前言
基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库)、Caffe(深度学习库)、Dlib(机器学习库)、libfacedetection(人脸检测库)、cudnn(gpu加速库)。
用到了一个开源的深度学习模型:VGG model。
最终的效果是很赞的,识别一张人脸的速度是0.039秒,而且最重要的是:精度高啊!!!
CPU:intel i5-4590
GPU:GTX 980
系统:Win 10
OpenCV版本:3.1(这个无所谓)
Caffe版本:Microsoft caffe (微软编译的Caffe,安装方便,在这里安利一波)
Dlib版本:19.0(也无所谓
CUDA版本:7.5
cudnn版本:4
libfacedetection:6月份之后的(这个有所谓,6月后出了64位版本的)
这个系列纯C++构成,有问题的各位朋同学可以直接在博客下留言,我们互相交流学习。
====================================================================
本篇是该系列的第四篇博客,介绍如何使用CUBLAS加速进行两个向量间余弦距离的计算。
思路
我们先来温习一下两个向量之间余弦距离的数学公式,大家自己可以回忆一下:
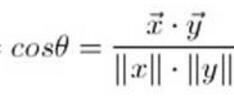
x,y均为同维度的向量,如果为6400维,那么我们可以将式子进行展开:
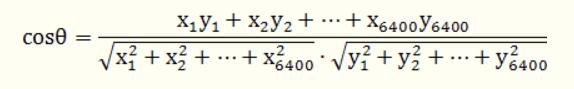
为什么这里我们要用余弦距离,而不用欧式距离?
余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。(摘自http://www.cnblogs.com/chaosimple/archive/2013/06/28/3160839.html)
我们使用余弦距离能够更好的反映两个人脸向量之间的相似度。
实现
这里我们可以先实现一个,不使用CUDA加速的版本。
ComputeDistance.h:
#include <vector>
#include <assert.h>
float cosine(const vector<float>& v1, const vector<float>& v2);ComputeDistance.cpp:(提供一个总的接口)
#include <ComputeDistance.h>
using namespace std;
float dotProduct(const vector<float>& v1, const vector<float>& v2)
{
assert(v1.size() == v2.size());
float ret = 0.0;
for (vector<float>::size_type i = 0; i != v1.size(); ++i)
{
ret += v1[i] * v2[i];
}
return ret;
}
float module(const vector<float>& v)
{
float ret = 0.0;
for (vector<float>::size_type i = 0; i != v.size(); ++i)
{
ret += v[i] * v[i];
}
return sqrt(ret);
}
float cosine(const vector<float>& v1, const vector<float>& v2)
{
assert(v1.size() == v2.size());
return dotProduct(v1, v2) / (module(v1) * module(v2));
}
这里的目的是输入vector< float> x, vector< float> y 进行计算,我们使用上一篇博客中提取人脸向量的代码来进行测试,看其运行时间。
main函数:
Caffe_Predefine();
Mat lena = imread("lena.jpg");
Mat test = imread("test.jpg");
resize(lena, lena, Size(224, 224));
resize(test, test, Size(224, 224));
if (!lena.empty()&&!test.empty())
{
vector<float> lena_vector = ExtractFeature(lena);
vector<float> test_vector = ExtractFeature(test);
clock_t t1, t2;
t1 = clock();
cout << "余弦距离为:" << cosine(lena_vector, test_vector) << endl;
t2 = clock();
cout << "计算耗时" << t2 - t1 << "ms" << endl;
}
imshow("LENA", lena);
imshow("TEST", test);
waitKey(0);运行结果:
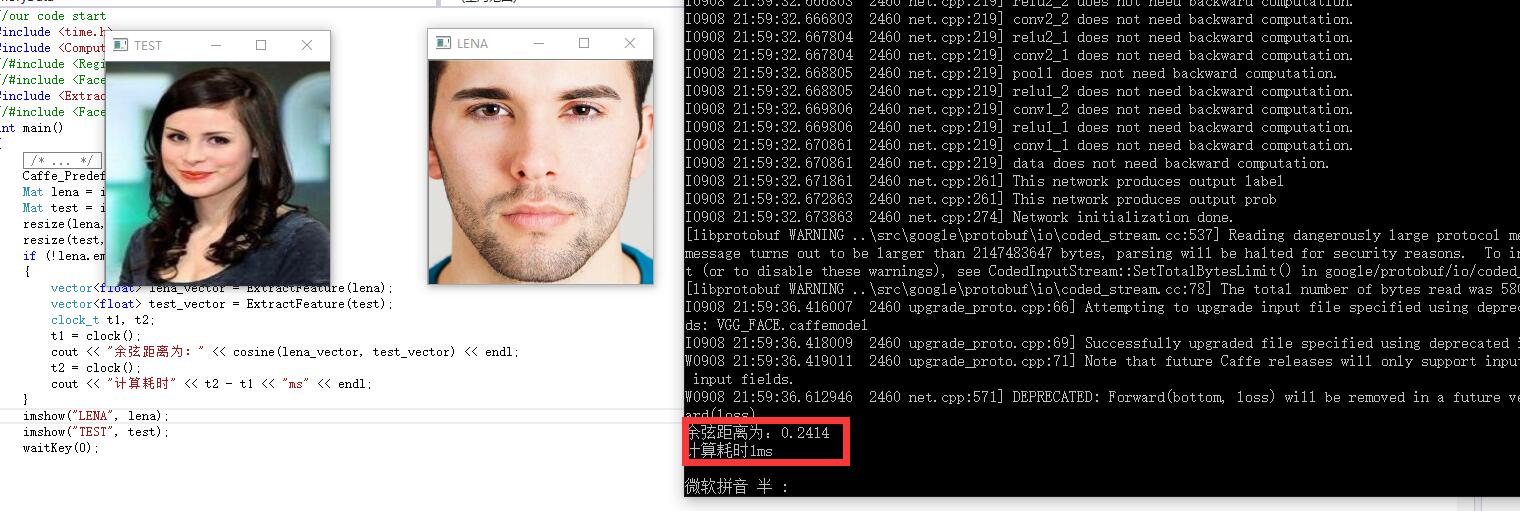
但是在真实应用中,我们必须要求计算的高速度。这里可以这样来考虑:其一是通过多线程,当有很多人需要进行匹配时,每个线程都进行与测试向量的距离计算。其二是本身人脸向量计算的时候就需要先加速,这里我们先使用CUBLAS来尝试对cosine函数进行加速。
CUBLAS
cublas是一个开源的矩阵加速运算库,它使用更为优秀的浮点运算设备GPU来对线性运算进行加速。因为余弦公式(上面有),我们需要做的核心数学公式及为向量点乘(向量的模可以看成是向量自己对自己的点乘然后再开方):
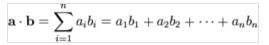
值得一提的是,CUBLAS为我们提供好了这样一个函数:cublasSdot(即为cublasSdot_v2)
cublasSdot_v2 (cublasHandle_t handle,int n,const float *x,int incx,const float *y,int incy,float *result);n代表的是输入向量的维度,x是第一个向量,y是第二个向量,incx 与incy 取1,result 是点积结果。
我们在配置Caffe的过程中,早已经把cublas的库添加了。所以我们新建一个cpp,在文件里包含
#include <stdlib.h>
#include <time.h>
#include <iostream>
#include "cuda_runtime.h"
#include "cublas_v2.h"
using namespace std;
cublasStatus_t ret;
cublasHandle_t handle_cos;即可,做一个小测试。
如何撰写这个求余弦的公式?一个直观的感受即为:
float Cosine(float* a, float* b, float *result,float *a_result,float *b_result,int channel)
{
cublasSdot(handle_cos, channel, a, 1, b, 1, result);
cublasSdot(handle_cos, channel, a, 1, a, 1, a_result);
cublasSdot(handle_cos, channel, b, 1, b, 1, b_result);
return *result/(sqrt(*b_result)*sqrt(*a_result));
}我们的主函数:
int main()
{
int arraySize = 10000;
float* a = (float*)malloc(sizeof(float) * arraySize);
float* d_a;
cudaMalloc((void**)&d_a, sizeof(float) * arraySize);
for (int i = 0; i<arraySize; i++)
a[i] = 1.0f;
cudaMemcpy(d_a, a, sizeof(float) * arraySize, cudaMemcpyHostToDevice);
float* result = (float*)malloc(sizeof(float));
float* a_result = (float*)malloc(sizeof(float));
float* b_result = (float*)malloc(sizeof(float));
ret = cublasCreate(&handle_cos);
clock_t t1, t2;
t1 = clock();
cout << Cosine(d_a, d_a, result, a_result, b_result, arraySize) << endl;
t2 = clock();
cout << t2 - t1<<"ms"<<endl;
//printf("
CUBLAS: %.3f", *cb_result);
cublasDestroy(handle_cos);
cin.get();
}这里我们算了一个10000维向量的点积(自己乘自己),计算速度为0ms(应该是可以看比毫秒精度更高的时间单位的,大家可以自己试试):
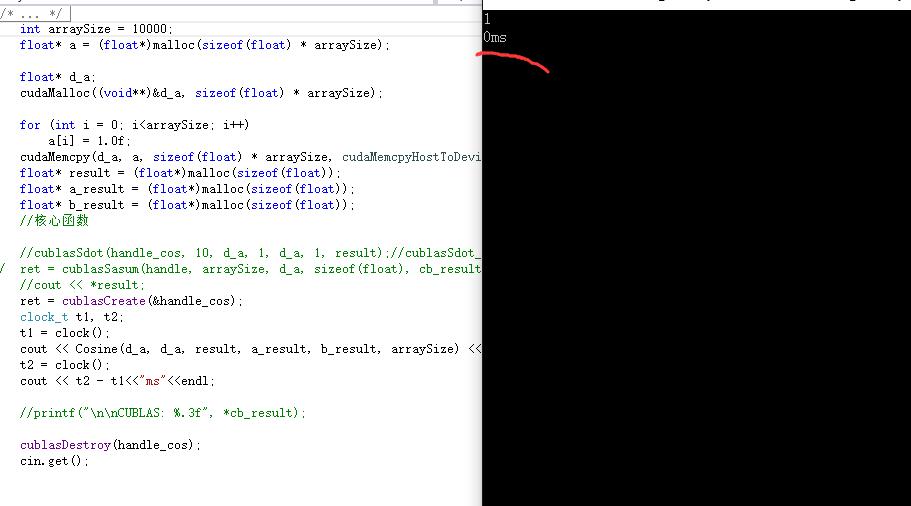
使用CUBLAS,我们可以获得很快速的两个向量之间求点积的解决方案。其实事实上,比起两个向量之间求点积的速度,我们更为重要的,是如何求解一个向量与多个向量求余弦距离的优化方法。在之后的几章会对这个问题进行讨论。
=================================================================