一:dlib库踩的坑
Import dlib报错:

可是已经安装了dlib库:

尝试卸载在安装:
conda uninstall dlib命令失败:
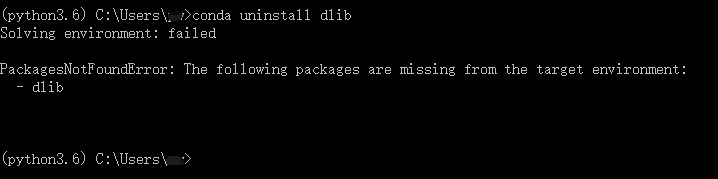
改用pip uninstall dlib命令成功卸载:


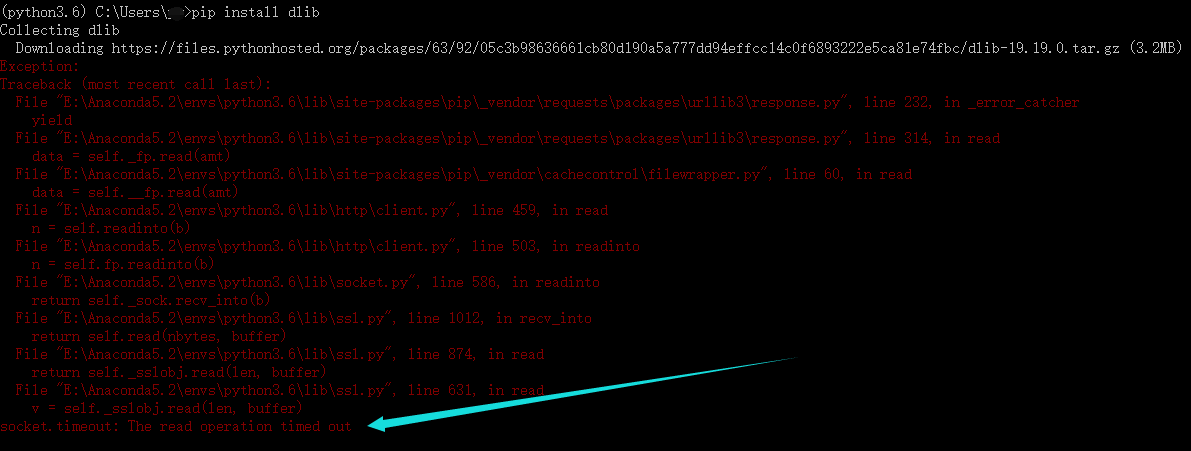
重新安装:pip install dlib失败,报错,又试了几遍还是同样的错:
后来尝试:从 https://pypi.org/ 将dlib库下载到本地安装如下图,安装成功:

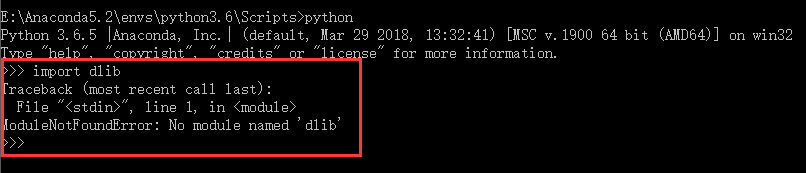
然而任然不能import:
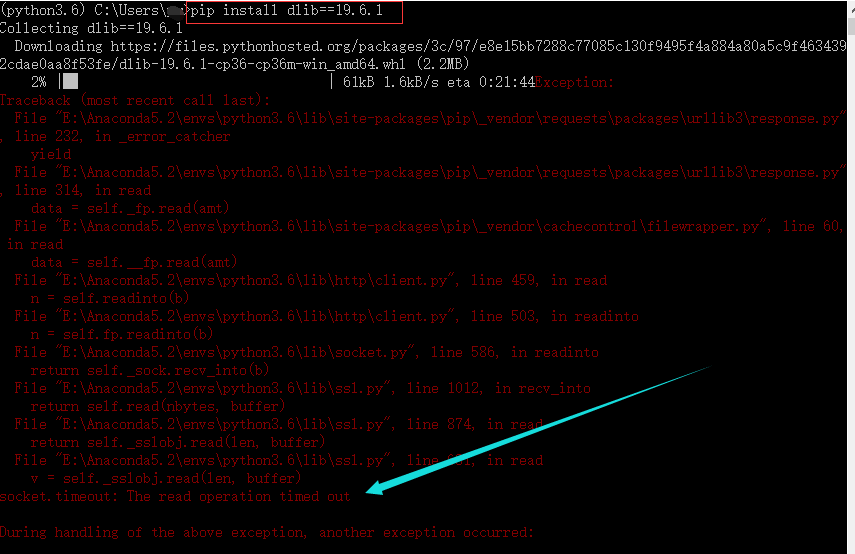
经查,说是py36没有dlib库的稳定版本,一般装19.6.1就可以用,结果也报错:
将dlib-19.6.1版本的whl文件下载到本地安装,安装成功,import可行:

二:OpenCV库踩得坑:
报错截图:

提示代码:
success, img = camera.read()
#灰度化
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
后来得知:除了路径问题还有可能是摄像头ID没对!
打开摄像头代码如下:
camera = cv2.VideoCapture(0)
success,frame = camera.read()
这两行:
1、cap = cv2.VideoCapture(0)
VideoCapture()中参数是0,表示打开笔记本的内置摄像头,其他数字则代表其他设备;参数是视频文件路径则打开视频,如cap = cv2.VideoCapture(“../demo.mp4”)
2、ret,frame = cap.read()
cap.read()按帧读取视频,ret,frame是获cap.read()方法的两个返回值。其中ret是布尔值,如果读取帧是正确的则返回True,如果文件读取到结尾,它的返回值就为False。frame就是每一帧的图像,是个三维矩阵。
注:默认摄像头索引号为0,可是如果外接USB摄像头,它的索引号就不一定是0 ;另外,像我的笔记本自带摄像头索引传0一直报错,所以我先暴力破解一下摄像头的索引号,确认一下到底是不是0!代码如下:
import cv2
ID = 0
while(1):
camera = cv2.VideoCapture(ID)
success,frame = camera.read()
if success==False:
ID += 1
else:
print(ID)
break
打印的结果是700!!
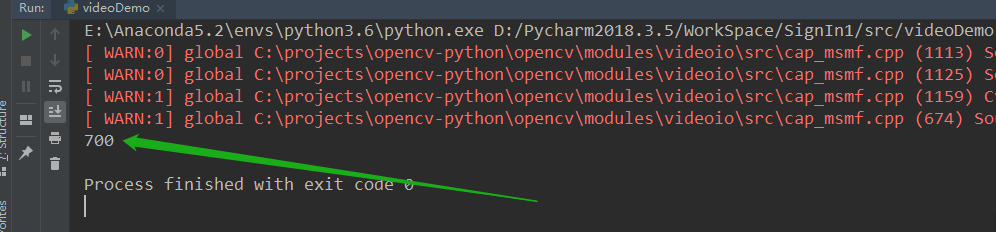
将原来代码里的索引号替换后果然OK!
importcv2
ID=700
camera=cv2.VideoCapture(ID)
while(1):
success,frame=camera.read()
cv2.imshow("hello",frame)
if cv2.waitKey(1)&0xFF==ord('q'):
break
camera.release()
cv2.destroyAllWindows()
摄像头的索引号改成了700,代码能打开摄像头了,但是窗口一片漆黑!如下:
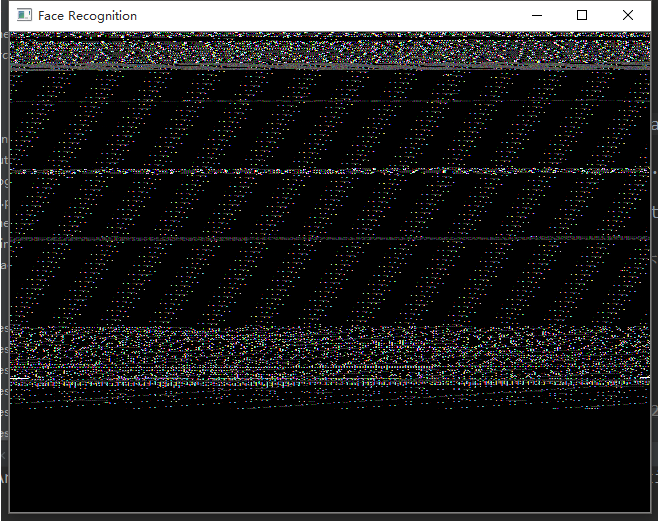
——重启解决了问题,不过此后又出现了这个情况,后来才发现是我在某软件中设置了关于摄像头的安全规则——不允许非法打开摄像头,我先扶墙缓缓。
代码如下:
"""
通过摄像头检测并标记人脸
"""
import cv2
# 加载人脸特征库
face_engine = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 加载人眼特征库
eye_engine = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
# 打开摄像头,700是摄像头索引号(0表示默认摄像头)
camera = cv2.VideoCapture(700)
while(True):
# 读取一帧的图像
success, img = camera.read()
# 灰度化
# img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸:1.3是放大比例(此参数必须大于1);13是重复识别次数(此参数用来调整精确度,越大则越精确)
faces = face_engine.detectMultiScale(img, scaleFactor=1.3, minNeighbors=13)
# 对每一张脸,进行以下操作
for (x, y, w, h) in faces:
# 用矩形框出人脸:BGR色彩体系;2表示画笔宽度
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2) # 用矩形圈出人脸
# 记录下脸部位置,作为识别眼睛的区域范围
face_area = img[y:y + h, x:x + w]
# 在记录下的脸部区域识别人眼
eyes = eye_engine.detectMultiScale(face_area)
# 对每一个识别出的人眼,进行以下操作
for (xe, ye, we, he) in eyes:
cv2.rectangle(face_area, (xe, ye), (xe + we, ye + he), (0, 255, 0), 1)
cv2.imshow('Face Recognition', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 关闭摄像头
camera.release()
# 关闭所有窗口
cv2.destroyAllWindows()
三:实现人脸识别
项目详见GitHub地址。具体功能:支持从照片、视频文件、摄像头获取人脸数据;支持自己训练模型;支持识别照片、视频文件、摄像头中的人脸。
GitHub:https://github.com/PanWeiw/CNN_FacesRecognition.git
项目环境:详见requirements.txt文件;
项目结构如图:
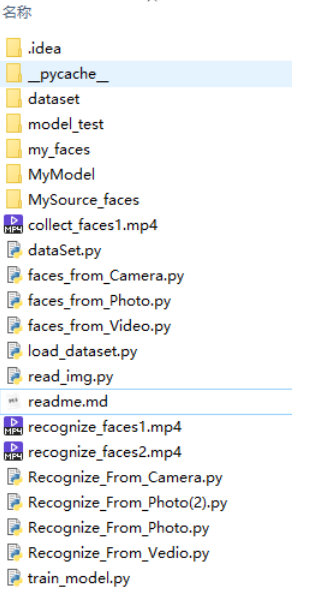
注:
1. dataset文件夹是数据集;
2. MyModel文件夹存放训练的模型问价;
3. model_test文件夹是测试模型时,存放待测照片、视频所用;
4. my_faces 和 MySource_faces文件夹是测试采集人脸数据集时所用的。
5. 采集人脸数据集:
从照片采集:faces_from_Photo.py
从视频文件采集:faces_from_Video.py
从摄像头采集:faces_from_Camera.py
加载照片的函数:read_img.py
6. 处理照片并加载标签:load_dataset.py
7. 构建并训练模型:train_model.py
处理数据集的函数:dataSet.py
8. 模型测试
识别照片中的人脸:Recognize_From_Photo.py、Recognize_From_Photo(2).py
识别视频文件中的人脸:Recognize_From_Vedio.py
识别摄像头中的人脸:Recognize_From_Camera.py