Introduction
(1)Motivation:
作者考虑到空间上的噪声可以通过时间信息进行弥补,其原因为:不同帧的相同区域可能是相似信息,当一帧的某个区域存在噪声或者缺失,可以用其它帧的相同区域进行弥补。
(2)Contribution:
① 不直接使用帧提取的特征信息,而是提出一个改进循环单元(refining recurrent unit,RRU),来修复缺失或噪声;
② 介绍一种时空线索集成模块(spatial-temporal clues integration module,STIM),来提取时空信息;
③ 提出多层训练目标来提高RRU和STIM的能力。
Method
(1)框架:
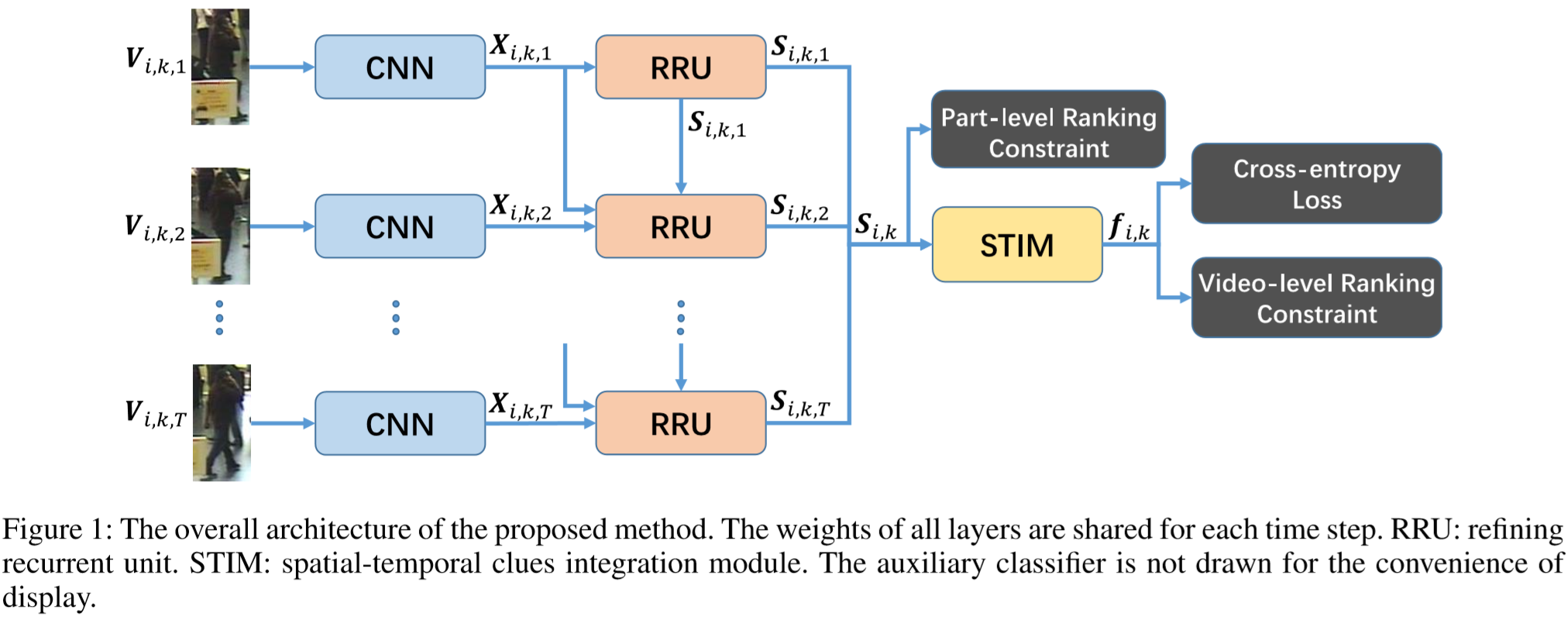
定义:![]() 表示行人 i 的 K 个视频序列,采用 Inception-v3 (2016年Szegedy提出)作为特征提取模块的主干网络,通过CNN提取出的特征为
表示行人 i 的 K 个视频序列,采用 Inception-v3 (2016年Szegedy提出)作为特征提取模块的主干网络,通过CNN提取出的特征为 ![]() ,再传入RRU模块得到改进特征 Si,k,最后传入 STIM模块僧改成最终的视频级特征表示
,再传入RRU模块得到改进特征 Si,k,最后传入 STIM模块僧改成最终的视频级特征表示 ![]() 。
。
(2)改进循环单元(RRU):
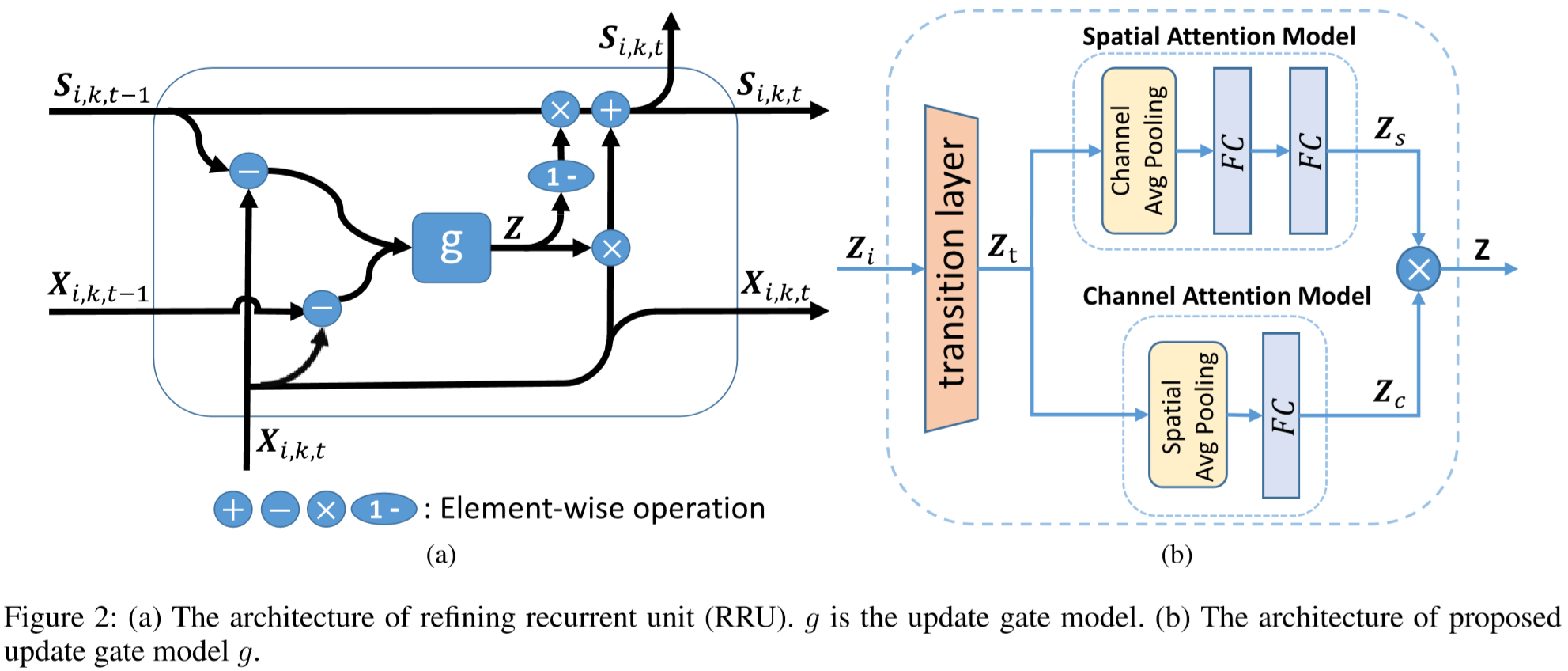
使用![]() 作为 g 模块的输入,来衡量两帧的样貌差异(我的理解:特征S相当于特征X弥补上缺失),使用
作为 g 模块的输入,来衡量两帧的样貌差异(我的理解:特征S相当于特征X弥补上缺失),使用![]() 作为 g 的另一个输入,来衡量动作捕捉。
作为 g 的另一个输入,来衡量动作捕捉。
![]() ,其中
,其中![]() 。
。
首先通过过渡层(transition layer),其包含256个filter 1*1的卷积层,得到 ![]() ;
;
上层为空间感知模块,首先使用通道交叉平均池化获得每个空间位置的全局感知,再通过两个全连接层,得到:![]() ,
,![]() ,
,![]() ;
;
下层为通道感知模块,首先使用空间平均池化来获得每个通道的全局感知,再通过一个全连接层,得到:![]() ,
,![]() ,
,![]() ;
;
将两者进行乘法操作,再用sigmoid约束至[0, 1]之间,即:![]() ,
,![]() 。
。
最终特征输出:![]() ,
,
Z 的每一个位置表示该位置特征的可信值。其值高,则表示该位置的特征有较高的质量,应当保留;其值低,则表示该位置应当被前帧特征所替补。(两帧差别小的地方直接用上一帧,差别大的地方用当前帧)
(3)时空线索集成模块(STIM):
STIM 包含了两个3D卷积模块和一个平均池化层,每个3D卷积模块包含了三个操作:3D卷积层(包含256个filter)+ 3D BN层 + ReLU层。第一个3D卷积模块的kernel size为 1*1*1,用来降低特征维度;第二个3D卷积模块的kernel size为3*3*3,用来捕捉行人的肢体移动,并输出特征:![]()
![]() 。最后通过时空平均池化,得到最终特征表述:
。最后通过时空平均池化,得到最终特征表述:![]() ,即:
,即:

(3)多层训练目标:
训练目标函数:![]()
① 第一项为两个交叉熵损失,详情参照Szegedy提出的Inception-v3模型,该模型包含identity classifier 和 auxiliary classifier 两个分类器,作者对identify classifier的全连接层进行了修改,采用了Zhong提出的classifier模块,包含了512结点的全连接层、BN、ReLU、Dropout、FC、Softmax层。
② 第二项为视频级约束,采用Hermans等人提出的batch hard三元组损失,具体为:
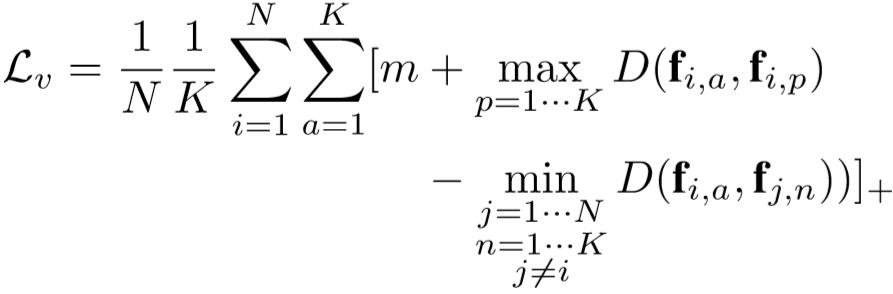
③ 第三项为区域级约束,将特征S划分成行,获得行级特征(上述特征f忽略了不同区域的空间变化 ):

其中![]() 为
为![]() 的第 r 行,得到的区域特征向量为:
的第 r 行,得到的区域特征向量为:![]() ,
,
定义如下损失函数:
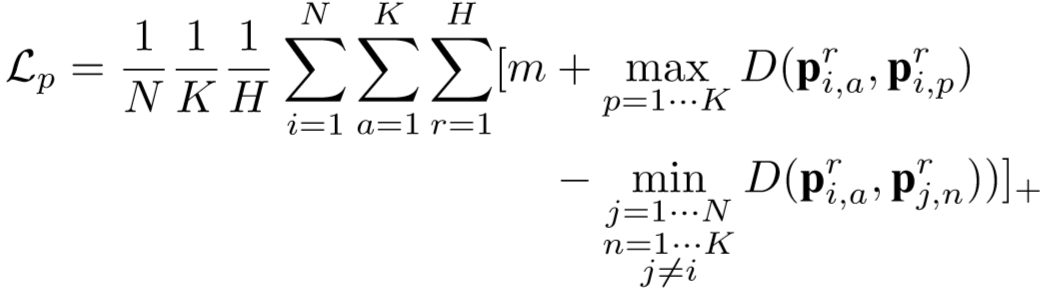
Experiments
(1)实验设置:
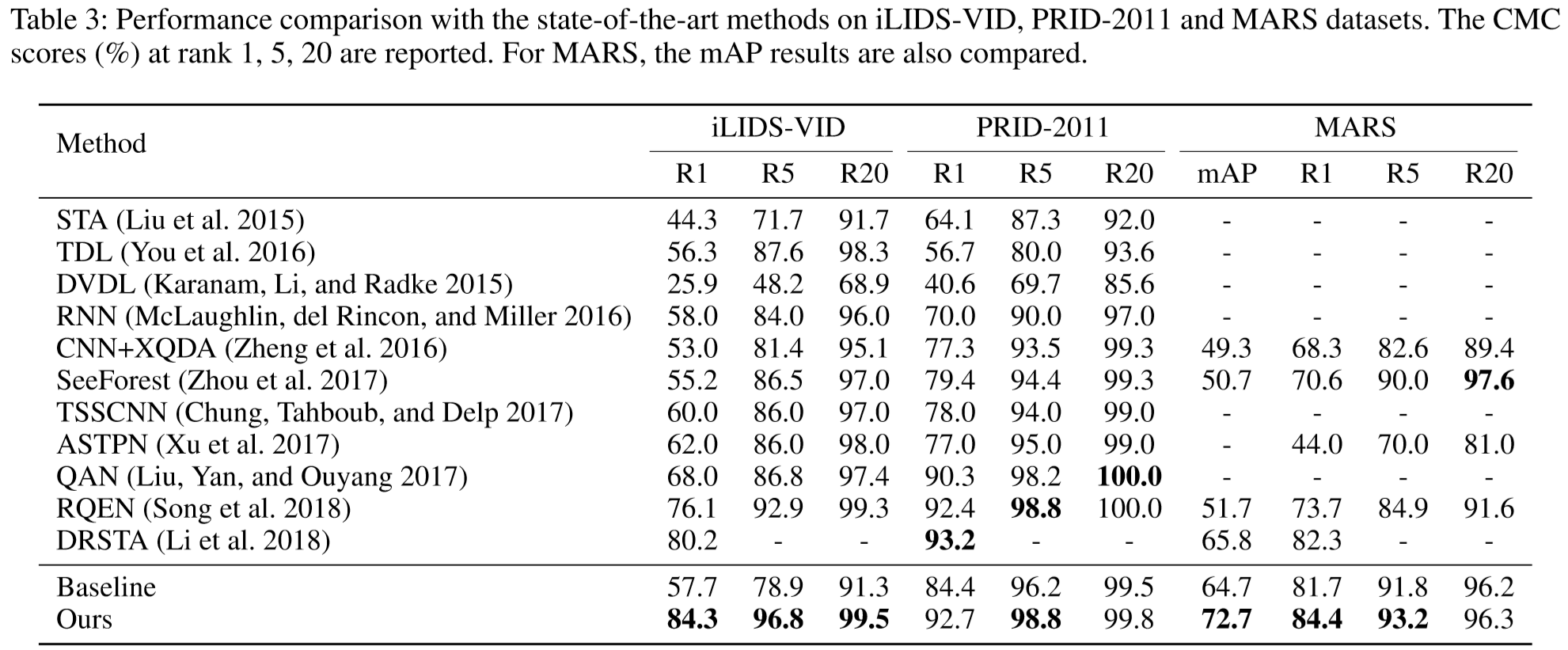
① 数据集:iLIDS-VID、PRID-2011、MARS;
② 参数设置:帧大小 299*299,N = 10,K = 2,T = 8,m = 0.4,dropout rate = 0.5,learning rate = 0.01,weight decay = 5 * 10^-4,momentum = 0.9
(2)实验结果: