结果,满足用户的需求。
原因:
Elasticsearch支持全文搜索和相关度评分。这样在返回结果就会根据分数由高到低排列。分数越高,意味着和查询语句越相关。
例如,当用户搜索“星巴克咖啡”,带有“星巴克咖啡”的信息就要比只包含“咖啡”的信息靠前。
四、Kibana
Kibana是通向Elastic产品集的窗口,它可以在Elasticsearch中对数据进行视觉探索和实时分析。
Kibana出报表的整个流程分为3步:
• 第一步:写query,在Elastic Search里搜出一批数据
• 第二步:使用搜出来的数据,创建图表
•第三步:拼接多个图表,做成一个报表
建什么报表,就是看使用者的想象力了。我一开始是做了搜索相关的报表,像是最近一小时热搜关键词,最近一小时缓存命中率什么的。后来发现,Kibana的潜力真是无穷无尽。
Kibana加上Elastic Search,可以做实时数据分析。而且因为Elastic Search本质是个高性能搜索引擎,所以出数据很快。
现在让我们把这几个成员组装到一起。
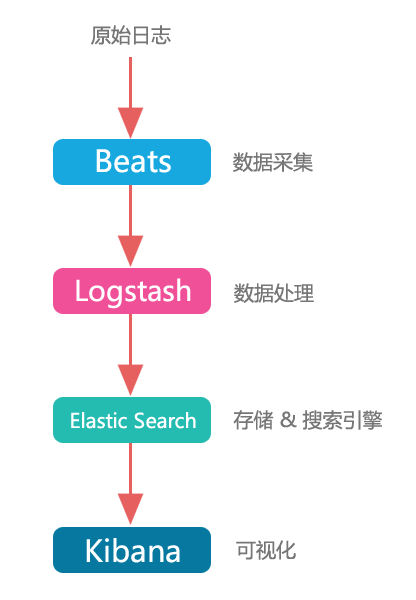
可以看到,Beats + Logstash + Elastic Search + Kibana,可以做一套非常强大的日志系统。
官方给的图:
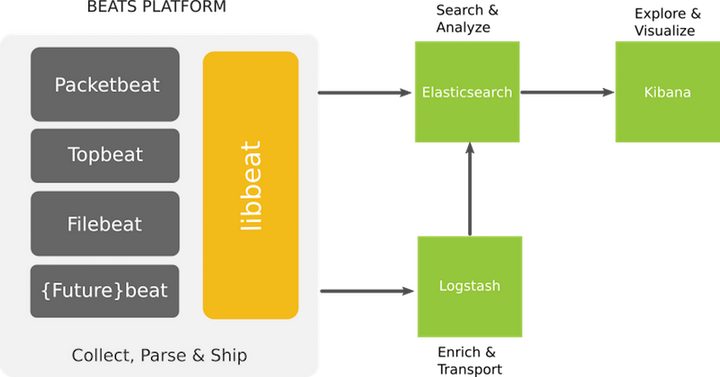
一套日志系统,高可用,可横向扩展,高自定义,出来的图表还好看,你说吼不吼啊!
具体怎么组装ES全家桶的,还是推荐各位上官网看文档,或者搜其他教程,或者直接把全家桶download下来把玩。毕竟日志系统里面最核心的ES索引设计,是跟着具体业务走的。
本文提供一些经验:
• 不一定全家桶都要用
在数据量不大、或者做抽样的时候,完全可以不用Beats和Logstash,数据直接用HTTP RESTful接口怼Elastic Search。如果是一些监控类的脚本,可以直接在shell里一句curl搞定,非常适合运维同学使用。
• 大数据量下的配置
数据量到了一定规模的时候,全家桶组合拳会开始体现价值。
Beats是简单高可用的,瓶颈一般会出现在Logstash(吃CPU)和Elastic Search(吃磁盘IO)上。Logstash好办,而Elastic Search在加机器的时候如果分片数量过少,会影响效果。所以建议一开始就给索引(index)配置较大的分片数量(shards)。
Elastic Search的ttl属性有点问题,如果要按时间分片的话,建议直接从索引这一层来操刀。例如搜索日志的索引名字就叫search-log-20160924。自己造个轮子,定时创建新的索引、删除过期的索引。
• 能不能不用Elastic Search
当然可以,Beats跟Logstash单独拿出来用也是很不错的工具。数据存储和分析未必要走-> ES -> Kibana这条路。可以感受到,Elastic Search逐渐成为Elastic Stack的概念了,不仅仅是搜索,而是整套数据解决方案。