Python爬虫的简单入门(一)
简介
这一系列教学是基于Python的爬虫教学在此之前请确保你的电脑已经成功安装了Python(本教程使用的是Python3).爬虫想要学的精通是有点难度的,尤其是遇到反爬,多线程,分布式.我的博客适用于对Python爬虫的入门.会讲一些静态动态网页的爬取,及一些简单的验证码的处理.到时候通过爬虫爬取QQ音乐还是很轻松的.
爬虫一般分为三个部分爬取网页,解析网页,保存数据 此节主要讲通过requests获取网页代码
第三方库的安装
- requests库的安装
- 安装方法打开cmd输入
pip install requests回车
看一段简单的代码
import requests # 导入requests库
url = "https://www.baidu.com" # 目标网址
r = requests.get(url) # 调用requests的get方法发起get请求
print(r.status_code) # 打印状态码
print(r.text) # 打印获取到的网页代码
运行结果
200
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç¾åº¦ä¸ä¸ï¼ä½ å°±ç¥é</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=ç¾åº¦ä¸ä¸ class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ°é»</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>å°å¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§é¢</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>ç»å½</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">ç»å½</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æ´å¤äº§å</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å
³äºç¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç¨ç¾åº¦åå¿
读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æè§åé¦</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
这是我们获得的内容,可以看到第一行输出的是200,这就表明成功响应,更多关于HTTP状态码的知识请访问这里
但是这里还有两点奇怪的地方1.网页里面有奇怪的乱码 2.通过浏览器右键查看源代码可知百度的首页代码远比这个多
这也是爬虫十分常见的问题
先来解决第一个问题
乱码是因为编码不同引起的
我们可以打印一下网页的编码print(r.encoding)结果为ISO-8859-1,另外我们可以观察上面的网页源代码,发现里面有一句charset=utf-8.说明这个网页的编码为utf-8,两个编码不同当然会乱码.只要加上一句r.encoding = 'utf-8'就可以了,再次打印可得
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
这下就清楚多了.
但其实requests自带一个apparent_encoding的属性它可以理解为网页里的真编码.打印试试看print(r.apparent_encoding),得到结果utf-8和我们找到的结果一样.这样一来为了避免这种编码问题我们可以直接在代码中加上一句r.encoding = r.apparent_encoding
解决第二个问题
再此之前先讲讲浏览器的开发者工具
打开开发者工具
- 在浏览器的空白处右键选择检查
- 按一下键盘的
F12键
找到浏览器的标识信息
先点击network(火狐浏览器为网络)

我们发现底下什么也没有,接下来刷新网页
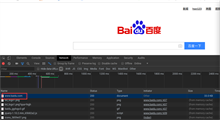
会出来很多的网址,这里我们找到百度的主页点击它,再选择右边的headers信息找到request headers下的User-Agent信息,这就是浏览器的标识信息

网站就是通过检测你的标识信息来判断你是正常的人访问还是程序访问,我们之前就是被检测到不是正常访问,所以返回了一个错误的网页信息
接下来我们要做的就是修改我们的头信息,让代码伪装成浏览器,具体操作如下
import requests # 导入requests库
url = "https://www.baidu.com" # 目标网址
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
} # 这里是复制刚刚网页上找到的浏览器标识信息,将他装换成字典,实际上整个request headers里的内容都可以复制进去,但是这里只用User-Agent就足够了
r = requests.get(url,headers=headers) # 调用requests的get方法发起get请求,添加headers参数(第一个headers为参数名称,第二个requests是上面定义的字典名称)
r.encoding = r.apparent_encoding # 矫正编码
print(r.text) # 打印获取到的网页代码
结果如下(下面内容很长,不予展示,有兴趣的可以去百度首页查看源代码)
至此就可以爬取大部分的网页源代码了,下一次介绍如何从源代码里提取我们想要的信息
给出静态网页爬取的代码框架(只做参考)
import requests
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
r = requests.get(url,headers=headers)
if r.status_code == 200:
r.encoding = r.apparent_encoding
print(r.text)
else:
print("访问失败")
其他
关于requests库的其他方法和参数常用的有post()方法,data参数后期会慢慢介绍