今天咋们来看看网易云赵雷的歌曲歌词,并做一个词云图。这篇文章可以学习到什么是词云,爬虫的基本流程,简单的可视化操作
@
一 什么是词云
可视化有很多种,好的数据可视化,可以使得数据分析的结果更加通俗易通。"词云"属于可视化的一种,它会根据关键词的出现频率生成一幅图,这样可以让我们一眼就知道其主要要点。比如下面

二 制作词云的步骤
1 第一步收集需要可视化的内容。
内容可以是文章内容,当然也可以是爬虫的内容。这里我们先使用NAB球星科比的材料作为内容。
2 安装词云库
wordcloud,安装方法如下(前提是电脑已经有了python环境和一些基础库哟,建议可以装个Anaconda,这样就少了很多依赖包的麻烦哟)
- pip install wordcloud
- pip install jieba--------中文库,因为我想展示中文内容
- pip install PIL----------图像处理库
- pip install matplotlib-----图像展示库
3 介绍下jieba中文库和下面会用到的wordcloud常用参数
(1) jieba简介
- jieba中文库
它是python中文分词组件,具有三种分词模式- 精确模式,试图将句子最精确的切开,比较适合文本分析
- 全模式,把句子中所有可以成词的都扫描出来,速度很快,但是不能解决歧义
- 搜索引擎模式,在精确模式的基础上对长词进行再次切分,适合用于搜索引擎分词
- 支持繁体分词
- 支持自定义词典
- MIT授权协议
(2) jieba API
jieba.cut 接受三个参数
需要分词的字符串,可以是中文
- cut_all bollean类型的参数,用来控制是否采用全模式
- HMM参数用来控制是否采用HMM模型(隐马模型--后续进行相关学习)
jieba.cut_for_search 接受两个参数
需要分词的字符串,可以为中文
HMM参数用来控制是否采用HMM模型
它与jieba.cut 的最大区别就在于分词更加细腻,且会将全部的可能性输出,因此没有cut_all 参数
4 科比词云图制作测试代码1
#-*- coding:utf-8 -*
f='科比的职业生涯随湖人队5夺NBA总冠军(2000年-2002年、2009年-2010年);
荣膺1次常规赛MVP(2007-08赛季),2次总决赛MVP(2009年-2010年),
4次全明星赛MVP(2002年、2007年、2009年与2011年),
与鲍勃·佩蒂特并列NBA历史第一;共18次入选NBA全明星阵容,15次入选NBA最佳阵容,12次入选NBA最佳防守阵容'
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
from PIL import Image as image
import numpy as np
#生成词云
def create_word_cloud(f):
print('根据词频计算词云')
text = " ".join(jieba.cut(f,cut_all=False, HMM=True))
wc = WordCloud(
font_path="./SimHei.ttf",#设置字体 针对中文的情况需要设置中文字体,否则会乱码
max_words=100,# 设置最大的字数
width=2000,#设置画布的宽度
height=1200,#设置画布的高度
)
wordcloud=wc.generate(text)
#写词云图片
wordcloud.to_file("wordcloud.jpg")
#显示词云文件
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
create_word_cloud(f)
```python
结果显示:

三 案例 网易云歌手房东的猫词云图
1 整体流程图
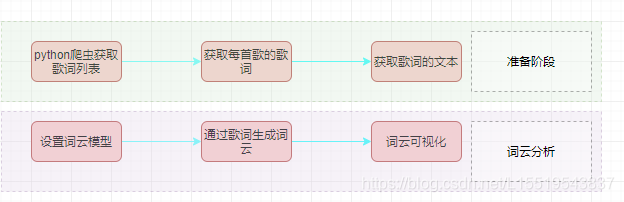
2 爬取+词云制作
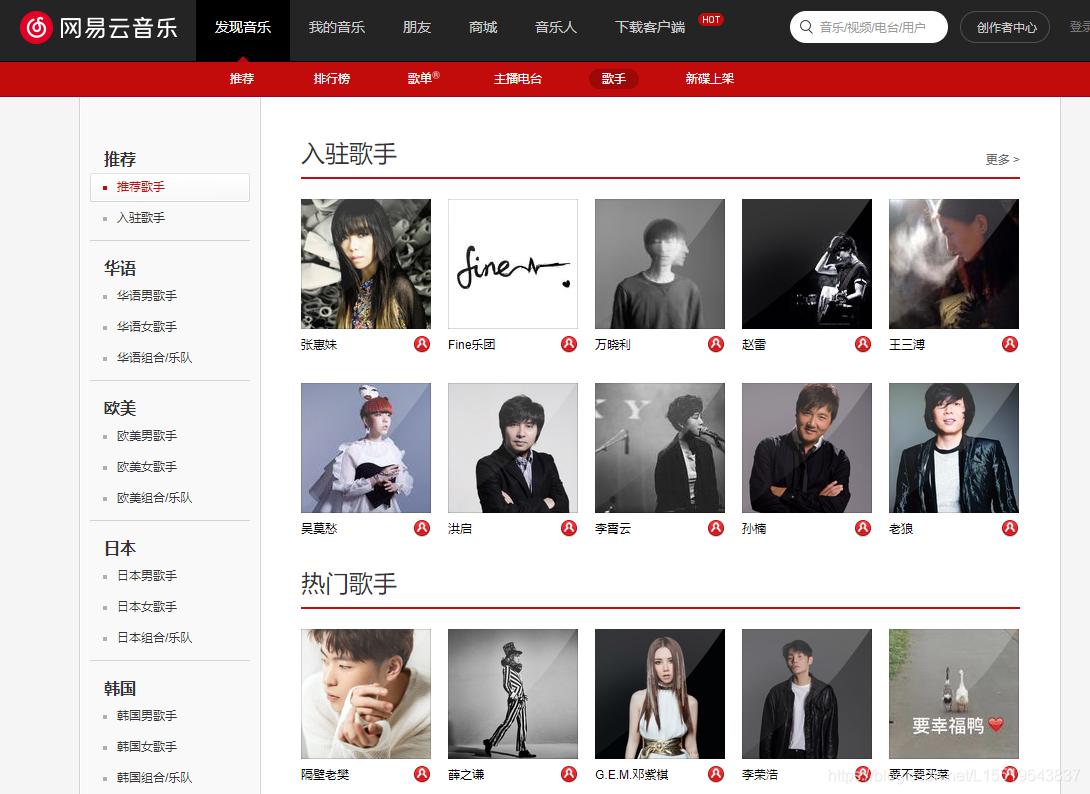
(1) 我们先查看网易云的歌词API接口需要什么常用接口。发现需要一个ID。所以第一步访问url进入歌手界面,寻找规律得出歌手ID。
-
进入歌手页面 歌手页面
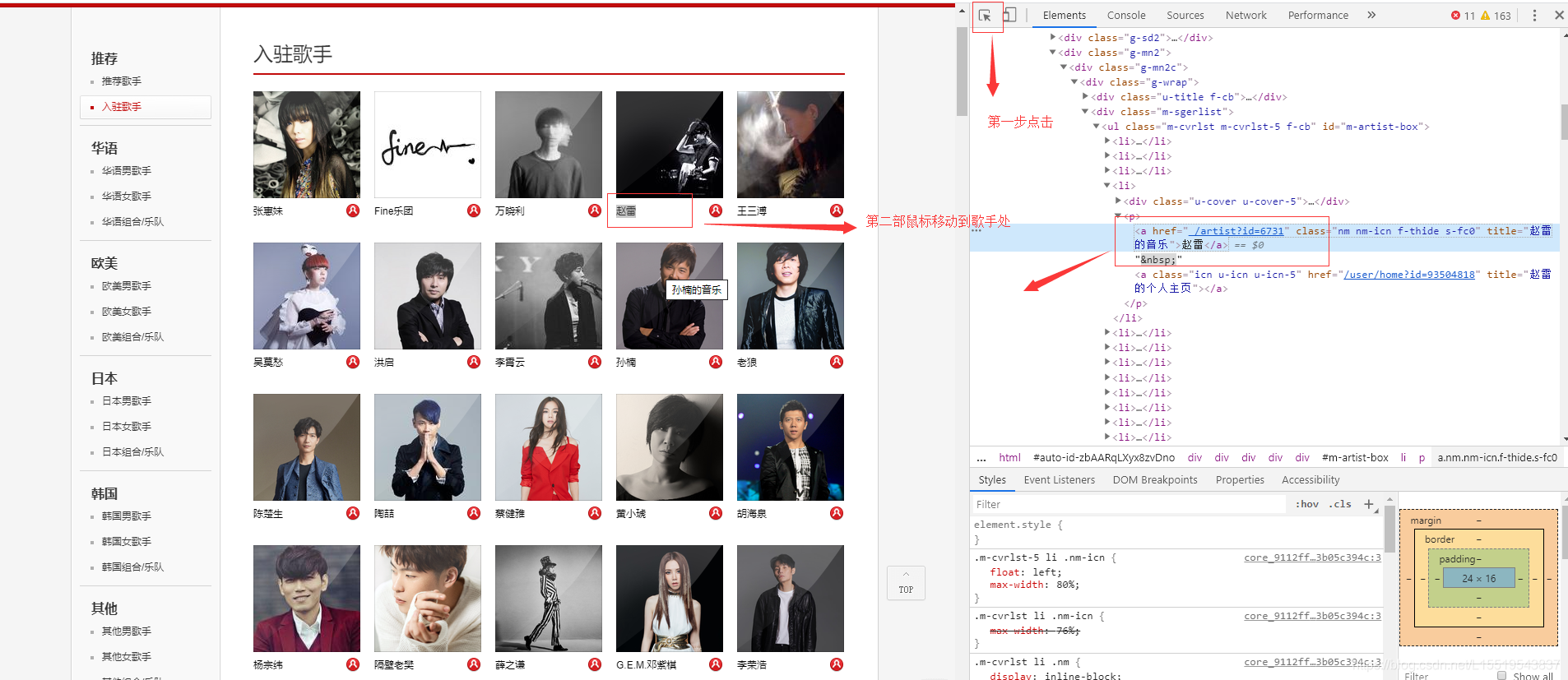
-
点击赵雷歌曲页面 赵雷歌曲页面。这里可以多点击几个歌手,就会发现不同的歌手页面不同的地方在URL后面的ID不同,
-
点击歌手名字,进入歌手页面,选中热门50首中div的id属性
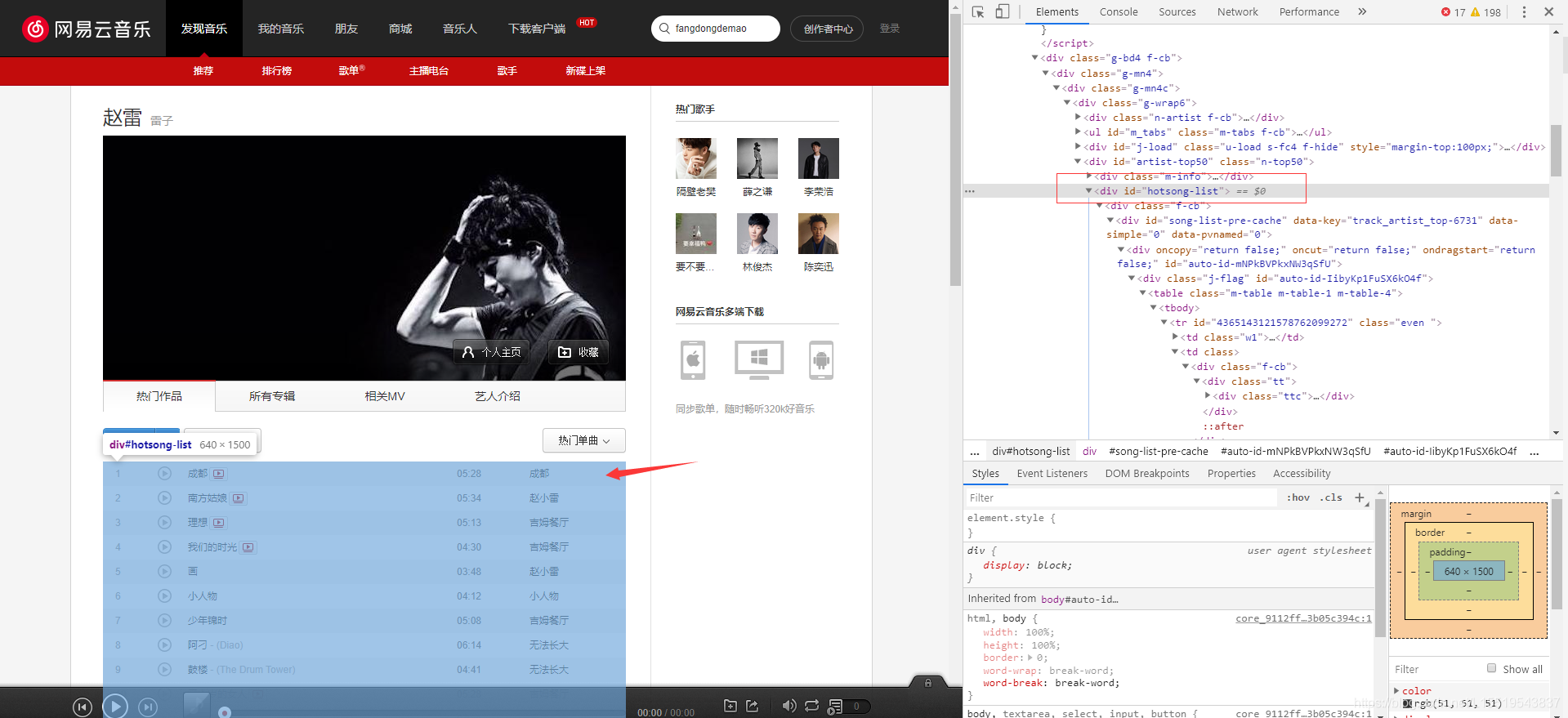
-
因为我们需要每首歌的歌词,所以需要寻找歌曲的歌词连接,通常为a标签,所以我们往下看,用xpath解析出所有的a标签
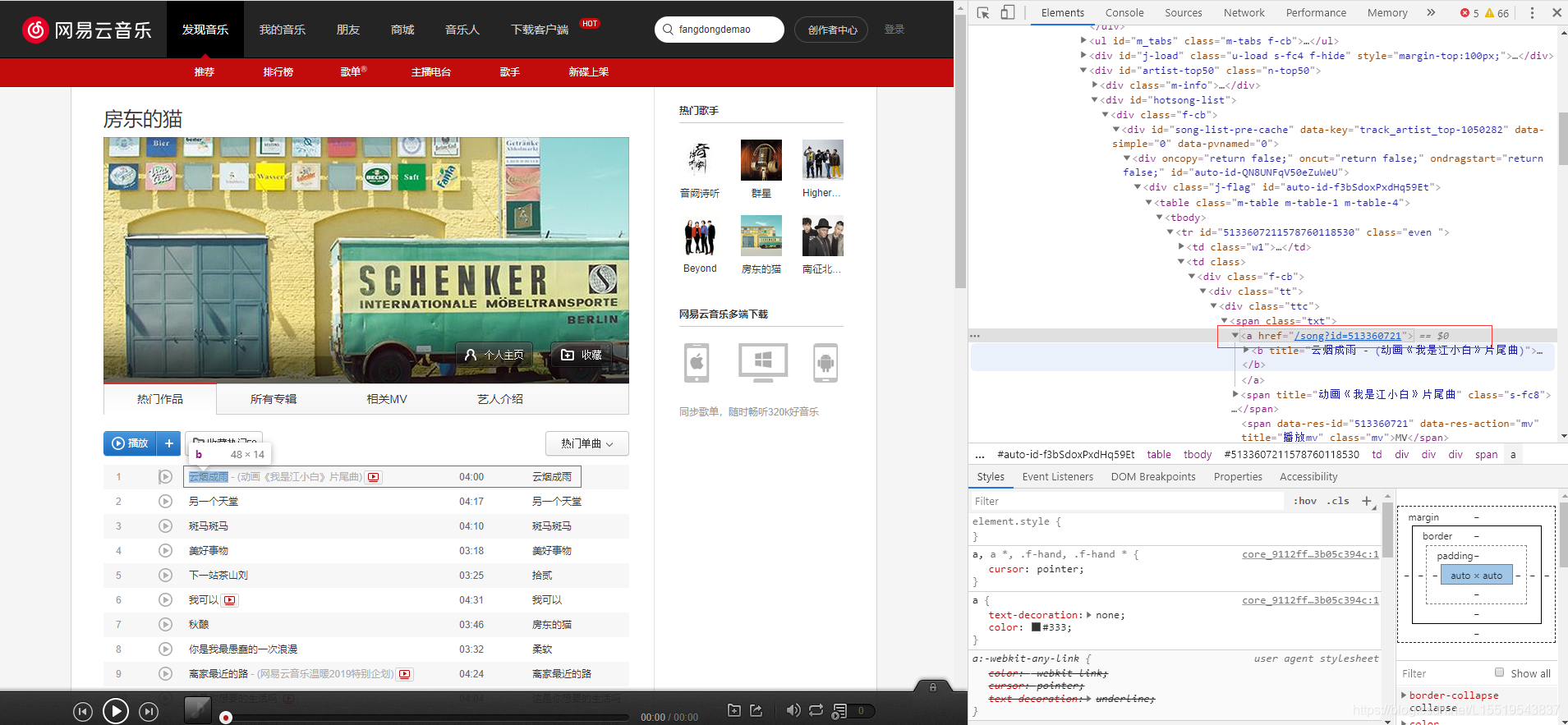
def get_songs(artist_id):
page_url = 'https://music.163.com/artist?id=' + artist_id
# 获取网页HTML
res = requests.request('GET', page_url, headers=headers)
# 用XPath解析 前50首热门歌曲
html = etree.HTML(res.text)
href_xpath = "//*[@id='hotsong-list']//a/@href"
name_xpath = "//*[@id='hotsong-list']//a/text()"#获取
hrefs = html.xpath(href_xpath)
names = html.xpath(name_xpath)
# 设置热门歌曲的ID,歌曲名称
song_ids = []
song_names = []
for href, name in zip(hrefs, names):
song_ids.append(href[9:])
song_names.append(name)
print(href, ' ', name)
return song_ids, song_names
(2) 现在拼接我们的爬取歌词的url。http://music.163.com/api/song/lyric?os=pc&id=' + song_id + '&lv=-1&kv=-1&tv=-1'
# 获取每首歌歌词
for (song_id, song_name) in zip(song_ids, song_names):
# 歌词API URL
lyric_url = 'http://music.163.com/api/song/lyric?os=pc&id=' + song_id + '&lv=-1&kv=-1&tv=-1'
lyric = get_song_lyric(headers, lyric_url)
all_word = all_word + ' ' + lyric
print(song_name)
(3) 去掉部分停用词比如作词,编曲等词语
# 去掉停用词
def remove_stop_words(f):
stop_words = ['作词', '作曲', '编曲', '人声', 'Vocal', '弦乐', 'Keyboard', '键盘', '编辑', '助理', 'Assistants', 'Mixing', 'Editing', 'Recording', '音乐', '制作', 'Producer', '发行', 'produced', 'and', 'distributed']
for stop_word in stop_words:
f = f.replace(stop_word, '')
return f
(4)整体代码
import requests
import re
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
import PIL.Image as image
from lxml import etree
headers = {
'Referer' :'http://music.163.com',
'Host' :'music.163.com',
'Accept' :'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent':'Chrome/10'
}
# 得到某一首歌的歌词
def get_song_lyric(headers, lyric_url):
res = requests.request('GET', lyric_url, headers=headers)
if 'lrc' in res.json():
lyric = res.json()['lrc']['lyric']
new_lyric = re.sub(r'[d:.[]]','',lyric)#去掉[]中的数字信息
return new_lyric
else:
return ''
print(res.json())
# 去掉停用词
def remove_stop_words(f):
stop_words = ['作词', '作曲', '编曲', '人声', 'Vocal', '弦乐', 'Keyboard', '键盘', '编辑', '助理', 'Assistants', 'Mixing', 'Editing', 'Recording', '音乐', '制作', 'Producer', '发行', 'produced', 'and', 'distributed']
for stop_word in stop_words:
f = f.replace(stop_word, '')
return f
# 生成词云
def create_word_cloud(f):
print('根据词频,开始生成词云!')
f = remove_stop_words(f)
cut_text = " ".join(jieba.cut(f,cut_all=False, HMM=True))
import numpy as np
mask=np.array(image.open(r"C:UsersljDesktop1.jpg"))
wc = WordCloud(
mask=mask,
font_path="./SimHei.ttf",
max_words=100,
width=2000,
height=1200,
)
print(cut_text)
wordcloud = wc.generate(cut_text)
# 写词云图片
wordcloud.to_file("wordcloud.jpg")
# 显示词云文件
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# 得到指定歌手页面 热门前50的歌曲ID,歌曲名
def get_songs(artist_id):
page_url = 'https://music.163.com/artist?id=' + artist_id
# 获取网页HTML
res = requests.request('GET', page_url, headers=headers)
# 用XPath解析 前50首热门歌曲
html = etree.HTML(res.text)
href_xpath = "//*[@id='hotsong-list']//a/@href"
name_xpath = "//*[@id='hotsong-list']//a/text()"#获取
hrefs = html.xpath(href_xpath)
names = html.xpath(name_xpath)
# 设置热门歌曲的ID,歌曲名称
song_ids = []
song_names = []
for href, name in zip(hrefs, names):
song_ids.append(href[9:])
song_names.append(name)
print(href, ' ', name)
return song_ids, song_names
# 设置歌手ID,赵雷为6731
artist_id = '6731'
[song_ids, song_names] = get_songs(artist_id)
# 所有歌词
all_word = ''
# 获取每首歌歌词
for (song_id, song_name) in zip(song_ids, song_names):
# 歌词API URL
lyric_url = 'http://music.163.com/api/song/lyric?os=pc&id=' + song_id + '&lv=-1&kv=-1&tv=-1'
lyric = get_song_lyric(headers, lyric_url)
all_word = all_word + ' ' + lyric
print(song_name)
#根据词频 生成词云
if __name__ == '__main__':
create_word_cloud(all_word)
结果

4 总结
今天总结下整体的内容。其中涉及到的知识点有可视化,词云图制作以及中文的jieba库。
不知道你们看完有一点点收获吗?如果有收获希望你
- 点赞 给予我更多鼓励同时让更多人学习
- 关注我公众号[我是程序员小贱]获取更多的干货。相信我不会让你们失望!