MMM介绍
MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序。MMM使用Perl语言开发,主要用来监控和管理MySQL Master-Master(双主)复制,可以说是mysql主主复制管理器。虽然叫做双主复制,但是业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,以加速在主主切换时刻备选主的预热,可以说MMM这套脚本程序一方面实现了故障切换的功能,另一方面其内部附加的工具脚本也可以实现多个slave的read负载均衡。关于mysql主主复制配置的监控、故障转移和管理的一套可伸缩的脚本套件(在任何时候只有一个节点可以被写入),这个套件也能对居于标准的主从配置的任意数量的从服务器进行读负载均衡,所以你可以用它来在一组居于复制的服务器启动虚拟ip,除此之外,它还有实现数据备份、节点之间重新同步功能的脚本。
MMM提供了自动和手动两种方式移除一组服务器中复制延迟较高的服务器的虚拟ip,同时它还可以备份数据,实现两节点之间的数据同步等。由于MMM无法完全的保证数据一致性,所以MMM适用于对数据的一致性要求不是很高,但是又想最大程度的保证业务可用性的场景。MySQL本身没有提供replication failover的解决方案,通过MMM方案能实现服务器的故障转移,从而实现mysql的高可用。对于那些对数据的一致性要求很高的业务,非常不建议采用MMM这种高可用架构。
从网上分享一个Mysql-MMM的内部架构图:
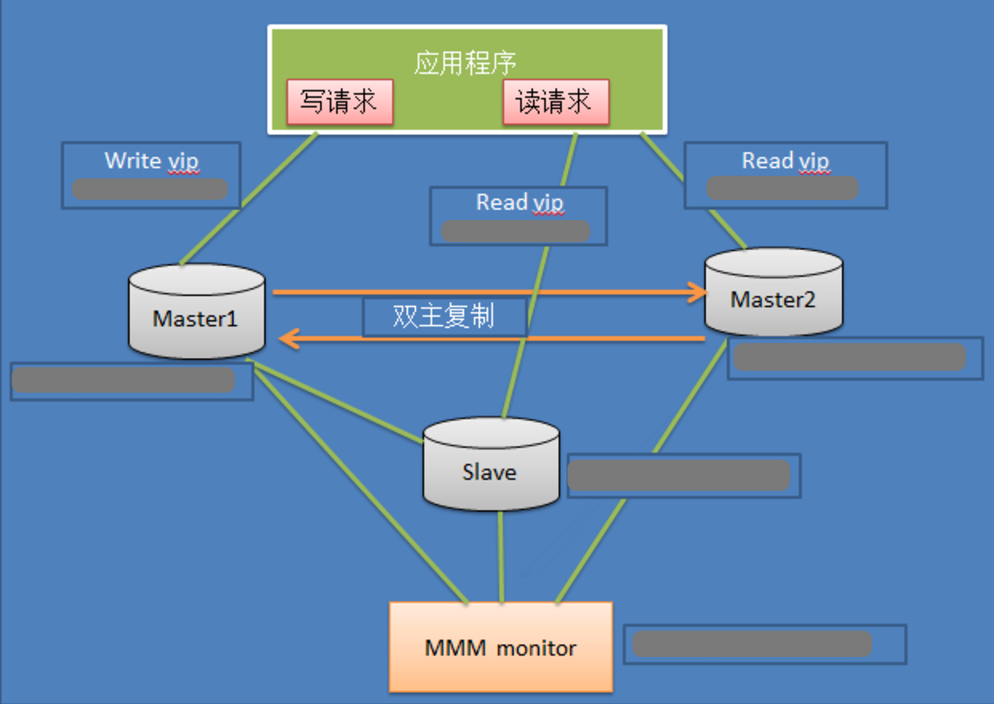
MySQL-MMM优缺点
优点:高可用性,扩展性好,出现故障自动切换,对于主主同步,在同一时间只提供一台数据库写操作,保证的数据的一致性。 缺点:Monitor节点是单点,可以结合Keepalived实现高可用。
MySQL-MMM工作原理
MMM(Master-Master replication managerfor Mysql,Mysql主主复制管理器)是一套灵活的脚本程序,基于perl实现,用来对mysql replication进行监控和故障迁移, 并能管理mysql Master-Master复制的配置(同一时间只有一个节点是可写的)。 mmm_mond:监控进程,负责所有的监控工作,决定和处理所有节点角色活动。此脚本需要在监管机上运行。 mmm_agentd:运行在每个mysql服务器上(Master和Slave)的代理进程,完成监控的探针工作和执行简单的远端服务设置。此脚本需要在被监管机上运行。 mmm_control:一个简单的脚本,提供管理mmm_mond进程的命令。 mysql-mmm的监管端会提供多个虚拟IP(VIP),包括一个可写VIP,多个可读VIP,通过监管的管理,这些IP会绑定在可用mysql之上,当某一台mysql宕机时,监管会将VIP迁移 至其他mysql。在整个监管过程中,需要在mysql中添加相关授权用户,以便让mysql可以支持监理机的维护。授权的用户包括一个mmm_monitor用户和一个mmm_agent用户,如果 想使用mmm的备份工具则还要添加一个mmm_tools用户。
MySQL-MMM高可用架构环境部署记录(自动切换读写分离)
0)机器配置信息
角色 ip地址 主机名字 server-id monitoring 182.48.115.233 mmm-monit - master1 182.48.115.236 db-master1 1 master2 182.48.115.237 db-master2 2 slave1 182.48.115.238 db-slave 3 业务中的服务ip(vip)信息如下所示: ip地址 角色 描述 182.48.115.234 write 应用程序连接该ip对主库进行写请求 182.48.115.235 read 应用程序连接该ip进行读请求 182.48.115.239 read 应用程序连接该ip进行读请求
1)配置/etc/hosts(所有机器都要操作)
[root@mmm-monit ~]# cat /etc/hosts ....... 182.48.115.233 mmm-monit 182.48.115.236 db-master1 182.48.115.237 db-master2 182.48.115.238 db-slave
2)首先在3台主机上安装mysql,部署复制环境
其中:182.48.115.236和182.48.115.237互为主从,182.48.115.238为1182.48.115.236的从 ........................................................................ mysql安装参考:http://www.cnblogs.com/kevingrace/p/6109679.html mysql主从/主主配置参考:http://www.cnblogs.com/kevingrace/p/6256603.html ........................................................................ ---------182.48.115.236的my.cnf添加配置--------- server-id = 1 log-bin = mysql-bin log_slave_updates = 1 auto-increment-increment = 2 auto-increment-offset = 1 ---------182.48.115.237的my.cnf添加配置--------- server-id = 2 log-bin = mysql-bin log_slave_updates = 1 auto-increment-increment = 2 auto-increment-offset = 2 ---------182.48.115.238的my.cnf添加配置--------- server-id = 3 log-bin = mysql-bin log_slave_updates = 1 注意: 上面的server-id不一定要按顺序来,只要没有重复即可。 然后182.48.115.236和182.48.115.237相互授权连接;182.48.115.236授权给182.48.115.238连接。 最后通过"change master...."做对应的主主和主从复制,具体操作步骤在此省略,可以参考上面给出的文档。
3)安装MMM(所有机器上都要执行)
.......先安装MMM所需要的Perl模块.......
[root@db-master1 ~]# vim install.sh //在所有机器上执行下面的安装脚本
#!/bin/bash
wget http://xrl.us/cpanm --no-check-certificate
mv cpanm /usr/bin
chmod 755 /usr/bin/cpanm
cat > /root/list << EOF
install Algorithm::Diff
install Class::Singleton
install DBI
install DBD::mysql
install File::Basename
install File::stat
install File::Temp
install Log::Dispatch
install Log::Log4perl
install Mail::Send
install Net::ARP
install Net::Ping
install Proc::Daemon
install Thread::Queue
install Time::HiRes
EOF
for package in `cat /root/list`
do
cpanm $package
done
[root@db-master1 ~]# chmod 755 install.sh
[root@db-master1 ~]# ./install.sh
.........下载mysql-mmm软件,在所有服务器上安装............
[root@db-master1 ~]# wget http://mysql-mmm.org/_media/:mmm2:mysql-mmm-2.2.1.tar.gz
[root@db-master1 ~]# mv :mmm2:mysql-mmm-2.2.1.tar.gz mysql-mmm-2.2.1.tar.gz
[root@db-master1 ~]# tar -zvxf mysql-mmm-2.2.1.tar.gz
[root@db-master1 ~]# cd mysql-mmm-2.2.1
[root@db-master1 mysql-mmm-2.2.1]# make install
mysql-mmm安装后的主要拓扑结构如下所示(注意:yum安装的和源码安装的路径有所区别):
/usr/lib/perl5/vendor_perl/5.8.8/MMM MMM使用的主要perl模块
/usr/lib/mysql-mmm MMM使用的主要脚本
/usr/sbin MMM使用的主要命令的路径
/etc/init.d/ MMM的agent和monitor启动服务的目录
/etc/mysql-mmm MMM配置文件的路径,默认所以的配置文件位于该目录下
/var/log/mysql-mmm 默认的MMM保存日志的位置
到这里已经完成了MMM的基本需求,接下来需要配置具体的配置文件,其中mmm_common.conf,mmm_agent.conf为agent端的配置文件,mmm_mon.conf为monitor端的配置文件。
4)配置agent端的配置文件,需要在db-master1 ,db-master2,db-slave上分别配置(配置内容一样)
先在db-master1主机上配置agent的mmm_common.conf文件(这个在所有机器上都要配置,包括monitor机器)
[root@db-master1 ~]# cd /etc/mysql-mmm/
[root@db-master1 mysql-mmm]# cp mmm_common.conf mmm_common.conf.bak
[root@db-master1 mysql-mmm]# vim mmm_common.conf
active_master_role writer
<host default>
cluster_interface eth0
pid_path /var/run/mmm_agentd.pid
bin_path /usr/lib/mysql-mmm/
replication_user slave //注意这个账号和下面一行的密码是在前面部署主主/主从复制时创建的复制账号和密码
replication_password slave@123
agent_user mmm_agent
agent_password mmm_agent
</host>
<host db-master1>
ip 182.48.115.236
mode master
peer db-master2
</host>
<host db-master2>
ip 182.48.115.237
mode master
peer db-master1
</host>
<host db-slave>
ip 182.48.115.238
mode slave
</host>
<role writer>
hosts db-master1, db-master2
ips 182.48.115.234
mode exclusive
</role>
<role reader>
hosts db-master2, db-slave
ips 182.48.115.235, 182.48.115.239
mode balanced
</role>
配置解释,其中:
replication_user 用于检查复制的用户
agent_user为agent的用户
mode标明是否为主或者备选主,或者从库。
mode exclusive主为独占模式,同一时刻只能有一个主
<role write>中hosts表示目前的主库和备选主的真实主机ip或者主机名,ips为对外提供的虚拟机ip地址
<role readr>中hosts代表从库真实的ip和主机名,ips代表从库的虚拟ip地址。
可以直接把mmm_common.conf从db-master1拷贝到db-master2、db-slave和mmm-monit三台主机的/etc/mysql-mmm下。
[root@db-master1 ~]# scp /etc/mysql-mmm/mmm_common.conf db-master2:/etc/mysql-mmm/
[root@db-master1 ~]# scp /etc/mysql-mmm/mmm_common.conf db-slave:/etc/mysql-mmm/
[root@db-master1 ~]# scp /etc/mysql-mmm/mmm_common.conf mmm-monit:/etc/mysql-mmm/
分别在db-master1,db-master2,db-slave三台主机的/etc/mysql-mmm配置mmm_agent.conf文件,分别用不同的字符标识。注意这个文件的this db1这行内容要修改
为各自的主机名。比如本环境中,db-master1要配置this db-master1,db-master2要配置为this db-master2,而db-slave要配置为this db-slave。
在db-master1(182.48.115.236)上:
[root@db-master1 ~]# vim /etc/mysql-mmm/mmm_agent.conf
include mmm_common.conf
this db-master1
在db-master2(182.48.115.237)上:
[root@db-master2 ~]# vim /etc/mysql-mmm/mmm_agent.conf
include mmm_common.conf
this db-master2
在db-slave(182.48.115.238)上:
[root@db-slave ~]# vim /etc/mysql-mmm/mmm_agent.conf
include mmm_common.conf
this db-slave
------------------------------------------------------------------------------------------------------
接着在mmm-monit(182.48.115.233)配置monitor的配置文件:
[root@mmm-monit ~]# cp /etc/mysql-mmm/mmm_mon.conf /etc/mysql-mmm/mmm_mon.conf.bak
[root@mmm-monit ~]# vim /etc/mysql-mmm/mmm_mon.conf
include mmm_common.conf
<monitor>
ip 182.48.115.233
pid_path /var/run/mysql-mmm/mmm_mond.pid
bin_path /usr/libexec/mysql-mmm
status_path /var/lib/mysql-mmm/mmm_mond.status
ping_ips 182.48.115.238,182.48.115.237,182.48.115.236
auto_set_online 10 //发现节点丢失,则过10秒进行切换
</monitor>
<host default>
monitor_user mmm_monitor
monitor_password mmm_monitor
</host>
debug 0
这里只在原有配置文件中的ping_ips添加了整个架构被监控主机的ip地址,而在<host default>中配置了用于监控的用户。
5)创建监控用户,这里需要创建3个监控用户
具体描述: 用户名 描述 权限 monitor user MMM的monitor端监控所有的mysql数据库的状态用户 REPLICATION CLIENT agent user 主要是MMM客户端用于改变的master的read_only状态用户 SUPER,REPLICATION CLIENT,PROCESS repl 用于复制的用户 REPLICATION SLAVE 在3台服务器(db-master1,db-master2,db-slave)进行授权,因为之前部署的主主复制,以及主从复制已经是ok的,所以这里在其中一台服务器执行就ok了,执行后 权限会自动同步到其它两台机器上。用于复制的账号之前已经有了,所以这里就授权两个账号。 在db-master1上进行授权操作: mysql> GRANT SUPER, REPLICATION CLIENT, PROCESS ON *.* TO 'mmm_agent'@'182.48.115.%' IDENTIFIED BY 'mmm_agent'; Query OK, 0 rows affected (0.00 sec) mysql> GRANT REPLICATION CLIENT ON *.* TO 'mmm_monitor'@'182.48.115.%' IDENTIFIED BY 'mmm_monitor'; Query OK, 0 rows affected (0.01 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) 然后在db-master2和db-slave两台机器上查看,发现上面在db-master1机器上授权的账号已经同步过来了!
6)启动agent和monitor服务
最后分别在db-master1,db-master2,db-slave上启动agent
[root@db-master1 ~]# /etc/init.d/mysql-mmm-agent start //将start替换成status,则查看agent进程起来了没?
Daemon bin: '/usr/sbin/mmm_agentd'
Daemon pid: '/var/run/mmm_agentd.pid'
Starting MMM Agent daemon... Ok
[root@db-master2 ~]# /etc/init.d/mysql-mmm-agent start
Daemon bin: '/usr/sbin/mmm_agentd'
Daemon pid: '/var/run/mmm_agentd.pid'
Starting MMM Agent daemon... Ok
[root@db-slave ~]# /etc/init.d/mysql-mmm-agent start
Daemon bin: '/usr/sbin/mmm_agentd'
Daemon pid: '/var/run/mmm_agentd.pid'
Starting MMM Agent daemon... Ok
接着在mmm-monit上启动monitor程序
[root@mmm-monit ~]# mkdir /var/run/mysql-mmm
[root@mmm-monit ~]# /etc/init.d/mysql-mmm-monitor start
Daemon bin: '/usr/sbin/mmm_mond'
Daemon pid: '/var/run/mmm_mond.pid'
Starting MMM Monitor daemon: Ok
........................................................................................................
如果monitor程序启动出现如下报错:
Daemon bin: '/usr/sbin/mmm_mond'
Daemon pid: '/var/run/mmm_mond.pid'
Starting MMM Monitor daemon: Base class package "Class::Singleton" is empty.
(Perhaps you need to 'use' the module which defines that package first,
or make that module available in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .).
at /usr/share/perl5/vendor_perl/MMM/Monitor/Agents.pm line 2
BEGIN failed--compilation aborted at /usr/share/perl5/vendor_perl/MMM/Monitor/Agents.pm line 2.
Compilation failed in require at /usr/share/perl5/vendor_perl/MMM/Monitor/Monitor.pm line 15.
BEGIN failed--compilation aborted at /usr/share/perl5/vendor_perl/MMM/Monitor/Monitor.pm line 15.
Compilation failed in require at /usr/sbin/mmm_mond line 28.
BEGIN failed--compilation aborted at /usr/sbin/mmm_mond line 28.
failed
解决办法:
[root@mmm-monit ~]# perl -MCPAN -e shell
...............................................
如是执行这个命令后,有如下报错:
Can't locate CPAN.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .).
BEGIN failed--compilation aborted.
解决:
[root@mmm-monit ~]# rpm -q perl-CPAN
package perl-CPAN is not installed
[root@mmm-monit ~]# yum install perl-CPAN
...............................................
执行上面的"perl -MCPAN -e shell"命令后,出现下面的安装命令
......
cpan[1]> install MIME::Entity //依次输入这些安装命令
cpan[2]> install MIME::Parser
cpan[3]> install Crypt::PasswdMD5
cpan[4]> install Term::ReadPassword
cpan[5]> install Crypt::CBC
cpan[6]> install Crypt::Blowfish
cpan[7]> install Daemon::Generic
cpan[8]> install DateTime
cpan[9]> install SOAP::Lite
或者直接执行下面的安装命令的命令也行:
[root@mmm-monit ~]# perl -MCPAN -e 'install HTML::Template'
[root@mmm-monit ~]# perl -MCPAN -e 'install MIME::Entity'
[root@mmm-monit ~]# perl -MCPAN -e 'install Crypt::PasswdMD5'
[root@mmm-monit ~]# perl -MCPAN -e 'install Term::ReadPassword'
[root@mmm-monit ~]# perl -MCPAN -e 'install Crypt::CBC'
[root@mmm-monit ~]# perl -MCPAN -e 'install Crypt::Blowfish'
[root@mmm-monit ~]# perl -MCPAN -e 'install Daemon::Generic'
[root@mmm-monit ~]# perl -MCPAN -e 'install DateTime'
[root@mmm-monit ~]# perl -MCPAN -e 'install SOAP::Lite'
............................................................................................................
monitor进程启动后,如下查看,发现进程并没有起来!
[root@mmm-monit ~]# /etc/init.d/mysql-mmm-monitor status
Daemon bin: '/usr/sbin/mmm_mond'
Daemon pid: '/var/run/mmm_mond.pid'
Checking MMM Monitor process: not running.
解决办法:
将mmm_mon.conf的debug模式开启设为1,即打开debug模式,然后执行:
[root@mmm-monit ~]# /etc/init.d/mysql-mmm-monitor start
.......
open2: exec of /usr/libexec/mysql-mmm/monitor/checker ping_ip failed at /usr/share/perl5/vendor_perl/MMM/Monitor/Checker.pm line 143.
2017/06/01 20:16:02 WARN Checker 'ping_ip' is dead!
2017/06/01 20:16:02 INFO Spawning checker 'ping_ip'...
2017/06/01 20:16:02 DEBUG Core: reaped child 17439 with exit 65280
原因是mmm_mon.conf文件里check的bin_path路径写错了
[root@mmm-monit ~]# cat /etc/mysql-mmm/mmm_mon.conf|grep bin_path
bin_path /usr/libexec/mysql-mmm
将上面的bin_path改为/usr/lib/mysql-mmm 即可解决!即:
[root@mmm-monit ~]# cat /etc/mysql-mmm/mmm_mon.conf|grep bin_path
bin_path /usr/lib/mysql-mmm
接着再次启动monitor进程
[root@mmm-monit ~]# /etc/init.d/mysql-mmm-monitor start
.......
FATAL Couldn't open status file '/var/lib/mysql-mmm/mmm_mond.status': Starting up without status inf
.......
Error in tempfile() using template /var/lib/mysql-mmm/mmm_mond.statusXXXXXXXXXX: Parent directory (/var/lib/mysql-mmm/) does not exist at /usr/share/perl5/vendor_perl/MMM/Monitor/Agents.pm line 158.
Perl exited with active threads:
6 running and unjoined
0 finished and unjoined
0 running and detached
原因是mmm_mon.conf文件里check的status_path路径写错了
[root@mmm-monit ~]# cat /etc/mysql-mmm/mmm_mon.conf |grep status_path
status_path /var/lib/mysql-mmm/mmm_mond.status
将上面的status_path改为/var/lib/misc//mmm_mond.status 即可解决!即:
[root@mmm-monit ~]# cat /etc/mysql-mmm/mmm_mon.conf|grep status_path
status_path /var/lib/misc/mmm_mond.status
然后再次启动monitor进程
[root@mmm-monit ~]# /etc/init.d/mysql-mmm-monitor restart
........
2017/06/01 20:57:14 DEBUG Sending command 'SET_STATUS(ONLINE, reader(182.48.115.235), db-master1)' to db-master2 (182.48.115.237:9989)
2017/06/01 20:57:14 DEBUG Received Answer: OK: Status applied successfully!|UP:885492.82
2017/06/01 20:57:14 DEBUG Sending command 'SET_STATUS(ONLINE, writer(182.48.115.234), db-master1)' to db-master1 (182.48.115.236:9989)
2017/06/01 20:57:14 DEBUG Received Answer: OK: Status applied successfully!|UP:65356.14
2017/06/01 20:57:14 DEBUG Sending command 'SET_STATUS(ONLINE, reader(182.48.115.239), db-master1)' to db-slave (182.48.115.238:9989)
2017/06/01 20:57:14 DEBUG Received Answer: OK: Status applied successfully!|UP:945625.05
2017/06/01 20:57:15 DEBUG Listener: Waiting for connection...
2017/06/01 20:57:17 DEBUG Sending command 'SET_STATUS(ONLINE, reader(182.48.115.235), db-master1)' to db-master2 (182.48.115.237:9989)
2017/06/01 20:57:17 DEBUG Received Answer: OK: Status applied successfully!|UP:885495.95
2017/06/01 20:57:17 DEBUG Sending command 'SET_STATUS(ONLINE, writer(182.48.115.234), db-master1)' to db-master1 (182.48.115.236:9989)
2017/06/01 20:57:17 DEBUG Received Answer: OK: Status applied successfully!|UP:65359.27
2017/06/01 20:57:17 DEBUG Sending command 'SET_STATUS(ONLINE, reader(182.48.115.239), db-master1)' to db-slave (182.48.115.238:9989)
2017/06/01 20:57:17 DEBUG Received Answer: OK: Status applied successfully!|UP:945628.17
2017/06/01 20:57:18 DEBUG Listener: Waiting for connection...
.........
只要上面在启动过程中的check检查中没有报错信息,并且有successfully信息,则表示monitor进程正常了。
[root@mmm-monit ~]# ps -ef|grep monitor
root 30651 30540 0 20:59 ? 00:00:00 perl /usr/lib/mysql-mmm/monitor/checker ping_ip
root 30654 30540 0 20:59 ? 00:00:00 perl /usr/lib/mysql-mmm/monitor/checker mysql
root 30656 30540 0 20:59 ? 00:00:00 perl /usr/lib/mysql-mmm/monitor/checker ping
root 30658 30540 0 20:59 ? 00:00:00 perl /usr/lib/mysql-mmm/monitor/checker rep_backlog
root 30660 30540 0 20:59 ? 00:00:00 perl /usr/lib/mysql-mmm/monitor/checker rep_threads
那么,最终mmm_mon.cnf文件的配置如下:
[root@mmm-monit ~]# cat /etc/mysql-mmm/mmm_mon.conf
include mmm_common.conf
<monitor>
ip 182.48.115.233
pid_path /var/run/mysql-mmm/mmm_mond.pid
bin_path /usr/lib/mysql-mmm
status_path /var/lib/misc/mmm_mond.status
ping_ips 182.48.115.238,182.48.115.237,182.48.115.236
auto_set_online 10
</monitor>
<host default>
monitor_user mmm_monitor
monitor_password mmm_monitor
</host>
debug 1
[root@mmm-monit ~]# ll /var/lib/misc/mmm_mond.status
-rw-------. 1 root root 121 6月 1 21:06 /var/lib/misc/mmm_mond.status
[root@mmm-monit ~]# ll /var/run/mysql-mmm/mmm_mond.pid
-rw-r--r--. 1 root root 5 6月 1 20:59 /var/run/mysql-mmm/mmm_mond.pid
-----------------------------------------------------------
其中agent的日志存放在/var/log/mysql-mmm/mmm_agentd.log,monitor日志放在/var/log/mysql-mmm/mmm_mond.log,
启动过程中有什么问题,通常日志都会有详细的记录。
7)在monitor主机上检查集群主机的状态
[root@mmm-monit ~]# mmm_control checks all db-master2 ping [last change: 2017/06/01 20:59:39] OK db-master2 mysql [last change: 2017/06/01 20:59:39] OK db-master2 rep_threads [last change: 2017/06/01 20:59:39] OK db-master2 rep_backlog [last change: 2017/06/01 20:59:39] OK: Backlog is null db-master1 ping [last change: 2017/06/01 20:59:39] OK db-master1 mysql [last change: 2017/06/01 20:59:39] OK db-master1 rep_threads [last change: 2017/06/01 20:59:39] OK db-master1 rep_backlog [last change: 2017/06/01 20:59:39] OK: Backlog is null db-slave ping [last change: 2017/06/01 20:59:39] OK db-slave mysql [last change: 2017/06/01 20:59:39] OK db-slave rep_threads [last change: 2017/06/01 20:59:39] OK db-slave rep_backlog [last change: 2017/06/01 20:59:39] OK: Backlog is null
8)在monitor主机上检查集群环境在线状况
[root@mmm-monit ~]# mmm_control show
db-master1(182.48.115.236) master/ONLINE. Roles: writer(182.48.115.234)
db-master2(182.48.115.237) master/ONLINE. Roles: reader(182.48.115.235)
db-slave(182.48.115.238) slave/ONLINE. Roles: reader(182.48.115.239)
然后到mmm agent机器上查看,就会发现vip已经绑定了
[root@db-master1 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:5f:58:dc brd ff:ff:ff:ff:ff:ff
inet 182.48.115.236/27 brd 182.48.115.255 scope global eth0
inet 182.48.115.234/32 scope global eth0
inet6 fe80::5054:ff:fe5f:58dc/64 scope link
valid_lft forever preferred_lft forever
[root@db-master2 mysql-mmm]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:1b:6e:53 brd ff:ff:ff:ff:ff:ff
inet 182.48.115.237/27 brd 182.48.115.255 scope global eth0
inet 182.48.115.235/32 scope global eth0
inet6 fe80::5054:ff:fe1b:6e53/64 scope link
valid_lft forever preferred_lft forever
[root@db-slave ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:ca:d5:f8 brd ff:ff:ff:ff:ff:ff
inet 182.48.115.238/27 brd 182.48.115.255 scope global eth0
inet 182.48.115.239/27 brd 182.48.115.255 scope global secondary eth0:1
inet6 fe80::5054:ff:feca:d5f8/64 scope link
valid_lft forever preferred_lft forever
从上面输出信息中可以看出,虚拟ip已经绑定到各agent上了。其中:
182.48.115.234顺利添加到182.48.115.236上作为主对外提供写服务
182.48.115.235顺利添加到182.48.115.237上作为主对外提供读服务
182.48.115.239顺利添加到182.48.115.238上作为主对外提供读服务
9)online(上线)所有主机
这里主机已经在线了,如果没有在线,可以使用下面的命令将相关主机online [root@mmm-monit ~]# mmm_control set_online db-master1 OK: This host is already ONLINE. Skipping command. [root@mmm-monit ~]# mmm_control set_online db-master2 OK: This host is already ONLINE. Skipping command. [root@mmm-monit ~]# mmm_control set_online db-slave OK: This host is already ONLINE. Skipping command. 提示主机已经在线,已经跳过命令执行了。到这里整个集群就配置完成了。
--------------------------------------------------MMM高可用测试-------------------------------------------------------
已经完成高可用环境的搭建了,下面我们就可以做MMM的HA测试咯。
首先查看整个集群的状态,可以看到整个集群状态正常。
[root@mmm-monit ~]# mmm_control show
db-master1(182.48.115.236) master/ONLINE. Roles: writer(182.48.115.234)
db-master2(182.48.115.237) master/ONLINE. Roles: reader(182.48.115.235)
db-slave(182.48.115.238) slave/ONLINE. Roles: reader(182.48.115.239)
1)模拟db-master2(182.48.115.237)宕机,手动停止mysql服务.
[root@db-master2 ~]# /etc/init.d/mysql stop
Shutting down MySQL.... SUCCESS!
在mmm-monit机器上观察monitor日志
[root@mmm-monit ~]# tail -f /var/log/mysql-mmm/mmm_mond.log
.........
2017/06/01 21:28:17 FATAL State of host 'db-master2' changed from ONLINE to HARD_OFFLINE (ping: OK, mysql: not OK)
重新查看mmm集群的最新状态:
[root@mmm-monit ~]# mmm_control show
db-master1(182.48.115.236) master/ONLINE. Roles: writer(182.48.115.234)
db-master2(182.48.115.237) master/HARD_OFFLINE. Roles:
db-slave(182.48.115.238) slave/ONLINE. Roles: reader(182.48.115.235), reader(182.48.115.239)
发现之前添加到db-master2对外提供读服务器的虚拟ip,即182.48.115.235已经漂移到db-slave机器上了.
[root@db-slave ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:ca:d5:f8 brd ff:ff:ff:ff:ff:ff
inet 182.48.115.238/27 brd 182.48.115.255 scope global eth0
inet 182.48.115.235/32 scope global eth0
inet 182.48.115.239/27 brd 182.48.115.255 scope global secondary eth0:1
inet6 fe80::5054:ff:feca:d5f8/64 scope link
valid_lft forever preferred_lft forever
测试mysql数据同步:
虽然db-master2机器的mysql服务关闭,但是由于它的vip漂移到db-slave机器上了,所以此时db-master1和db-slave这个时候是主从复制关系。
在db-master1数据库里更新数据,会自动更新到db-slave数据库里。
------------------
接着重启db-master2的mysql服务,可以看到db-master2由HARD_OFFLINE转到AWAITING_RECOVERY。这时候db-master2再次接管读请求。
[root@db-master2 ~]# /etc/init.d/mysql start
Starting MySQL.. SUCCESS!
在mmm-monit机器上观察monitor日志
[root@mmm-monit ~]# tail -f /var/log/mysql-mmm/mmm_mond.log
.........
2017/06/01 21:36:00 FATAL State of host 'db-master2' changed from HARD_OFFLINE to AWAITING_RECOVERY
2017/06/01 21:36:12 FATAL State of host 'db-master2' changed from AWAITING_RECOVERY to ONLINE because of auto_set_online(10 seconds). It was in state AWAITING_RECOVERY for 12 seconds
[root@mmm-monit ~]# mmm_control show
db-master1(182.48.115.236) master/ONLINE. Roles: writer(182.48.115.234)
db-master2(182.48.115.237) master/ONLINE. Roles: reader(182.48.115.235)
db-slave(182.48.115.238) slave/ONLINE. Roles: reader(182.48.115.239)
[root@db-master2 mysql-mmm]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:1b:6e:53 brd ff:ff:ff:ff:ff:ff
inet 182.48.115.237/27 brd 182.48.115.255 scope global eth0
inet 182.48.115.235/32 scope global eth0
inet6 fe80::5054:ff:fe1b:6e53/64 scope link
valid_lft forever preferred_lft forever
发现之前的vip资源又回到了db-master2机器上,db-master2重新接管了服务。并且db-master2恢复后,在故障期间更新的数据也会自动和其它两台机器同步!
---------------------------------------------------------------------------------------------------
2)模拟db-master1主库宕机,手动关闭mysql服务
[root@db-master1 ~]# /etc/init.d/mysql stop
Shutting down MySQL.... SUCCESS!
在mmm-monit机器上观察monitor日志
[root@mmm-monit ~]# tail -f /var/log/mysql-mmm/mmm_mond.log
.........
2017/06/01 21:43:36 FATAL State of host 'db-master1' changed from ONLINE to HARD_OFFLINE (ping: OK, mysql: not OK)
查看mmm集群状态:
[root@mmm-monit ~]# mmm_control show
db-master1(182.48.115.236) master/HARD_OFFLINE. Roles:
db-master2(182.48.115.237) master/ONLINE. Roles: reader(182.48.115.235), writer(182.48.115.234)
db-slave(182.48.115.238) slave/ONLINE. Roles: reader(182.48.115.239)
从上面可以发现,db-master1由以前的ONLINE转化为HARD_OFFLINE,移除了写角色,因为db-master2是备选主,所以接管了写角色,db-slave指向新的主库db-master2,
应该说db-slave实际上找到了db-master2的sql现在的位置,即db-master2的show master返回的值,然后直接在db-slave上change master to到db-master2。
db-master2机器上可以发现,db-master1对外提供写服务的vip漂移过来了
[root@db-master2 mysql-mmm]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:1b:6e:53 brd ff:ff:ff:ff:ff:ff
inet 182.48.115.237/27 brd 182.48.115.255 scope global eth0
inet 182.48.115.235/32 scope global eth0
inet 182.48.115.234/32 scope global eth0
inet6 fe80::5054:ff:fe1b:6e53/64 scope link
valid_lft forever preferred_lft forever
这个时候,在db-master2数据库里更新数据,db-slave数据库会自动同步过去。
------------------------
接着重启db-master1的mysql
[root@db-master1 ~]# /etc/init.d/mysql start
Starting MySQL.. SUCCESS!
在mmm-monit机器上观察monitor日志
[root@mmm-monit ~]# tail -f /var/log/mysql-mmm/mmm_mond.log
.........
2017/06/01 21:52:14 FATAL State of host 'db-master1' changed from HARD_OFFLINE to AWAITING_RECOVERY
再次查看mmm集群状态(发现写服务的vip转移到db-master2上了):
[root@mmm-monit ~]# mmm_control show
db-master1(182.48.115.236) master/ONLINE. Roles:
db-master2(182.48.115.237) master/ONLINE. Roles: reader(182.48.115.235), writer(182.48.115.234)
db-slave(182.48.115.238) slave/ONLINE. Roles: reader(182.48.115.239)
发现db-master1虽然恢复了,并已经上线在集群中,但是其之前绑定的写服务的vip并没有从db-master2上转移回来,即db-master1恢复后没有重新接管服务。
只有等到db-master2发生故障时,才会把182.48.115.234的写服务的vip转移到db-master1上,同时把182.48.115.235的读服务的vip转移到db-slave
机器上(然后db-master2恢复后,就会把转移到db-slave上的182.48.115.235的读服务的vip再次转移回来)。
---------------------------------------------------------------------------------------------------
再接着模拟db-slave从库宕机,手动关闭mysql服务
[root@db-slave ~]# /etc/init.d/mysql stop
Shutting down MySQL.. [确定]
在mmm-monit机器上观察monitor日志
[root@mmm-monit ~]# tail -f /var/log/mysql-mmm/mmm_mond.log
.........
2017/06/01 22:42:24 FATAL State of host 'db-slave' changed from ONLINE to HARD_OFFLINE (ping: OK, mysql: not OK)
查看mmm集群的最新状态:
[root@mmm-monit ~]# mmm_control show
db-master1(182.48.115.236) master/ONLINE. Roles: writer(182.48.115.234)
db-master2(182.48.115.237) master/ONLINE. Roles: reader(182.48.115.235), reader(182.48.115.239)
db-slave(182.48.115.238) slave/HARD_OFFLINE. Roles:
发现db-slave发生故障后,其读服务的182.48.115.239的vip转移到db-master2上了。
[root@db-master2 mysql-mmm]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:1b:6e:53 brd ff:ff:ff:ff:ff:ff
inet 182.48.115.237/27 brd 182.48.115.255 scope global eth0
inet 182.48.115.235/32 scope global eth0
inet 182.48.115.239/32 scope global eth0
inet6 fe80::5054:ff:fe1b:6e53/64 scope link
当db-slave恢复后,读服务的vip还是再次转移回来,即重新接管服务。并且故障期间更新的数据会自动同步回来。
需要注意:
db-master1,db-master2,db-slave之间为一主两从的复制关系,一旦发生db-master2,db-slave延时于db-master1时,这个时刻db-master1 mysql宕机,
db-slave将会等待数据追上db-master1后,再重新指向新的主db-master2,进行change master to db-master2操作,在db-master1宕机的过程中,一旦db-master2
落后于db-master1,这时发生切换,db-master2变成了可写状态,数据的一致性将会无法保证。
总结:MMM不适用于对数据一致性要求很高的环境。但是高可用完全做到了。