起因
下述内容需要具备 HTTP 的基础知识,如果不知道的可以过一遍 HTTP 协议详解
继上次在 K210 实现 HTTP Download 文件(https 也支持辣),现在就来说说直接基于 socket 的上传文件实现吧。
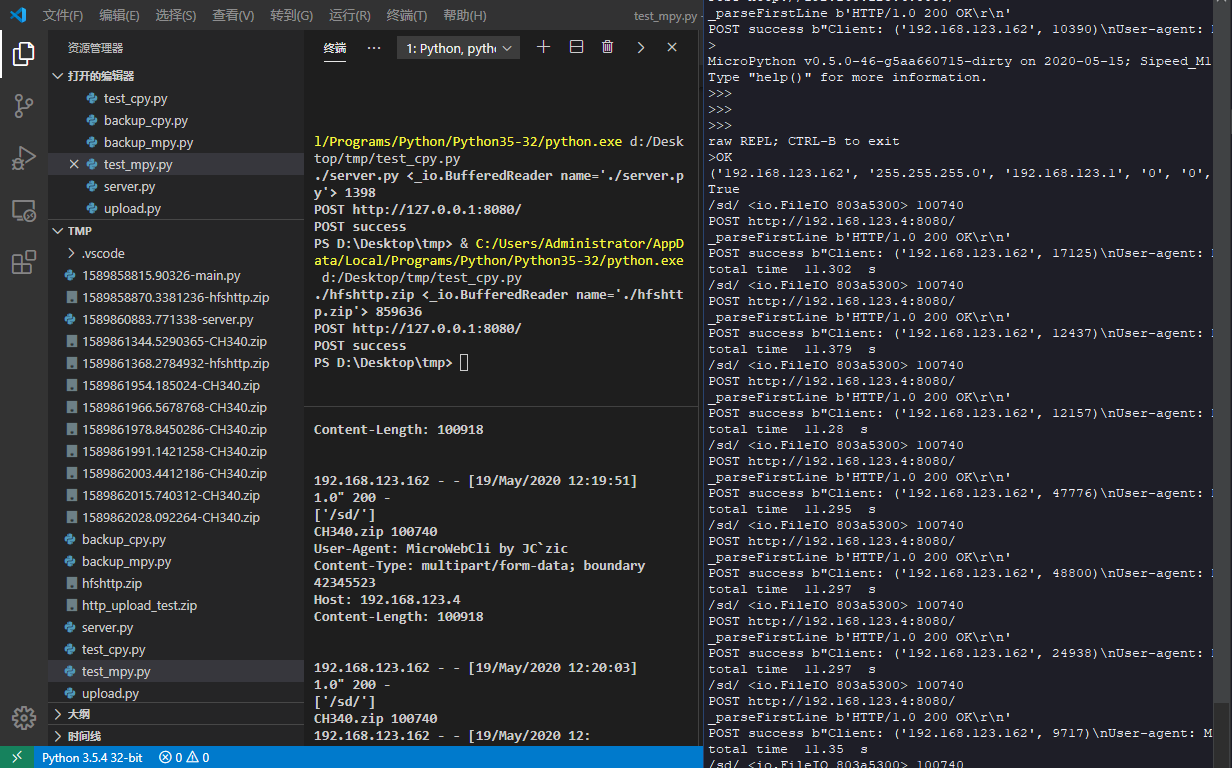
首先准备一个 Server 文件服务器的 CPython 代码,这个是再简单不过了。
# coding=utf-8
from http.server import BaseHTTPRequestHandler
import cgi
import time
class PostHandler(BaseHTTPRequestHandler):
def do_POST(self):
print(self.headers)
form = cgi.FieldStorage(
fp=self.rfile,
headers=self.headers,
environ={'REQUEST_METHOD': 'POST',
'CONTENT_TYPE': self.headers['Content-Type'],
}
)
self.send_response(200)
self.end_headers()
self.wfile.write(('Client: %s
' % str(self.client_address)).encode())
self.wfile.write(('User-agent: %s
' %
str(self.headers['user-agent'])).encode())
self.wfile.write(('Path: %s
' % self.path).encode())
self.wfile.write(b'Form data:
')
print(form.keys())
for field in form.keys():
field_item = form[field]
filename = field_item.filename
filevalue = field_item.value
filesize = len(filevalue) # 文件大小(字节)
print(filename, filesize)
with open('%s-' % time.time() + filename, 'wb') as f:
f.write(filevalue)
return
def StartServer():
from http.server import HTTPServer
sever = HTTPServer(("0.0.0.0", 8080), PostHandler)
sever.serve_forever()
if __name__ == '__main__':
StartServer()
可以看到实现处理了一个 post 的请求,然后对这个请求依次解析出来,通常情况下找找代码调用一下就成功了,比如下面的这份调用 request 的代码:
#coding=utf-8
import requests
url = "http://127.0.0.1:8080"
path = "./hfshttp.zip"
print(path)
files = {'file': open(path, 'rb')}
r = requests.post(url, files=files)
print (r.url)
print (r.text)
'''
Host: 127.0.0.1:8080
Connection: keep-alive
Accept: */*
User-Agent: python-requests/2.22.0
Accept-Encoding: gzip, deflate
Content-Length: 859783
Content-Type: multipart/form-data; boundary=c42a6d00053f74d5edd8c8b00a8318ef
['file']
hfshttp.zip 859636
'''
上传文件是不是很简单就实现了,这也是随处可见的代码,但这代码背后其实做了很多工作,你是无法直接在 MicroPython 上运行的。
没有 requests 怎么办?
不仅没有 requests 也没有 urllib ,那这可怎么办呢?
留给我们的只有如下模块。
from struct import pack
import socket
import uio as io
这个问题很早就年就有人在讨论了,但随着 CPython 的逐渐流行和成熟,基本上回复的都是赶紧换 requests ,也许谁也没想到后来还有个 MicroPython 吧,那没库了我们就不行了吗?
在这之前的文章,我已经在 K210 的 MicroPython 上基于 www.hc2.fr 的 MicroWebCli 实现了 HTTP 的基本操作,也就是我们常见的 GET 、POST 基础功能已经具备了,也就是如何包装一个上传数据包的问题。
如何选择上传文件协议呢?我们有两种请求的规范,前者是 PUT ,后者是 POST。
在 HTTP 1.1 之上有一个 WebDAV 协议,它和 FTP 一样,都拓展出了 PUT 、GET 、 Delete 等文件操作,与 FTP 的区别在于端口不同,因为一个是 80 另一个是 21,接着 WebDAV 是网络访问和文件请求并存的一种拓展协议,也就是说,最简单的文件上传协议就是实现一个 PUT,要求服务器开发 WebDAV 的实现就可以了,当然,本文的重点不在讲如何实现文件服务器的功能,只是提及一下 PUT 指令的内容,以此切入 POST 上传文件的基础知识铺垫。
那么 PUT 实现都有哪些内容呢?只需要客户端 socket 组装下述内容发送给开放了 HTTP1.1 PUT 指令的服务器就可以被接收处理了,以往经常有人会拿这个命令来试探服务器有没有漏洞 hah 所以现在的人都关了这个功能,或者上验证了。
PUT /bacon.htm HTTP/1.1
Content-Length: 31
Accept: */*
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Win32)
Host: 218.94.36.38:9010
Content-Length: text/plain
a piece of data
可以看出 PUT 的规范很简洁,下面提供一个 Python 的 Code 帮助你体会体会?
# File: httplib-example-2.py
import httplib
USER_AGENT = "httplib-example-2.py"
def post(host, path, data, type=None):
http = httplib.HTTP(host)
# write header
http.putrequest("PUT", path)
http.putheader("User-Agent", USER_AGENT)
http.putheader("Host", host)
if type:
http.putheader("Content-Type", type)
http.putheader("Content-Length", str(len(data)))
http.endheaders()
# write body
http.send(data)
# get response
errcode, errmsg, headers = http.getreply()
if errcode != 200:
raise Error(errcode, errmsg, headers)
file = http.getfile()
return file.read()
if __name__ == "__main__":
post("www.spam.egg", "/bacon.htm", "a piece of data", "text/plain")
实际上不难理解,想知道更多可以自行了解,可以看看这个 HTTP 协议入门 ,深入一点就要看标准协议辣,例如 Hypertext Transfer Protocol -- HTTP/1.1,示例 Code 来源在这里 The httplib module。
注意,为什么我要提及 PUT 实际上是有原因的,早期它的实现很简单,作为历史的车轮自然会依次淘汰掉不可靠的一些指令,尤其是复杂的指令要求服务器有对应的实现,后来 PUT 也因为服务器漏洞问题而被大部分场合禁用了,所以实现它已经没有什么意义了,那么接下来该怎么办呢?
这时候我们就要引出第二个上传协议 multipart/form-data 了。
multipart/form-data 是什么?如何实现?
multipart/form-data最初由 《RFC 1867: Form-based File Upload in HTML》文档定义。
Since file-upload is a feature that will benefit many applications, this proposes an
extension to HTML to allow information providers to express file upload requests uniformly, and a MIME compatible representation for file upload responses.
文档简介中说明文件上传作为一种常见的需求,在目前(1995年)的html中的form表单格式中还不支持,因此发明了一种兼容此需求的mime type。
The encoding type application/x-www-form-urlencoded is inefficient for sending large quantities of binary data or text containing non-ASCII characters. Thus, a new media type,multipart/form-data, is proposed as a way of efficiently sending the
values associated with a filled-out form from client to server.
文档中也写了为什么要新增一个类型,而不使用旧有的application/x-www-form-urlencoded:因为此类型不适合用于传输大型二进制数据或者包含非ASCII字符的数据。平常我们使用这个类型都是把表单数据使用url编码后传送给后端,二进制文件当然没办法一起编码进去了。所以multipart/form-data就诞生了,专门用于有效的传输文件。
现在我们假设服务器是一个黑盒子,符合上传文件的实现规范,而我们要做的就是在 MicroPython 上实现 HTTP 文件的上传文件,而且不是 PUT 指令,而是通过 POST 的实现,这里我们就要来实现它了。
首先我们在本文的最初就已经通过 requests 进行了一个上传文件的实践,接下来留给我们的挑战就是如何实现它,先看这篇文章 the-unfortunately-long-story-dealing-with ,可以不用细看,只是因为它提供了一份封装数据包的逻辑实现,我们只需要通过它就可以实现基础逻辑。
根据下图的逻辑,第一个是确定 HTTP 的 header 属于 POST 操作,同时提供了 Content-type 和 Content-length 文件信息。
import mimetools
import mimetypes
import io
import http
import json
form = MultiPartForm()
form.add_field("form_field", "my awesome data")
# Add a fake file
form.add_file(key, os.path.basename(filepath),
fileHandle=codecs.open("/path/to/my/file.zip", "rb"))
# Build the request
url = "http://www.example.com/endpoint"
schema, netloc, url, params, query, fragments = urlparse.urlparse(url)
try:
form_buffer = form.get_binary().getvalue()
http = httplib.HTTPConnection(netloc)
http.connect()
http.putrequest("POST", url)
http.putheader('Content-type',form.get_content_type())
http.putheader('Content-length', str(len(form_buffer)))
http.endheaders()
http.send(form_buffer)
except socket.error, e:
raise SystemExit(1)
r = http.getresponse()
if r.status == 200:
return json.loads(r.read())
else:
print('Upload failed (%s): %s' % (r.status, r.reason))
于是这个请求的第一阶段就结束了,此时发起的 HTTP 数据如下:
- CPython 的 requsets
POST / HTTP/1.0
User-Agent: python-requests/2.22.0
Accept-Encoding: gzip, deflate
Connection: keep-alive
Accept: */*
Content-Length: 859783
Content-Type: multipart/form-data; boundary=c76ef433019742a27e38c33455206c52
- MicroPython 的 MicroWebCli
POST / HTTP/1.0
Content-Type: multipart/form-data; boundary=1590160638.3663664
Host: 127.0.0.1
User-Agent: MicroWebCli by JC`zic
Content-Length: 859808
这都是封装数据的过程,它只是发起了第一次的请求,接下来还有 form-data 的数据交互的请求,它格式满足如下,但这要如何理解呢?实际上在第一次的请求中就已经告知本次的 form-data 内容和长度了,所以在第一次的请求结束后,就需要继续发送这个 form-data 数据。
POST http://127.0.0.1:8080/
--1590161992.5543046
Content-Disposition: file; name="./"; filename="hfshttp.zip"
Content-Type: application/octet-stream
上述的 form-data 可以这样理解,其中 --1590161992.5543046 是第一次请求中提出的分隔符boundary,这个分隔符可不能在后续的文件中出现,因为是用来分批文件上传处理的,, form-data 标准格式是 name 和 value ,你也在这里面可以设计很多个协议内容,其他的就需要你看看服务器这一端的解析和实现了,例如下面这个是服务器的解析实现。
def do_POST(self):
form = cgi.FieldStorage(
fp=self.rfile,
headers=self.headers,
environ={'REQUEST_METHOD': 'POST',
'CONTENT_TYPE': self.headers['Content-Type'],
}
)
self.send_response(200)
self.end_headers()
self.wfile.write(('Client: %s
' % str(self.client_address)).encode())
self.wfile.write(('User-agent: %s
' %
str(self.headers['user-agent'])).encode())
self.wfile.write(('Path: %s
' % self.path).encode())
self.wfile.write(b'Form data:
')
for field in form.keys():
field_item = form[field]
filename = field_item.filename
filevalue = field_item.value
filesize = len(filevalue) # 文件大小(字节)
print(filename, filesize)
with open('%s-' % time.time() + filename, 'wb') as f:
f.write(filevalue)
return
当接收到路由(url)的 / 请求,先给个 200 应答表示接收到头了,再来解析 form-data 中的数据,其中 field 和 form[field].filename 对应的就是上述 Content-Disposition: file; name="./"; filename="hfshttp.zip" 中的 name 和 filename ,这样你就知道如何理解文件是如何被提取和下载的了。
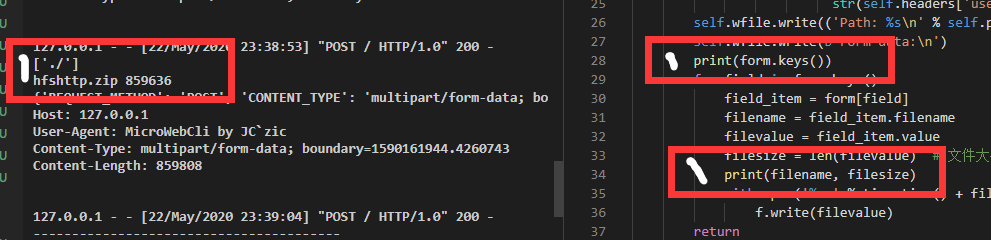
所以 form-data 的格式是这样的,参见 rfc1867 的 6. Examples 。
Content-type: multipart/form-data, boundary=AaB03x
--AaB03x
content-disposition: form-data; name="field1"
Joe Blow
--AaB03x
content-disposition: form-data; name="pics"; filename="file1.txt"
Content-Type: text/plain
... contents of file1.txt ...
--AaB03x--
实际上 field_item.value 对应的内容它就在 ... contents of file1.txt ... 省略的位置里填充的,所以你可以理解 form-data 实际上就是一个被封装的多次 POST 请求,最后客户端传输完成后,会等待服务器的一个请求,告知传输完成,而这个应答也是对应 Server 的操作逻辑的。
http://127.0.0.1:8080/
Client: ('127.0.0.1', 64589)
User-agent: python-requests/2.22.0
Path: /
Form data:
实际上就是上述 server 代码写的应答,现在你应该知道要如何发送一个 multipart/form-data 的请求了吧,这实际上是和语言无关的,只需要用你手头的 socket 包装一下就可以实现。
做一些拓展内容
而关于这个 form-data 的封装过程,有很多优化要点和注意点。
先说 HTTP 数据包中的 boundary 和 mimetype 都是可以任意定义的,前者只要不和传输的内容有重合就行,所以我设置为 unix 时间字符串了,后者统一定义为 application/octet-stream 就可以了,因为这里不需要特别指定文件的解析逻辑操作,但如果你是写服务器的操作的话,则需要注意这些定义的区别。
class MultiPartForm(object):
"""Accumulate the data to be used when posting a form."""
def __init__(self):
self.form_fields = []
self.files = []
self.boundary = mimetools.choose_boundary()
return
def get_content_type(self):
return 'multipart/form-data; boundary=%s' % self.boundary
def add_field(self, name, value):
"""Add a simple field to the form data."""
self.form_fields.append((name, value))
return
def add_file(self, fieldname, filename, fileHandle, mimetype=None):
"""Add a file to be uploaded."""
body = fileHandle.read()
if mimetype is None:
mimetype = mimetypes.guess_type(filename)[0] or 'application/octet-stream'
self.files.append((fieldname, filename, mimetype, body))
return
def get_binary(self):
"""Return a binary buffer containing the form data, including attached files."""
part_boundary = '--' + self.boundary
binary = io.BytesIO()
needsCLRF = False
# Add the form fields
for name, value in self.form_fields:
if needsCLRF:
binary.write('
')
needsCLRF = True
block = [part_boundary,
'Content-Disposition: form-data; name="%s"' % name,
'',
value
]
binary.write('
'.join(block))
# Add the files to upload
for field_name, filename, content_type, body in self.files:
if needsCLRF:
binary.write('
')
needsCLRF = True
block = [part_boundary,
str('Content-Disposition: file; name="%s"; filename="%s"' %
(field_name, filename)),
'Content-Type: %s' % content_type,
''
]
binary.write('
'.join(block))
binary.write('
')
binary.write(body)
# add closing boundary marker,
binary.write('
--' + self.boundary + '--
')
return binary
在 MultiPartForm 类设计的时候就是一个 StringIO 的缓冲区数据包装,注意我前面说过的,每一次发起的 form-data 请求都要知道它的帧大小,包括传输的文件内容的长度,而 MultiPartForm 在 MicroPython 执行 form_buffer = form.get_binary().getvalue() 的时候就会内存不足 。
wCli = MicroWebCli('http://192.168.123.4:8080', 'POST')
#wCli = MicroWebCli('http://127.0.0.1:8080', 'POST')
print('POST %s' % wCli.URL)
form = MultiPartForm()
# Add a fake file
form.add_file(filepath, filename, fileHandle=open(filepath + filename, "rb"))
form_buffer = form.get_binary().getvalue()
wCli.OpenRequest(None, form.get_content_type(), str(len(form_buffer)))
wCli.RequestWriteData(form_buffer)
因为 MultiPartForm 在设计的时候没有考虑过内存不足的场合,它将预先载入所有文件的内容到 io.BytesIO() 对象中,然后获取长度只需要 len(get_binary()) 即可,这个的前提是机器内存足够大到放下这个 form-data ,但事实上在 MicroPython 中是不可能有这么多内存的,所以要改成边读边上传的模式,那么矛盾就出现了,我该如何在没有加载所有文件的情况下获取 form-data 的大小从而发起请求呢?
其实只需要改写两处地方,我们先看旧代码。
def add_file(self, fieldname, filename, fileHandle, mimetype=None):
"""Add a file to be uploaded."""
body = fileHandle.read()
if mimetype is None:
mimetype = mimetypes.guess_type(filename)[0] or 'application/octet-stream'
self.files.append((fieldname, filename, mimetype, body))
return
可以看到它此处是直接将整个文件都 read() 到 body 中,这在 MicroPython 中是不可能的,K210 通常只允申请 100K 的 BytesIO 对象,所以这里只需要提供文件的大小即可。
def add_file(self, fieldname, filename, mimetype=None):
"""Add a file to be uploaded."""
fileSize = os.stat(fieldname + filename)[6]
if mimetype is None:
mimetype = 'application/octet-stream'
self.files.append((fieldname, filename, mimetype, fileSize))
return
这是需要拆分两次过程,先动态计算 form-data 的 binary 的长度,再来提供操作函数,传递 socket.write 给 MultiPartForm 类代理执行 form.put_binary(wCli._write) 即可,所以改成如下接口。
form = MultiPartForm()
# form.add_field("form_field", "my awesome data")
# Add a fake file
form.add_file(filepath, filename)
wCli.OpenRequest(None, form.get_content_type(), str(form.len_binary()))
form.put_binary(wCli._write)
附赠 MicroPython 实现
惯例了,需要就直接拿去吧,记得结合 MicroWebCli 使用,有错误也都是一些 依赖库的错误,我都在 esp32 和 k210 的 micropython 上测试过辣。
class MultiPartForm(object):
"""Accumulate the data to be used when posting a form."""
def __init__(self):
self.form_fields = []
self.files = []
import time
self.boundary = str(time.time()) # .encode()
return
def get_content_type(self):
return 'multipart/form-data; boundary=%s' % self.boundary
def add_file(self, fieldname, filename, mimetype=None):
"""Add a file to be uploaded."""
fileSize = os.stat(fieldname + filename)[6]
if mimetype is None:
mimetype = 'application/octet-stream'
self.files.append((fieldname, filename, mimetype, fileSize))
return
def len_binary(self):
res = 0
part_boundary = ('--' + self.boundary).encode()
res += len(part_boundary)
needsCLRF = False
# Add the form fields
for name, value in self.form_fields:
if needsCLRF:
res += len(b'
')
needsCLRF = True
block = [part_boundary,
('Content-Disposition: form-data; name="%s"' % name).encode(),
b'',
value.encode()
]
res += len(b'
'.join(block))
# Add the files to upload
for fieldname, filename, content_type, fileSize in self.files:
if needsCLRF:
res += len(b'
')
needsCLRF = True
block = [part_boundary,
('Content-Disposition: file; name="%s"; filename="%s"' % (fieldname, filename)).encode(),
('Content-Type: %s' % content_type).encode(),
b'']
res += len(b'
'.join(block))
res += len(b'
')
res += fileSize
# add closing boundary marker,
res += len(('
--' + self.boundary + '--
'))
return res
def put_binary(self, binary_write):
"""Return a binary buffer containing the form data, including attached files."""
part_boundary = ('--' + self.boundary).encode()
# binary = io.BytesIO()
needsCLRF = False
# Add the form fields
for name, value in self.form_fields:
if needsCLRF:
binary_write('
')
needsCLRF = True
block = [part_boundary,
('Content-Disposition: form-data; name="%s"' % name).encode(),
b'',
value.encode()
]
binary_write(b'
'.join(block))
# Add the files to upload
for fieldname, filename, content_type, fileSize in self.files:
if needsCLRF:
binary_write(b'
')
needsCLRF = True
block = [part_boundary,
('Content-Disposition: file; name="%s"; filename="%s"' % (fieldname, filename)).encode(),
('Content-Type: %s' % content_type).encode(),
b'']
binary_write(b'
'.join(block))
binary_write(b'
')
#with open(fieldname + filename, 'rb') as fileObject:
#binary_write(fileObject.read())
with open(fieldname + filename, 'rb') as fileObject:
# binary_write(fileObject.read())
while True:
ch = fileObject.read(2048)
if not ch:
break
binary_write(ch)
# add closing boundary marker,
binary_write(('
--' + self.boundary + '--
').encode())
def test_http_upload():
gc.collect()
filename = 'F.zip'
#filename = 'CH340.zip'
filepath = '/sd/'
fileObject = open(filepath + filename, 'rb')
fileSize = os.stat(filepath + filename)[6]
print(filepath, fileObject, fileSize)
wCli = MicroWebCli('http://192.168.123.4:8080', 'POST')
#wCli = MicroWebCli('http://127.0.0.1:8080', 'POST')
print('POST %s' % wCli.URL)
form = MultiPartForm()
# form.add_field("form_field", "my awesome data")
# Add a fake file
form.add_file(filepath, filename)
wCli.OpenRequest(None, form.get_content_type(), str(form.len_binary()))
form.put_binary(wCli._write)
# while True:
# data = fileObject.read(1024)
# if not data:
# break
# wCli.RequestWriteData(data)
resp = wCli.GetResponse()
if resp.IsSuccess() :
o = resp.ReadContent()
print('POST success', o)
else :
print('POST return %d code (%s)' % (resp.GetStatusCode(), resp.GetStatusMessage()))
#test_http_download()
#test_http_get()
while True:
time.sleep(1)
bak = time.ticks()
try:
test_http_upload()
except Exception as E:
print(E)
print('total time ', (time.ticks() - bak) / 1000, ' s')
junhuanchen@qq.com 2020年5月23日留
注意:MicroWebCli 提供 application/x-www-form-urlencoded 的上传文件方法,需要配合服务器食用。