网上搜索出jmeter压测结果解析成html文件的博客分享很多,但是并不能达到我自己的测试预期,因此采用Python解析jtl文件,解析结果直接展示用例通过和失败的数目,以及失败的用例标题,如下图所示:

搭建步骤:
1. 安装tomcat
2. 安装jenkinsb并进行配置
其他:使用Python解析jtl文件
一、 安装tomcat
1.1 下载tomcat安装包
1.2 拷贝文件到Library目录下并解压,解压命令:tar -xzvf xxxxxxxx.tar.gz
1.3 进入解压后的目录/bin
1.4 启动服务,启动命令:star.sh
1.5 使用浏览器输入localhost+端口号,检查是否启动成功,启动成功如下图
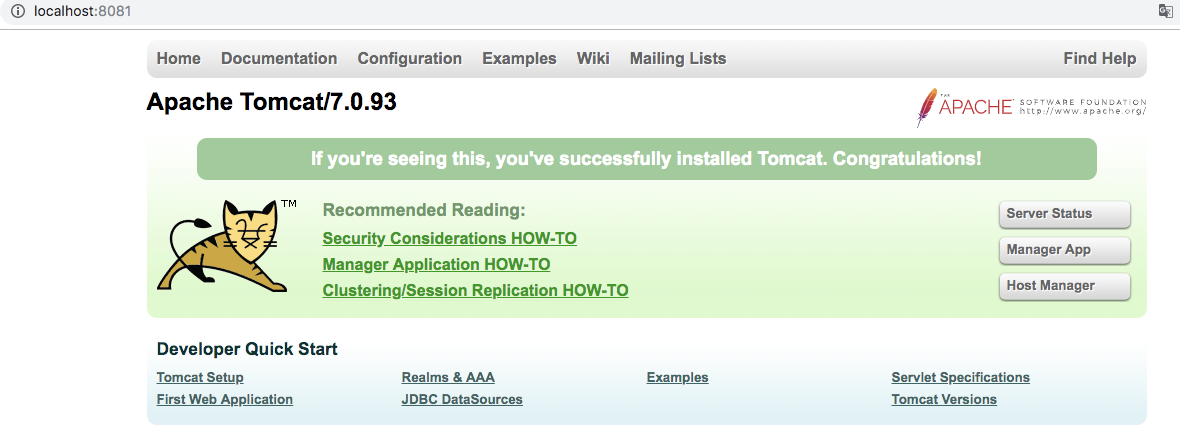
如果没有启动成功,可以去logs下查看启动日志,查找失败原因
安装步骤粗略描述,详细步骤需要的话可以自己百度
二、安装jenkins
2.1 进入jenkins官网下载war包
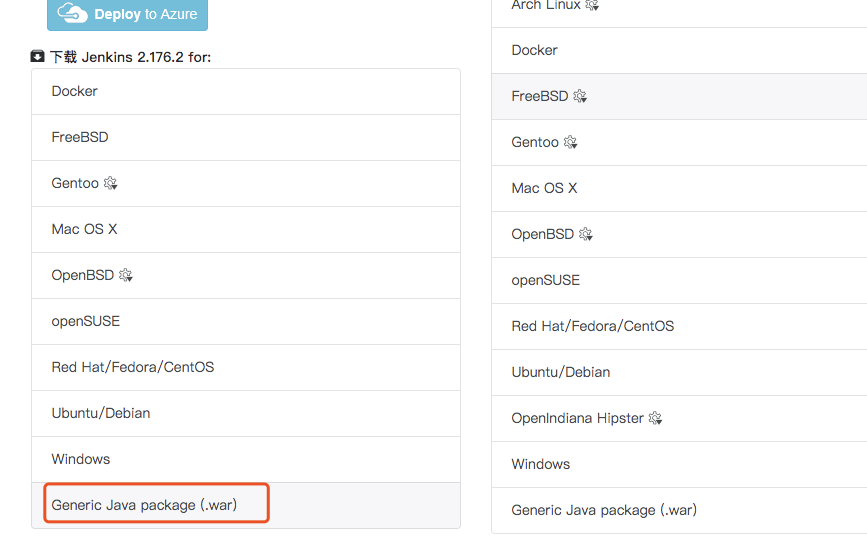
2.2 把war包放入tomcat的webapps目录下,重启tomcat
2.3 在浏览器输入localhost:8080/jenkins就可以访问jenkins了
这里粗略记录了jenkins的安装,具体怎么配置可自行百度
三、Python解析jtl文件
#把jmeter执行结果jtl文件中的所有httpSample存放到一个list中 def getAllCase(file): caselist = [] f = open(file,encoding='utf-8') for line in f.readlines(): if line.startswith('<httpSample'): line = line[12:-2] caselist.append(line) # print(caselist) return caselist #处理allcase,取出s,lb和rc作为字典存到list中 def caselDicList(caselist): casediclist = [] #每条case是一个字典,把所有case存放到list里面 # print(caselist) for case in caselist: # print(case) #一条case,包含sample中的所有 casedic={} case_list = case.split(" ") for i in case_list: if i.__contains__("="): key = i.split("=")[0] casedic[key] = i.split("=")[1] casediclist.append(endCase(casedic)) # print(casediclist) return casediclist #把casedic做处理,只保留s,lb,rc def endCase(casedic): case_pre = casedic case_aft = {} for i in case_pre: if i == "s" or i == "lb" or i == "rc": case_aft[i] = case_pre.get(i) return case_aft #分析结果 def result(casediclist): pass_nums = 0 fail_nums = 0 fail_casediclist = [] for casedic in casediclist: if casedic.get("s").__contains__('true'): pass_nums = pass_nums+1 else: fail_nums = fail_nums+1 print("失败的用例标题为:"+casedic.get("lb")) fail_casediclist.append(casedic) print("通过的用例数为:"+str(pass_nums)) print("失败的用例数为:"+str(fail_nums)) caselist = getAllCase('mpp.jtl') #这里传入的是jtl的绝对路径 casediclist = caselDicList(caselist) result(casediclist)
四、配置jenkins
4.1 新建一个自有项目的job
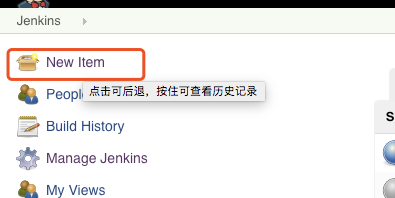
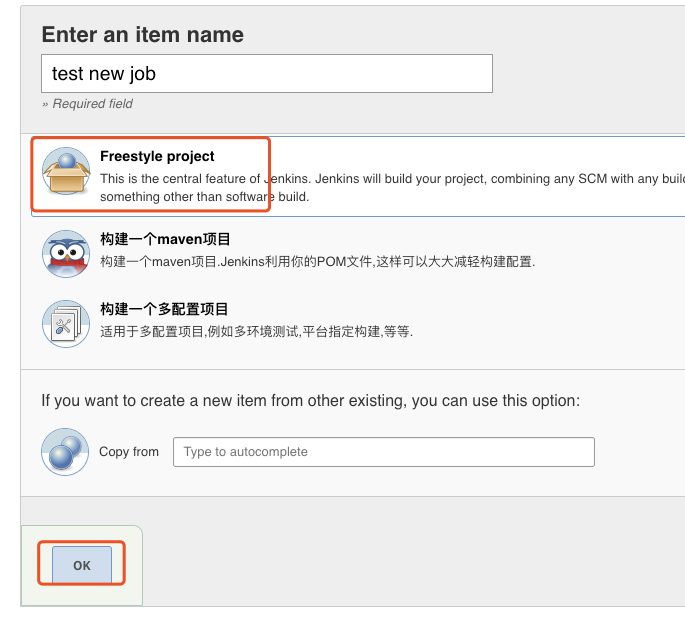
4.2 设置定定时运行,参考定时构建语法
定时器构建语法
* * * * *
星号中间用空格隔开
- 第一个*表示分钟,取值0~59
- 第二个*表示小时,取值0~23
- 第三个*表示一个月的第几天,取值1~31
- 第四个*表示第几月,取值1~12
- 第五个*表示一周中的第几天,取值0~7,其中0和7代表的都是周日
用法举例:
- 每30分钟构建一次:
H代表形参
H/30 * * * * - 每2个小时构建一次:
H H/2 * * * - 每天的8点,12点,22点,一天构建3次: (多个时间点中间用逗号隔开)
0 8,12,22 * * * - 每天早上8点到晚上6点每三小时检查一次
H 8-18/3 * * *
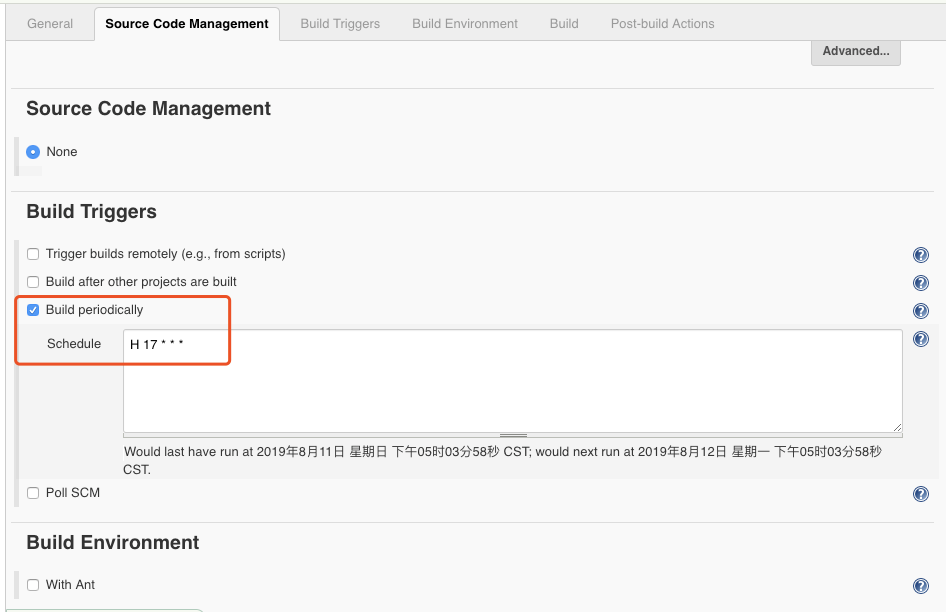
4.3 执行shell脚本
分两步执行
第一步执行jmeter: jmeter -n -t xxxxx.jmx -l xxxxxxx.jtl
第二步执行Python解析jtl:python xxxx.py
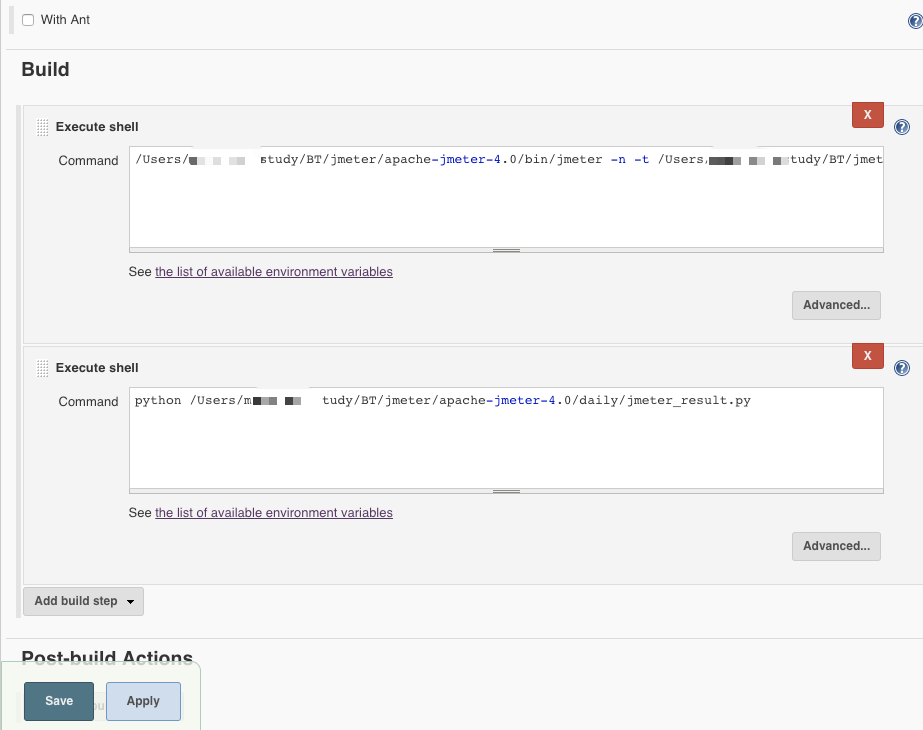
保存后,手动触发构建出现第一张图片的结果
其中py文件就是步骤三种的代码,解析jtl文件使用
!!!!补充!!!!
jmeter解压后默认运行的不是xml格式的jtl文件,所以需要修改配置,配置文件在bin目录下:jmeter.properties

这样执行后的jtl文件内容是xml格式的,自己写的py只能解析xml格式的jtl文件。