2020快乐!新年开始要有新气象。
上学期已经对于分布式大数据计算有些许了解以及操作过hadoop系的很多工具了,而现在的是时候进一步深入了。
对于Hadoop系的工具,包括HDFS文件系统和MapReduce分布式计算,这些都是过去用来解决分布计算的基本工具,但实际用起来可以说不算方便。HDFS不是标准的文件操作系统,尽管有分布式的强大优点,但实际上操作起来并不方便,而且使用效率较低;MapReduce的两步计算方式实现了分布式的数据处理,但处理起来过于复杂、结构却因为有些简单而没法实现很多算法,所以Hadoop系的工具可以说强大但不好用,只能用来处理历史数据和静态数据。
于是算是这一系列工具的二代Spark来了。
Spark可以说是后起之秀,在支持很多现代化的算法和工具的同时保证了运行的可靠性和高效性,所以今天准备列一张Spark名词的清单。
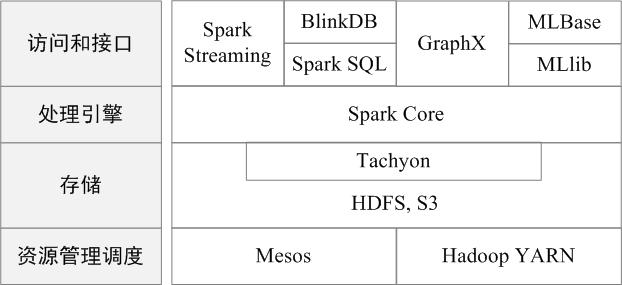
(Spark套件)
Spark Core:Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache Spark,就是指Spark Core;
Spark SQL:Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
Spark Streaming:Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等;
MLlib(机器学习):MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作;
GraphX(图计算):GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
(Spark组件)
RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系;
Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据;
应用:用户编写的Spark应用程序;
任务:运行在Executor上的工作单元;
作业:一个作业包含多个RDD及作用于相应RDD上的各种操作;
阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”。