首先要准备python3+scrapy+pycharm
一、首先让我们了解一下网站
拉勾网https://www.lagou.com/
和Boss直聘类似的网址设计方式,与智联招聘不同,它采用普通的页面加载方式
我们采用scrapy中的crawlspider爬取
二、创建爬虫程序
scrapy startproject lagou
创建爬虫文件
scrapy genspider -t crawl zhaopin "www.lagou.com"
由此爬虫程序创建完毕
三、编写爬虫程序
出于演示和测试,我们这次只爬取一条数据。
items文件
import scrapy class BossItem(scrapy.Item): # 岗位名称 jobName = scrapy.Field()
zhaopin.py爬虫文件
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from boss.items import BossItem class ZhipinSpider(CrawlSpider): name = 'zhipin' allowed_domains = ['www.lagou.com'] start_urls = ['https://www.lagou.com'] rules = ( Rule(LinkExtractor(allow=r'com/zhaopin/w+/'), callback='zhilianParse', follow=False), #采用正则匹配的方式,获取网页url ) def zhilianParse(self, response): datas = response.xpath('//ul[@class="item_con_list"]/li') #通过xpath方式获取要爬取的域 for data in datas: #逐层迭代 item = BossItem() # 岗位名称 item["jobName"] = data.xpath('//div//div/a/h3[1]/text()').get() #定位爬取信息 yield item #rule会迭代所有的url不需要再写回调函数
管道文件
import json
import os
class BossPipeline(object):
def __init__(self):
self.filename = open("Boss.json", "wb")
self.path = "G:imagesp"
if not os.path.exists(self.path):
os.mkdir(self.path) #判断路径
def process_item(self, item, spider):
# 岗位名称
jobName = item['jobName']
js = json.dumps(dict(item), ensure_ascii=False) + "
"
self.filename.write(js.encode("utf-8"))
return item
def __close__(self):
self.filename.close()
配置settings文件
DEFAULT_REQUEST_HEADERS = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36', }
ITEM_PIPELINES = {
'boss.pipelines.BossPipeline': 300,
}
LOG_FILE="log.log" #放日志文件用的,可有可无
ROBOTSTXT_OBEY = False
四、启动爬虫
scrapy crawl zhaopin
爬取结果
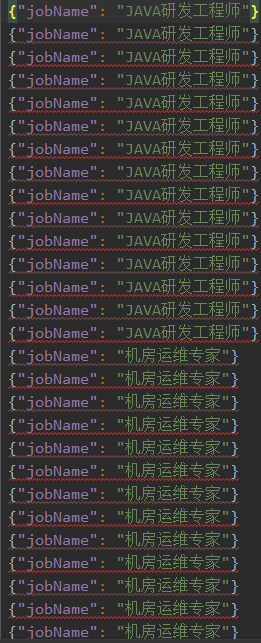
在第一篇文章中讲了如何存入mysql,这里我就不多赘述了,大家自行查阅。