一 、安装scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架
安装:
1、 pip3 install wheel
2、下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
3、进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl()
4、pip3 install pywin32
5、pip3 install scrapy
二、在终端使用命令创建项目
scrapy startproject 项目名称
scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model pipelines 数据持久化处理
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫解析规则
三、创建一个爬虫文件
1、cd project_name(进入项目目录)
2、scrapy genspider 应用名称 爬取网页的起始url (例如:scrapy genspider qiubai www.qiushibaike.com)
3、编写爬虫文件:在步骤2执行完毕后,会在项目的spiders中生成一个应用名的py爬虫文件
如:爬取糗事百科网站 创建的应用名称为first.py,代码如下:


1 class FirstSpider(scrapy.Spider): 2 name = 'first' 3 # allowed_domains = ['www.xxx.com'] 4 start_urls = ['https://www.qiushibaike.com/text/'] 5 6 def parse(self, response): 7 all_data = [] 8 div_list = response.xpath('//div[@id="content-left"]/div') 9 for div in div_list: 10 title = div.xpath('./div[1]/a[1]/img/@alt').extract_first() 11 print(title) 12 content = div.xpath('./a[1]/div/span/text()').extract() 13 content = ''.join(content) 14 15 dic = { 16 "author": title, 17 "content": content 18 } 19 all_data.append(dic) 20 21 return all_data
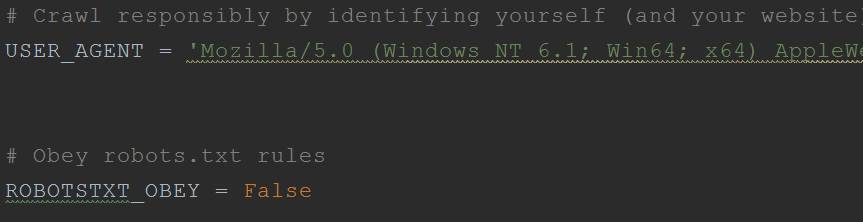
在settings的文件里更改配置 :
在终端里进入项目后执行命令:
执行爬虫:scrapy crawl first
在执行爬虫程序的时候:
scrapy crawl 爬虫名称 :该种执行形式会显示执行的日志信息
scrapy crawl 爬虫名称 --nolog:该种执行形式不会显示执行的日志信息