1.选一个自己感兴趣的主题。
我选取的是猫途鹰旅游景点
from bs4 import BeautifulSoup import requests url = 'https://www.tripadvisor.cn/' wb_data = requests.get(url) soup = BeautifulSoup(wb_data.text,'lxml') for i in soup.select('li'): if len(i.select('.ranking'))>0: sort=i.select('.ranking')[0].text #排名 country=i.select('.countryName')[0].text #国家 city=i.select('.cityName')[0].text #城市 hotel=i.select('.hotelsCount')[0].text #酒店数 toury=i.select('.attractionCount')[0].text #景点数 eat=i.select('.eateryCount')[0].text #餐厅数 review=i.select('.reviewTitle')[0].text #印象 print(sort,country,city,review,hotel,toury,eat)




2.写一篇完整的博客,附上源代码、数据爬取及分析结果,形成一个可展示的成果。
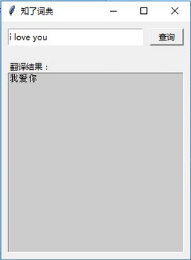
做了一个知了词典的软件
代码如下
import urllib.request import urllib.parse import time import random import hashlib import json from window import Application from tkinter import * from tkinter import Tk,Button,Entry,Label,Text,END class YouDaoHelper(object): def __init__(self): pass def crawl(self,content): timestamp = int(time.time() * 1000) + random.randint(0, 10) u = "fanyideskweb" d = content f = str(timestamp) c = "rY0D^0'nM0}g5Mm1z%1G4" salt = hashlib.md5((u + d + f + c).encode('utf-8')).hexdigest() data = { 'i': content, 'from': 'AUTO', 'to': 'AUTO', 'smartresul': 'dict', 'client': 'fanyideskweb', 'salt': timestamp, 'sign': salt, 'doctypen': 'json', 'version': '2.1', 'keyfrom': 'fanyi.web', 'action': 'FY_BY_CLICKBUTTION', 'typoResult': 'true' } data = urllib.parse.urlencode(data).encode('utf-8') request = urllib.request.Request(url='http://fanyi.youdao.com/translate_o?' 'smartresult=dict&smartresult=rule&sessionFrom=', method='POST', data=data) response = urllib.request.urlopen(request) result_str = response.read().decode('utf-8') result_dict = json.loads(result_str) result = result_dict['translateResult'][0][0]['tgt'] return result class Application(object): def __init__(self): self.helper = YouDaoHelper() self.window = Tk() self.window.title(u'知了词典') # 创建标题 self.window.geometry('280x350+600+300') self.entry = Entry(self.window) # 创建输入框 self.entry.place(x=10, y=10, width=200, height=25) # 放置在哪个地方 self.submit_btu = Button(self.window, text=u'查询', command=self.submit) # 创建按钮 self.submit_btu.place(x=220, y=10, width=50, height=25) # 翻译结果标题 self.title_label = Label(self.window, text=u'翻译结果:') self.title_label.place(x=10, y=55) # 翻译结果 self.result_text = Text(self.window, background='#ccc') self.result_text.place(x=10, y=75, width=260, height=265) def submit(self): # 1.从输入框中获取用户输入的值 content = self.entry.get() #get的方法返回当前输入框的内容 # 2.把这个值发送给有道的服务器,进行翻译 result = self.helper.crawl(content) #3.把结果放置底部的Text控件中 self.result_text.delete(1.0,END)#把第一个的印记删除 self.result_text.insert(END,result)#将要输入的内容输入到翻译结果中 def run(self): self.window.mainloop() if __name__=='__main__': app = Application() app.run()
结果如下: