小试牛刀:爬取壁纸网的壁纸
今天偶然看到一个网站的壁纸很好看,于是想下载下来。可是每张图都要自己右键再下载,我觉得有点麻烦。于是尝试写了一个小程序来下载
基本思路:根据图片url然后使用urlretrieve方法来下载这些图片
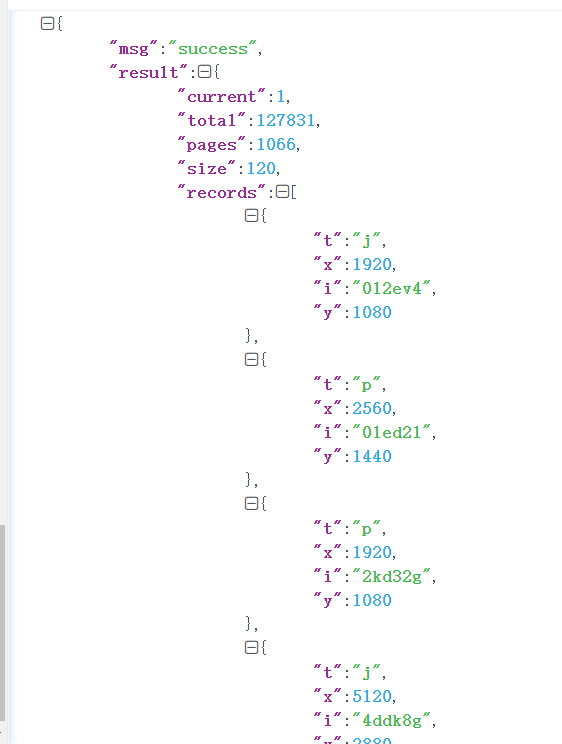
由于这个网站是动态加载的,开始一直尝试了很多次,才知道只有抓包才能看到后台返回来的json格式
再来分析图片的url
如果是在网站里分析得到的url它只是缩略图,并不是高清的。这里也是通过抓包才发现的
原url:
https://th.wallhaven.cc/small/01/012ev4.jpg
高清图url:
https://w.wallhaven.cc/full/r7/wallhaven-r7x3dj.jpg
发现json里面的i就是url最后面的代码
于是我处理了一下这些json和url
#文件名,里面存放json数据 filename='lala' #打开文件 file=open(filename,'r',encoding='utf-8') #读取文件 text=file.read() #通过json.loads解析数据 json = json.loads(text) #使用一个全局列表 my_list=[] #获取需要的url代码,存入列表 data_list =json['result']['records'] print(len(data_list)) #遍历这个列表 for i in data_list: # print((i)['i']) #把这个特殊代码加入到列表 my_list.append(i['i'])
此时my_list里面存放的是那些特殊代码
下面处理url和提取出来的特殊代码拼接成新的url
#待拼接的url url = 'https://w.wallhaven.cc/full/' headers = { 'User-Agent': 'Mozilla / 5.0(Windows NT 10.0 WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 79.0.3945.117Safari / 537.36' } x=40 #遍历这个特殊代码列表 for i in my_list[67:]: # print(i) # 提取前两个字母 parse_add = i[0:2] # 把前两字母增加到url中 new_url = url + parse_add # 再把wallhaven-4l37r4.jpg增加到url中 new_new_url = new_url + '/wallhaven-' + i + '.jpg' print(new_new_url)
拼接好图片的url,接下来就是访问并下载了
#这里不能直接用urlretrieve,否则会返回403 try: opener = urllib.request.build_opener() opener.addheaders = [('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')] urllib.request.install_opener(opener) urllib.request.urlretrieve(new_new_url, str(x)+'.jpg',Schedule) except urllib.error.HTTPError as e: print(str(e)) x=x+1 print('第%d张图片已下载完毕...^_^'%x)
完整代码
import urllib.request import urllib.parse import json import time import urllib.error def Schedule(blocknum,blocksize,totalsize): ''''' blocknum:已经下载的数据块 blocksize:数据块的大小 totalsize:远程文件的大小 ''' per = 100.0 * blocknum * blocksize / totalsize if per > 100 : per = 100 print('当前下载进度:百分之%d '%per) #文件名 filename='lala' #打开文件 file=open(filename,'r',encoding='utf-8') #读取文件 text=file.read() #通过json解析数据 json = json.loads(text) #使用一个全局列表 my_list=[] #获取需要的url代码,存入列表 data_list =json['result']['records'] print(len(data_list)) #遍历这个列表 for i in data_list: # print((i)['i']) #把这个特殊代码加入到列表 my_list.append(i['i']) #待拼接的url url = 'https://w.wallhaven.cc/full/' headers = { 'User-Agent': 'Mozilla / 5.0(Windows NT 10.0 WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 79.0.3945.117Safari / 537.36' } x=40 #遍历这个特殊代码列表 for i in my_list[67:]: # print(i) # 提取前两个字母 parse_add = i[0:2] # 把前两字母增加到url中 new_url = url + parse_add # 再把wallhaven-4l37r4.jpg增加到url中 new_new_url = new_url + '/wallhaven-' + i + '.jpg' print(new_new_url) #这里不能直接用urlretrieve,否则会返回403 try: opener = urllib.request.build_opener() opener.addheaders = [('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')] urllib.request.install_opener(opener) urllib.request.urlretrieve(new_new_url, str(x)+'.jpg',Schedule) except urllib.error.HTTPError as e: print(str(e)) x=x+1 print('第%d张图片已下载完毕...^_^'%x)
效果图: