1、什么是分词
把文本转换为一个个的单词,分词称之为analysis. ES默认只对英文语句做分词,中文不支持,每个中文汉字都会被拆分
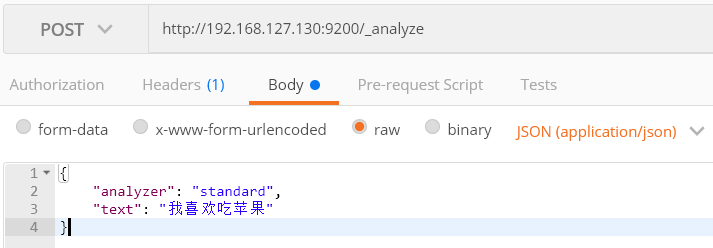
2、获得分词
http://192.168.127.130:9200/_analyze
ES内置分词器: analyzer
standard: 默认标准分词器,大写会转换为小写
simple: 非字母会被过滤的分词器。大写会转换为小写
whitespace: 根据空格进行拆分。 忽略大小写
stop : a an is the等无意义的单词会被过滤
keyword: 不进行分词拆分,把整段文本看做一个独立的关键字。
返回如下:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "喜",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "欢",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "吃",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "苹",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "果",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
}
]
}
可以看到,默认情况下,中文分词效果是有问题的,把每个汉字都拆分了。
3、对某个文档的某个字段进行分词分析
对my_doc 文档的desc字段进行分析
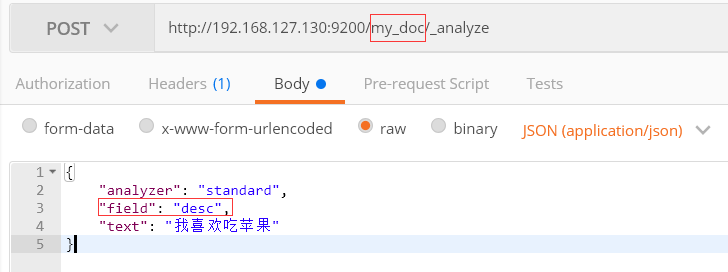
分析结构同上面是一致的。