首先了解一下三个比较重要的公式:
条件概率公式:P(A|B)=P(AB)/P(B)
全概率公式: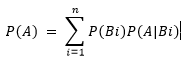
贝叶斯:P(B|A) = P(A|B)P(B)/P(A)
优 点 :在数据较少的情况下仍然有效,可以处理多类别问题。
缺 点 :对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。
朴素贝叶斯中朴素二字的含义:假设各个特征之间相互独立。即一个特征或者单词的出现可能性与它和其他单词相邻没有关系。
朴素贝叶斯中的另外一个假设:每个特征同等重要。
(尽管上述假设存在一些瑕疵,但是朴素贝叶斯的实际效果却是很好)
使用条件概率进行分类:

从词向量计算概率:

完整代码以及数据集地址:
朴素贝叶斯分类器的实现:
import numpy as np import re import random # 创建一些实验样本 def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0,1,0,1,0,1] #1 is abusive, 0 not return postingList,classVec # 创建词典 def createVocabList(dataSet): vocabSet = set([]) for document in dataSet: vocabSet = vocabSet | set(document) return vocabSet # 输出文档向量,vocabList中的单词同时在inputSet中存在为1,否则为0 # 词集模型,即将每个词出现与否作为一个特征,出现多次和出现一次效果相同 def setOfWords2Vec(vocabList, inputSet): returnVec = [0]*len(vocabList) for word in inputSet: if word in vocabList: returnVec[list(vocabList).index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) return returnVec #词袋模型,即将每个词出现次数作为特征值,出现一次和出现多次效果不同 def bagOfWords2Vec(vocabList, inputSet): returnVec = [0]*len(vocabList) for word in inputSet: if word in vocabList: returnVec[list(vocabList).index(word)] += 1 else: print("the word: %s is not in my Vocabulary!" % word) return returnVec # 训练样本 def trainNB0(trainMatrix, trainCategory): numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory) / float(numTrainDocs) ''' 利用贝叶斯进行分类时,需要计算多个概率的乘积,若有概率为0,则最后乘积也为0 为了降低这种情况的发生,将每个文档中每个单词出现的次数初始化为1 并且将分母初始化为2 ''' p0Denom = np.ones(numWords) p1Denom = np.ones(numWords) p0Sum = 2.0 p1Sum = 2.0 for i in range(numTrainDocs): if trainCategory[i] == 1: p1Denom += trainMatrix[i] p1Sum += sum(trainMatrix[i]) else: p0Denom += trainMatrix[i] p0Sum += sum(trainMatrix[i]) # 概率向量的每个元素都很小,后边需要这些元素相乘,所以为了防止向下溢出,对此处概率取对数 p0Denom = np.log(p0Denom / p0Sum) p1Denom = np.log(p1Denom / p1Sum) return p0Denom, p1Denom, pAbusive def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): p1 = sum(p1Vec * vec2Classify) + np.log(pClass1) p0 = sum(p0Vec * vec2Classify) + np.log(1 - pClass1) if p1 > p0: return 1 else: return 0 # just for test def testNB(): listOposts, listClasses = loadDataSet() myVocabList = createVocabList(listOposts) trainMatrix = [] for postinDoc in listOposts: trainMatrix.append(setOfWords2Vec(myVocabList, postinDoc)) p0, p1, pAbusive = trainNB0(trainMatrix, listClasses) testDoc = ['my', 'food'] testVec = np.array(setOfWords2Vec(myVocabList, testDoc)) print(testDoc, "the class is:%d" % classifyNB(testVec, p0, p1, pAbusive)) # 将文本转化为所需要的格式 def textParse(bigString): # !!!注意此处,书中代码有错误,将 re.split(r'W*', bigString) 改为 re.split(r'W+', bigString) listOfTokens = re.split(r'W+', bigString) # 利用正则表达式,只读取字母和数字 ret = [tok.lower() for tok in listOfTokens if len(tok) > 2] # 返回长度大于2的单词的小写形式 return ret # 利用垃圾邮件分类对朴素贝叶斯进行测试 def spamTest(): docList = []; fullTest = []; classList = [] for i in range(1, 26): #读取文件 fr = open('email/spam/%d.txt' % i) doc = fr.read() wordList = textParse(doc) # 读取垃圾邮件并转化为我们所需要的格式 docList.append(wordList) fullTest.extend(wordList) classList.append(1) wordList = textParse(open('email/ham/%d.txt' % i).read()) # 读取非垃圾邮件并转化为我们所需要的格式 docList.append(wordList) fullTest.extend(wordList) classList.append(0) vocabList = createVocabList(docList) # 创建词典 trainingSet = list(range(50)) testSet = [] for i in range(10): randIndex = int(random.uniform(0, len(trainingSet))) testSet.append(trainingSet[randIndex]) del(trainingSet[randIndex]) trainMat = []; trainClasses = [] for docIndex in trainingSet: trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) trainClasses.append(classList[docIndex]) p0V, p1V, pSpam = trainNB0(trainMat, trainClasses) errorCount = 0 for docIndex in testSet: testVec = setOfWords2Vec(vocabList, docList[docIndex]) if classifyNB(np.array(testVec), p0V, p1V, pSpam) != classList[docIndex]: errorCount += 1 rate = float(errorCount) / float(len(testSet)) #print("the error rate is: ", rate) return rate s = 0.0 for i in range(10): s += spamTest() print('total rate:', s / 10.0)