关于gan的流程的理解
最近再看cyclegan所以慢慢来看,最后了解了原理来跑代码就好
-----------------------------------------------------
关于gan学习的三个重要的点:1 生成器(generator) 2 分辨器(discriminator) 3 训练手段(training strategy)
生成器的作用就是生成假的图片
分辨器的作用就是在给一个正确的图片和一个生成的假的图片之后,他可以把正确的找出来
训练手段,这个最为重要,因为很多博文没有给出来,所以大家读的也是云里雾里
------------------------------------------------------
由此,其实我这里提出好多问题:
1 如何生成假的图片:反卷积
2 如何判断,好像是一个二分类,两个图片都给过去,<0.5就是假的,>0.5就是真的,当然这个0.x就是sigmoid(wx+b)(也就是距离的sigmoid值,)可是还是有问题,同时给两个图片吗?应该是给一个图片,然后算距离?不是,给两个图片,都算标定值的距离,两个物体只能二分类?
3 如何梯度下降?
4 训练手段
带着这几个问题去读源码
面对第一个问题:如何生成图片,源码给出的解决方案是反卷积,
那么如何反卷积呢?
就是这样:
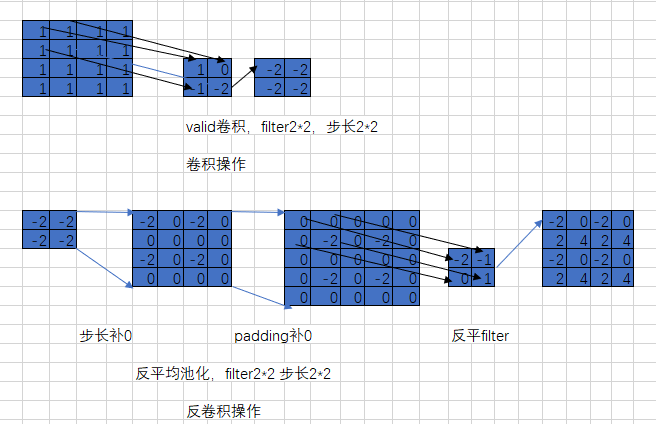
首先的操作是:
1 进行卷积上图第一行 feature:4*4 filter: 2*2 stride: 2 得到结果:2*2
2 进行反卷积:首先第一步:
1 插值补0:让卷积后的结果,每一个元素后面都补(stride-1)个0 成为了 下左2
2 padding补0:对整体再补0,这个整体补0的个数是取决于补0之后,把卷积核完全颠倒过来,按照stride=1进行卷积,卷积之后要得到原始大小(上左一)的结果
具体函数就一个:nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2),
kernel_size=3, stride=2,
padding=1, output_padding=1,
bias=use_bias),
这个函数是pytorch的函数,那么具体怎么用呢?
第一个参数:int_channels
第二个参数:out_channels
第三个参数:卷积核大小
第四个参数:步长
第五个参数:输入每一条边补充padding
第六个参数:输出每一条边补充padding
具体步骤:
>>> input = autograd.Variable(torch.randn(1, 16, 12, 12))
>>> downsample = nn.Conv2d(16, 16, 3, stride=2, padding=1)
>>> upsample = nn.ConvTranspose2d(16, 16, 3, stride=2, padding=1)
>>> h = downsample(input)
>>> h.size()
torch.Size([1, 16, 6, 6])
>>> output = upsample(h, output_size=input.size())
>>> output.size()
torch.Size([1, 16, 12, 12])
对于downsample,那么是正常的卷积,nn.conv2d
而对于upsample,那么是反卷积,nn.ConvTranspose2d
具体的问题就是如何把6*6的变成12*12的
思路:按照上面的思路来
1 补0:6*6补0,补的0是stride-1的个数,此时也就是(2-1)个0,也就是每一个元素后面补1个0,变成12*12
2 补0:首先stride此时固定为1,然后:(12-k+2*p)/1 +1 =(12-3+2*1)/1 +1 =12
3 此时的结果变为1*16*12*12
为证明此理解正确性:
>>> input = autograd.Variable(torch.randn(1, 16, 12, 12))
>>> downsample = nn.Conv2d(16, 16, 3, stride=2, padding=1)
>>> upsample = nn.ConvTranspose2d(16, 16, 2, stride=3, padding=1)
>>> h = downsample(input)
>>> h.size()
torch.Size([1, 16, 6, 6])
>>> output = upsample(h, output_size=input.size())
>>> output.size()
结果应该是
1 内部补0:变为18*18
2 padding补0:(18-2+2*1)/1 +1 =19
结果应该为1*16*19*19
然而结果错了
-----------------------------------下划线-------------------------------------
以上都是错误的,那么正确的应该是什么样
1 补0:每个元素之间补0
比如:6*6 补stride-1个0 如果stride=2, 6+(stride-1)*(6-1)=11 s=3 6+(s-1)*(5)=16 也就是补产生边框,只产生间隔的元素
2 反卷积:利用卷积的逆,x=(m-k+2*p)/1 +1
x为补0的结果,求m
这个部分为正解
---------------------------分析----------------------------------------------------
经试验证明是对的,但是分析一下上面的模型错在哪里?
其实没错,是我的理解有问题
因为步骤就是两步,
1 补0 (补充stride-1个0,且补充元素之间的,不是每个元素之后的)
2 根据我想要变成的样子进行反卷积,也就是1的结果是我想要模型进行卷积之后的结果
一句话总结,
反卷积就是先进行0的插值,因为在卷积的计算公式里面,stride动不动就除以2,除以3,所以,补充stride的这个插值可以先放大到差不多想要的结果,然后再进行反卷
--------------------------------------------------------以上为反卷积的部分----------------------------------------------------------------------
接下来是
2 个loss
也就是生成器的loss和分辨器的loss
首先来说分辨器的loss,这个loss的主要作用是,把generator输入的图片判别为0(也就是假的),把真实输入来的图片判别为1(也就是真的)
所以,答案很明显,这里就是一个二分类bceloss,当输入为真实图片,label=1,当输入为gennerator图片时,为0
注:这里看到有些代码是把这里变为两个Loss,这个具体还要再看
接下来就是这个generator的loss
---------------------------------------------------------以下为discriminator部分-----------------------------------------
这里没有什么特别多说的,主要就是一个正常的卷积,没有很特殊的,但是具体结构可以研究下
-------------------------------------传统Gan训练策略---------------------------
训练策略
1 首先,初始化generator and discriminator
2 从generator得到一些fake图片,
3 训练discriminator,并且把generator参数固定住
4 训练discriminator,把fake图片和real图片都放到discriminator,用bceloss来让分类器清晰的分辨出real和fake
5 此时discriminator已经可以把real和fake分清,固定discriminator参数,训练generator,这里再次让生成的fake图片
进入刚刚的bceloss,并且图片是fake图片,但是给他打上标签为1的label,目的是让generator生成的图片尽量为真实的
(注:这里之所以能让generator生成更真实的fake图片是因为discriminator已经能很好的认知什么是真,什么是假,
由于此时fake的图片已经给了label为1,那么generator的图片也能训练更加逼真的fake图片)
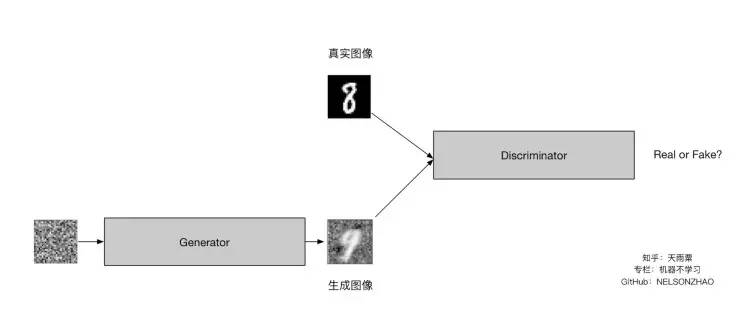
--------------------------------------------------传统gan的原理------------------------------------------------------------
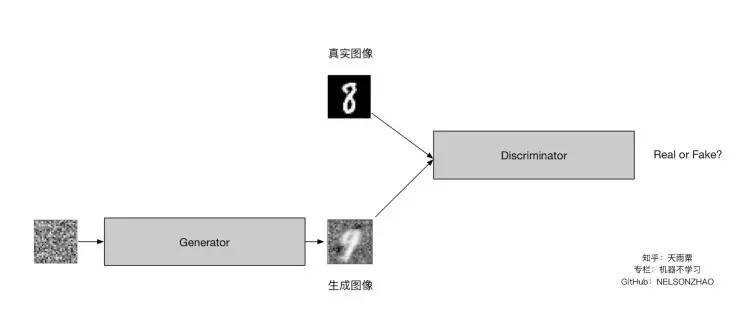
这个图解释了最基本的gan的样子
最基本的gan的样子是:
1 一堆噪点去生成一个图片,当然这个图片是假的图片(generator)
2 这个假的图片与真的图片放入discriminator ,从而训练分类器,
3 策略是上面讲的
4 注意loss是两个bceloss,一个是discriminator的,另一个是generator的,
最后的结果是得到这个假的生成图片,,,这个生成图片的特点是与真实图片比较相似
------------------------------------------------------------------------------------
gan生成图像主要就是两种方式:
pair unpair
这里的pair指的是pixle 2 pixle 级别的gan
而cycle gan在这里进行了改进,使得不需要pixle级别对应的(unpair),也可以进行风格迁移
----------------------------------------------------------------------------------
--------------------------------pixle 2 pixle--------------------------------------------------
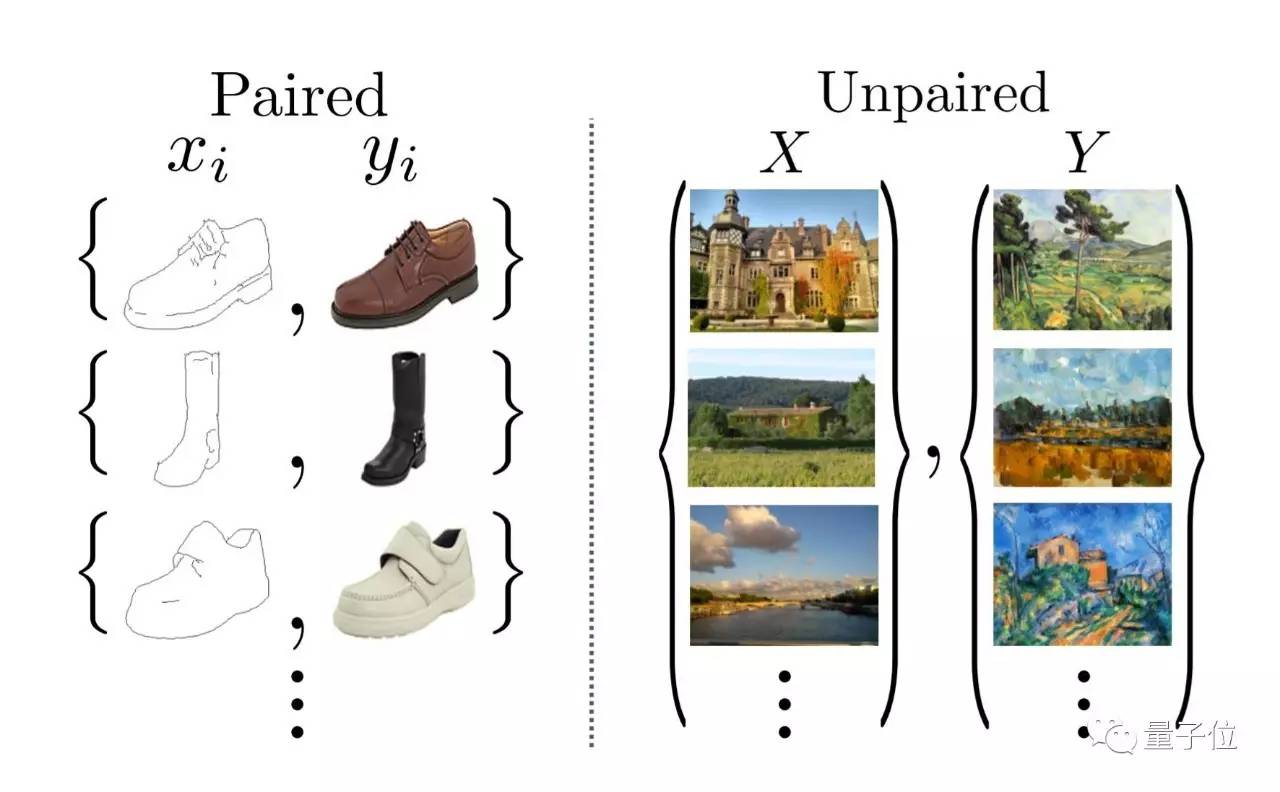
对于pixle2pixle gan,必须使用左面的pair图片,从而进行风格迁移
对于cycle gan,使用右边的unpair就可以进行风格的迁移,这个大大减少了工作量
下面简单说一下这个pixle 2 pixle 的,
这个图是我截取cycle gan的,因为没有找到pixle gan的图片(急于码字,所以没时间找图了,很是抱歉),
在这里,pixle gan的左上角和右下角的应该是一个pair,也就是再往上图片的(铅笔画的鞋,实物拍的鞋),
流程就是素描鞋generator出一个yhat,这个yhat应该是风格和实物拍的鞋是一样的,这个是pixle级别的学习
loss既有l2(像素级别对应),又有bce的(做)
所以,所谓的pair就是如果你想把一个简单的向日葵变成梵高的向日葵,那么
你需要一个简单的向日葵,还有一个梵高风格的并且是与之前的pixle对应的向日葵作品
这样才能实现简单向日葵到梵高向日葵的迁移
--------------------------------------------------cycle gan 具体流程--------------------------------------------------------
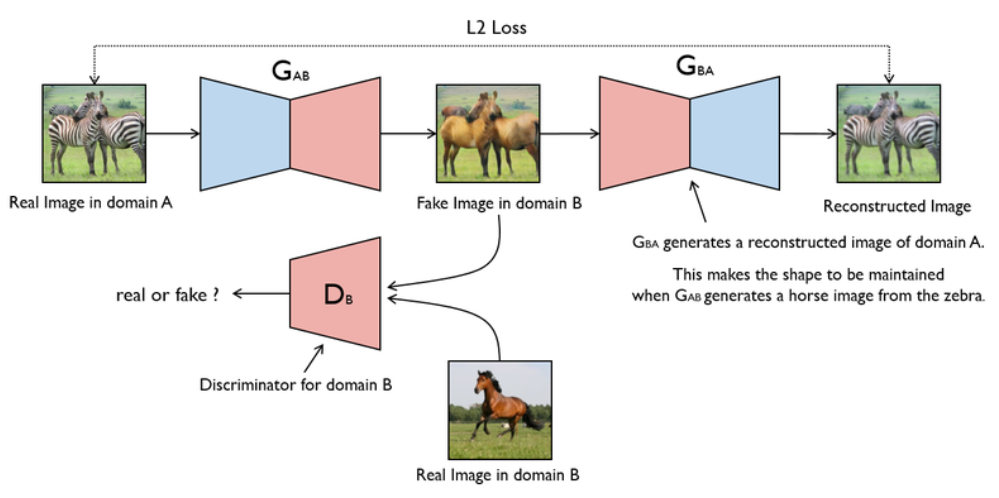
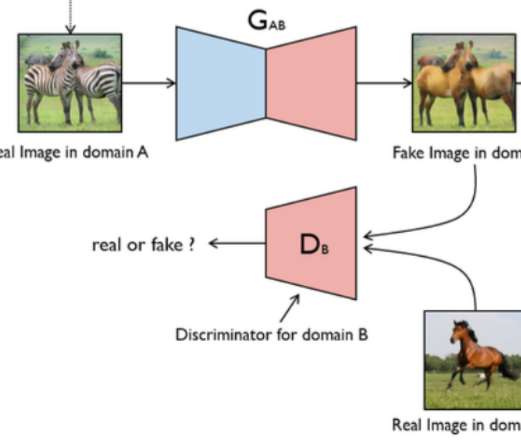
这个图片解释了cycle gan的原理
先是一个真实图片(不是噪声,这个区别于传统的gan)进入生成器,产生了一个假的图片,
这个假的图片有两个目的地:第一个是去骗鉴别器,第二个是保持自我的模样,也就是pixle级别要对称,意味着要使中间的假的图片的形状要与最左边的一样
那么
一:去骗鉴别器,就往下走,bceloss,鉴别器的目的是风格迁移,把domainb的风格迁移给生成的fake图片
二:自我进化,往右走,n1loss,要让生成器去生成pixle级别要对应的图片,也就是生成的fake图片要和最左边的图片保持像素级对应,
但是为什么会这样呢?
首先既能满足n1loss,又要满足bceloss,那么最终的结果就是二者会融合,
但是怎么样融合呢?
因为n1loss是像素级的,也就是pixle级别要相互对应,所以产生的形状是一样的,颜色都是一样的,也就是上图最左和最右的样子。
但是中间为什么不会形成real image in domain b 的样子呢?
但是这样做的目的是为什么?目的是为了生成fake image in domain b
具体的流程:
与上面的区别在于给
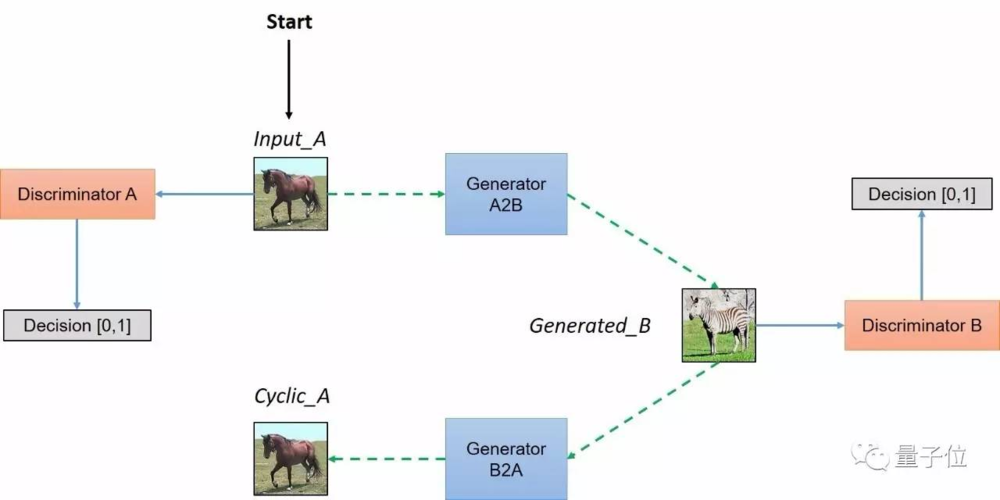
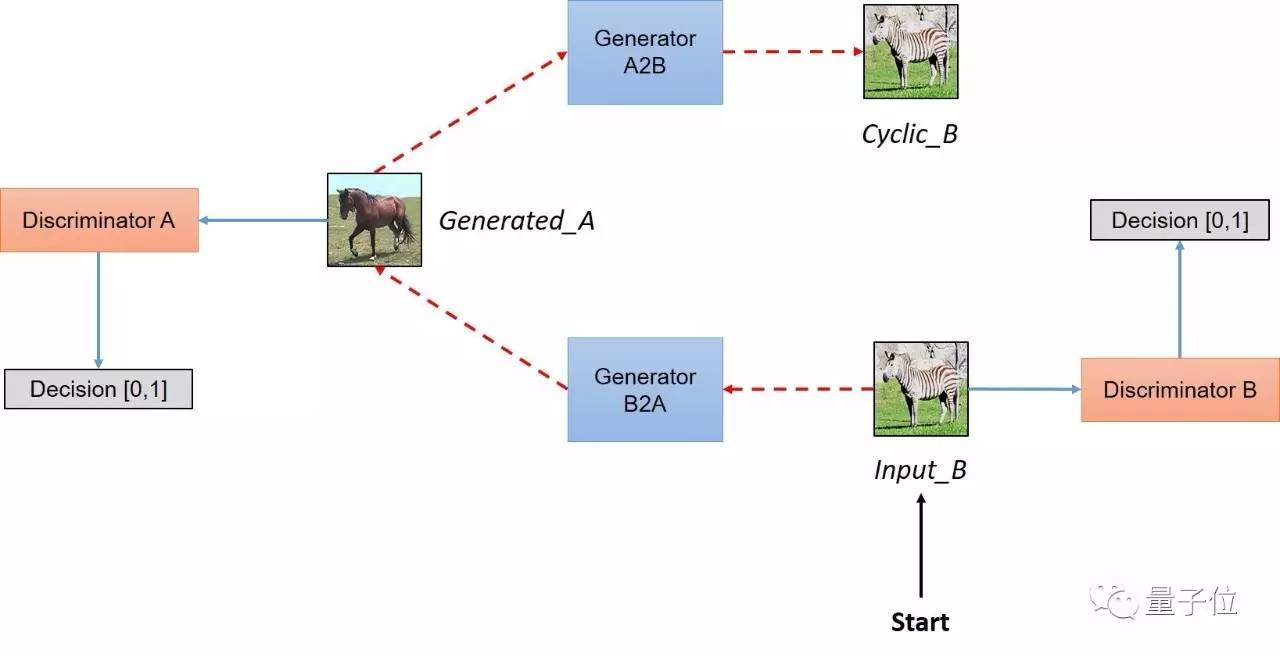
这个结构与之前的结构的区别在于,这个相当于加了约束,可以这么理解:
上一张图片中,进行bce的时候是放入真实的图片,可是这个约束不够,不足以让学习到的这个
self.netG_A = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.norm,
not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)
self.netG_B = networks.define_G(opt.output_nc, opt.input_nc, opt.ngf, opt.netG, opt.norm,
not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)
def backward_D_basic(self, netD, real, fake):
"""Calculate GAN loss for the discriminator
Parameters:
netD (network) -- the discriminator D
real (tensor array) -- real images
fake (tensor array) -- images generated by a generator
Return the discriminator loss.
We also call loss_D.backward() to calculate the gradients.
"""
# Real
pred_real = netD(real)
loss_D_real = self.criterionGAN(pred_real, True)
# Fake
pred_fake = netD(fake.detach())
loss_D_fake = self.criterionGAN(pred_fake, False)
# Combined loss and calculate gradients
loss_D = (loss_D_real + loss_D_fake) * 0.5
loss_D.backward()
return loss_D
def backward_D_A(self):
"""Calculate GAN loss for discriminator D_A"""
fake_B = self.fake_B_pool.query(self.fake_B)
self.loss_D_A = self.backward_D_basic(self.netD_A, self.real_B, fake_B)
def backward_D_B(self):
"""Calculate GAN loss for discriminator D_B"""
fake_A = self.fake_A_pool.query(self.fake_A)
self.loss_D_B = self.backward_D_basic(self.netD_B, self.real_A, fake_A)
def backward_G(self):
"""Calculate the loss for generators G_A and G_B"""
lambda_idt = self.opt.lambda_identity
lambda_A = self.opt.lambda_A
lambda_B = self.opt.lambda_B
# Identity loss
if lambda_idt > 0:
# G_A should be identity if real_B is fed: ||G_A(B) - B||
self.idt_A = self.netG_A(self.real_B)
self.loss_idt_A = self.criterionIdt(self.idt_A, self.real_B) * lambda_B * lambda_idt
# G_B should be identity if real_A is fed: ||G_B(A) - A||
self.idt_B = self.netG_B(self.real_A)
self.loss_idt_B = self.criterionIdt(self.idt_B, self.real_A) * lambda_A * lambda_idt
else:
self.loss_idt_A = 0
self.loss_idt_B = 0
# GAN loss D_A(G_A(A))
self.loss_G_A = self.criterionGAN(self.netD_A(self.fake_B), True)
# GAN loss D_B(G_B(B))
self.loss_G_B = self.criterionGAN(self.netD_B(self.fake_A), True)
# Forward cycle loss || G_B(G_A(A)) - A||
self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * lambda_A
# Backward cycle loss || G_A(G_B(B)) - B||
self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * lambda_B
# combined loss and calculate gradients
self.loss_G = self.loss_G_A + self.loss_G_B + self.loss_cycle_A + self.loss_cycle_B + self.loss_idt_A + self.loss_idt_B
self.loss_G.backward()
--------------------------------------分拆理解------------------------------------------------------
cyclegan 里面loss很多,搞懂他的loss,就能理解了
1 discriminator loss:
分清真的图,假的图
两个discriminator的图
self.loss_D_A = self.backward_D_basic(self.netD_A, self.real_B, fake_B)
self.loss_D_B = self.backward_D_basic(self.netD_B, self.real_A, fake_A)
2 generator loss:
self.criterionIdt
self.criterionGAN
self.criterionCycle = torch.nn.L1Loss()
self.idt_A = self.netG_A(self.real_B)
self.loss_idt_A = self.criterionIdt(self.idt_A, self.real_B) * lambda_B * lambda_idt
self.idt_B = self.netG_B(self.real_A)
self.loss_idt_B = self.criterionIdt(self.idt_B, self.real_A) * lambda_A * lambda_idt
loss_idt代表什么?
这里也是约束,是让fakeimage和之前的image,做mseloss,以保证pixle级别的对应
self.loss_G_A = self.criterionGAN(self.netD_A(self.fake_B), True)
# GAN loss D_B(G_B(B))
self.loss_G_B = self.criterionGAN(self.netD_B(self.fake_A), True)
# Forward cycle loss || G_B(G_A(A)) - A||
loss_G_A(B)这里的工作是属于第二次训generator:即让产生的generator生成更逼真的图片
self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * lambda_A
# Backward cycle loss || G_A(G_B(B)) - B||
self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * lambda_B
# combined loss and calculate gradients
loss_cycle_A(B)这里的工作是什么意思?
这里是让生成的图片和之前的保持一样
self.loss_G = self.loss_G_A + self.loss_G_B + self.loss_cycle_A + self.loss_cycle_B + self.loss_idt_A + self.loss_idt_B
-----------------总结一下cyclegan-------------------------
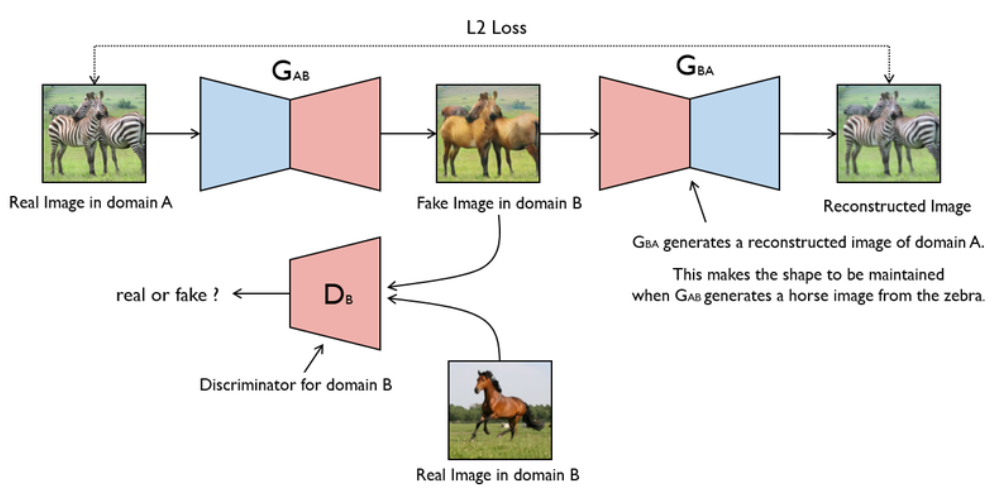
1 generator
这里可以看cycle gan里面的第一张图片就好,因为第二张图片和第一张原理一样,只是多了些约束
a 得到real image in domain a
b 如图,生成fake图片,
c fake图片重建(reconstructed image)
2 discriminator
d 如图,生成的fake image和real image in domain b 放入鉴别器,以得到一个很好的鉴别器(知道什么是真,什么是假),
3 训练流程(loss)
1首先生成fake图片(b过程)
2把fake图片和真实图片放在一起训练分类器(d过程) bceloss1 目的是能够清晰地分辨真实图片和假图片
3固定分类器,把generator生成的图片打上label=1,进入鉴别器训练 bceloss1 ,以求得到更好的类似于domianb的图片
4 restructure 与image in domain a进行 mseloss 保证pixle级别对应,也就是保证风格迁移而内容不变
5 fake in domian a 和 real image in domain a 进行 mseloss 保证pixle级别对应,也就是保证风格迁移而内容不变
--------广义理解----------------------------------------
最重要的是想起generator discriminator的精髓,也就是训练方式,即互相驳的训练方式
面对传统gan:
面对风格迁移gan:
任何只要有两个类别,都可以变成gan
比如有一个类是橘猫,有一个类是土狗,那么想要生成一个土狗样子,但是皮肤是橘猫的新物种,橘猫这边bce 土狗那边l2/l1
所以可以理解为任何unpair的数据都可以用作gan,只要他们是两个类,那么这两个类就可以类比,
精髓:
1首先要有一个三角形(三个顶点(1 real image in domain a 2 fake image 3 real image in domain b)
虽然是一个三角形,但是归根结底是两个类
其次就要在这三个做相似,loss可以选为l1/l2/bce
1可以像猫,也可以像狗
2可以像猫,并且远离狗
3可以像狗,并且远离猫
----------结尾附送李宏毅老师的例子---------------------------------
最近写paper,这个后期补
----------接下来是dcgan的原理,这个很有用-----------------------------------
dcgan是什么,首先他遵从传统gan的模型
即
1即噪声生成,产生一个fake图片,
2fake :0与 real :1图片组合生成一个discriminator
3fake :1来训练generator
这是传统的原理
dcgan通过一些调试,使得最后真的可以生成一张图片,
dcgan之前只是一种思想,并不是真的能够生成一张栩栩如生的图片,但是dcgan可以了,
这个paper偏工程,主要还是一些调参的trick
-----------------------------------------------------------------------------------------------------
半监督:semi-supervised
无监督:unsupervisied
接下来考虑这两个点
其实这两个做分类的关键(用gan的方法)都是在于生成很多带有标签的图片
只不过半监督可以生成更加多样的图片
--------------------------无监督---------------------------------
首选gan本来就是一个无监督的网络
gan的generator生成图片,主要是依靠两个点,
1 一些随机噪声
2 一些real image
所以,他实际上就算是无监督的,因为没有图片和与之对应的标签
所以,最后生成的可能是一坨
但是dcgan生成了有模有样的图片,也就是无监督的东西生成了一堆带有label的图片
-----------这里没有解释充分----------------
------------------------------------------------------------------------------------------------------
接下来所谓的半监督,我们可以看到