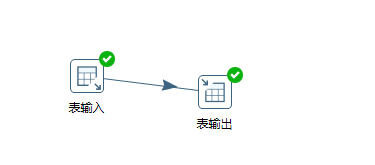
1.mysql->mysql(完全同字段数据同步)
当然,实际此种情况当然可以选择navicat
1)打开spoon,连接资源库(推荐)
2)新建转换,之后在主对象树新建数据库连接并右键共享(统一数据源管理)
3)拖入一个表输入,配置连接信息,获取SQL语句,完成表输入配置(无变量情况)
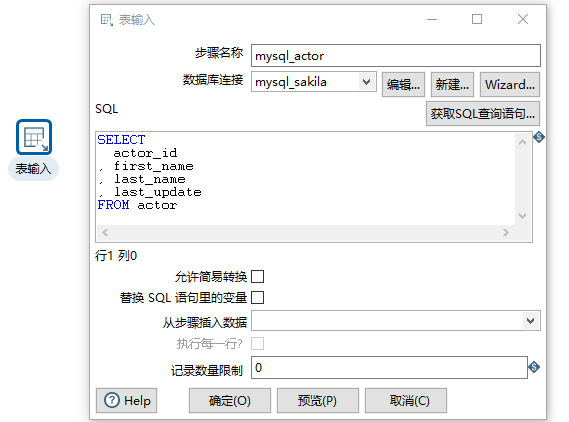
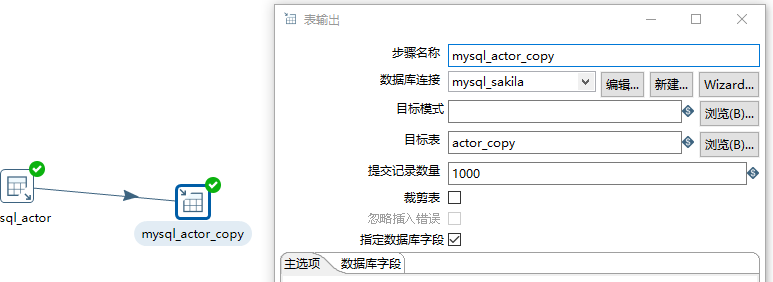
4)拖一个表输出(需要在目的库中先建表),选择目标表,获取字段,输入字段映射
5)运行转换,查看日志
2.mysql->mysql(目的库增加来源、系统时间两个字段)
如果按照常规的使用自定义常量数据,将会报错如下:
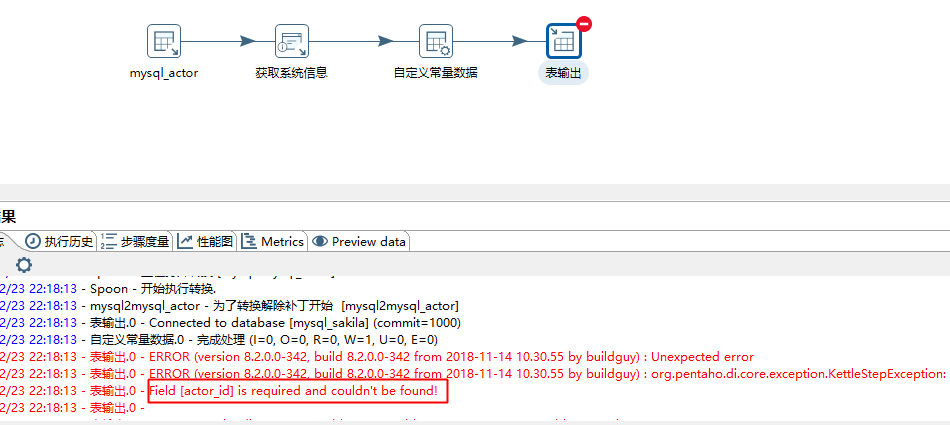
根据网友提示,使用核心对象->转换->增加常量:
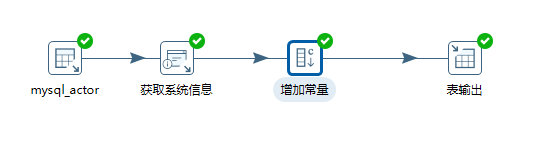
3.简单数据增量同步
基本参考:https://blog.csdn.net/aganliang/article/details/84995294
此方式的弊端,参考上述链接。此方式有个缺陷是每个表都需要一个表来记录加载时间,可以优化为一个总表汇总
通过增加设置常量等组件,不过SQL语句等就需要写死一些表名了,也不利于拓展
1)首先新建一个表用于记录同步时间(此处采用和资源库相同的库保存此表)
CREATE TABLE `etl_time_actor` ( `last_load_time` datetime NULL DEFAULT '1970-01-01 00:00:00' COMMENT '上次同步时间' , `curent_load_time` datetime NULL COMMENT '当前时间' ) COMMENT='etl同步时间' ;
2)第一个转换用于将当前时间内存入current_load_time字段中:
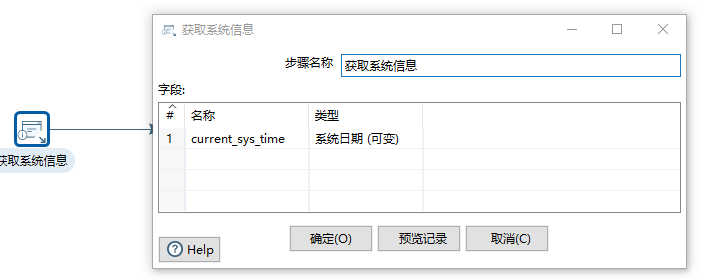
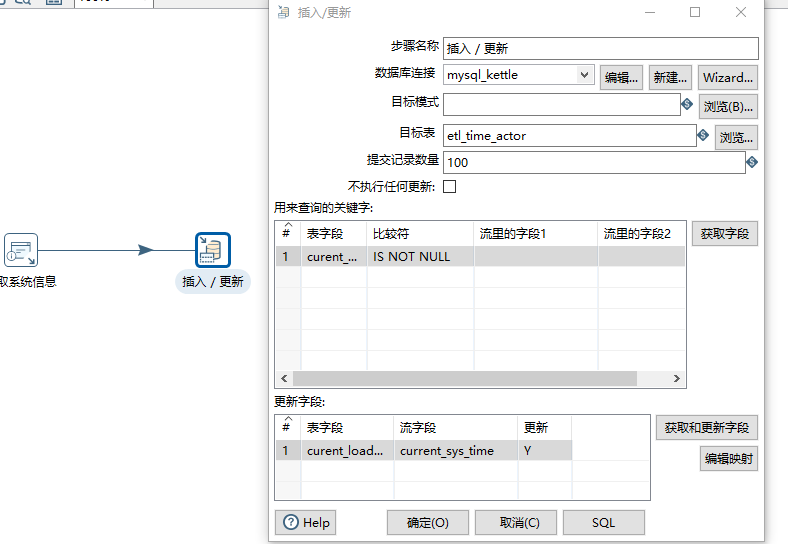
// 通过current_load_time这个表字段来进行判断
3).第二个转换用于抽取增量数据
首先第一个转换设置的时间:
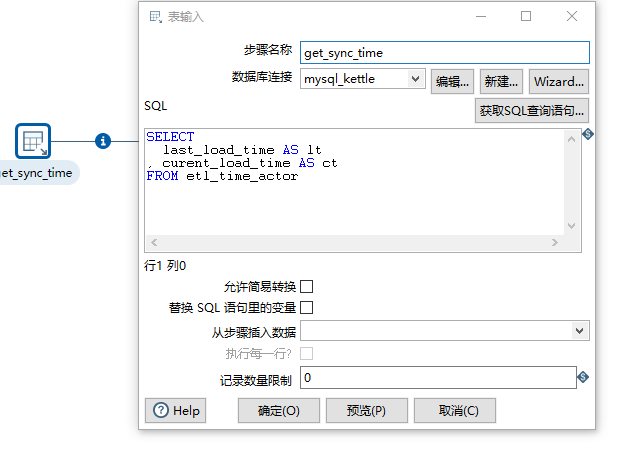
然后通过参数提取增量数据(时间从前一步读取)
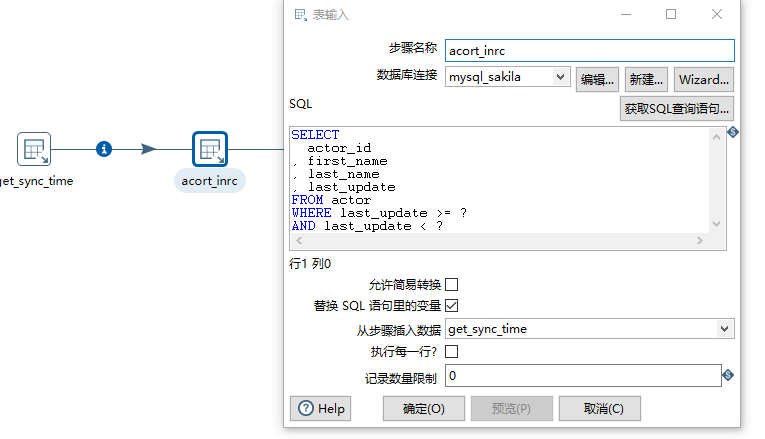
注意要勾选替换变量!
最后插入增量数据(选择裁剪表则会对数据进行清空,再插入)
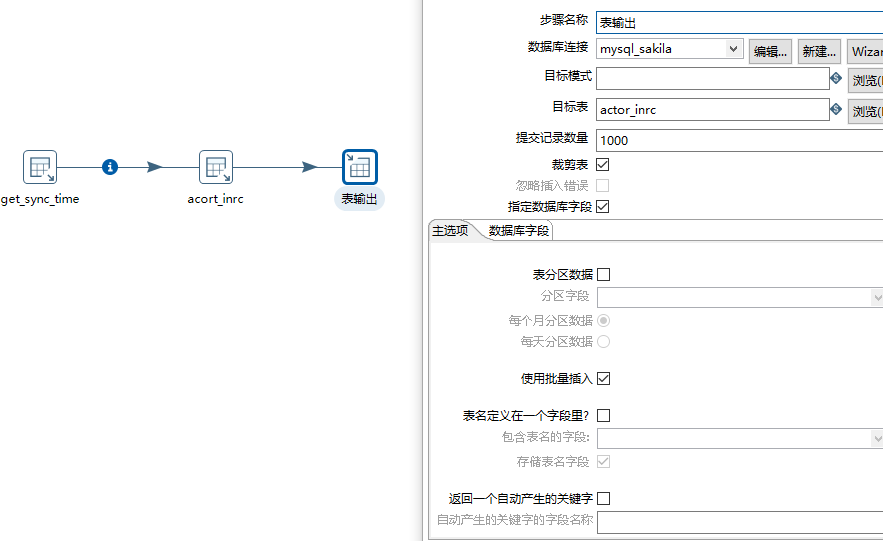
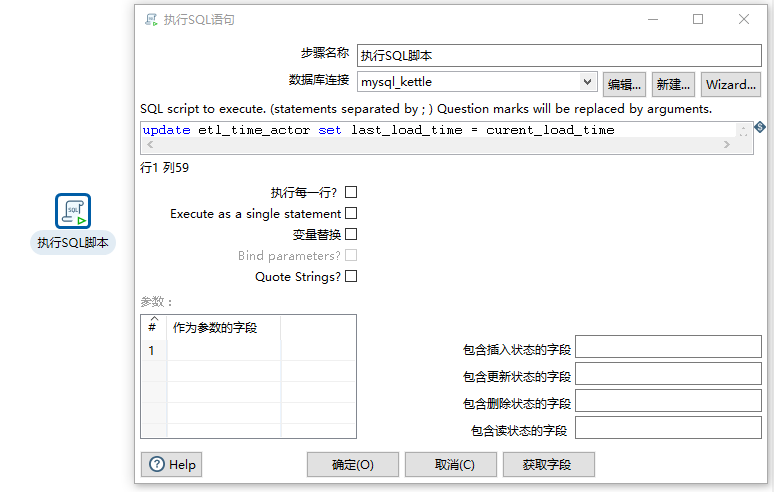
4)第三个转换,将上次加载时间设置为本次时间,方便下次做增量
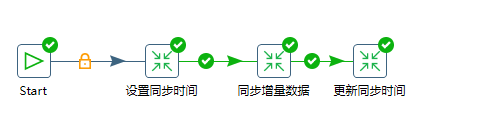
5)这样我们将几个转换串起来,增量提取简易版就算完成了
4.简单同步到hive
参考之前随笔建立hive连接:https://www.cnblogs.com/jiangbei/p/9372275.html
注意使用后台nohub启动:
nohup hive --service hiveserver2 &
请注意需要关闭namanode和datanode的防火墙!
简单的拉个输入输出: