原文:https://blog.csdn.net/sinat_32176947/article/details/107141577
简介
在使用flink kafka connector的时候,一般都直接像下面这样直接拷贝模板就拿来用了:
Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); env.addSource( new FlinkKafkaConsumer011<>("topic", new SimpleStringSchema(), properties) ).print();
从来没去研究里面的代码调用流程,这两天因为需要对它进行改造,所以就研究了一下。
flink kafka connector 调用关系
想找一个自动生成调用关系的IDEA插件,找了半天没找到,只好画了一个简单的流程图,凑活看吧
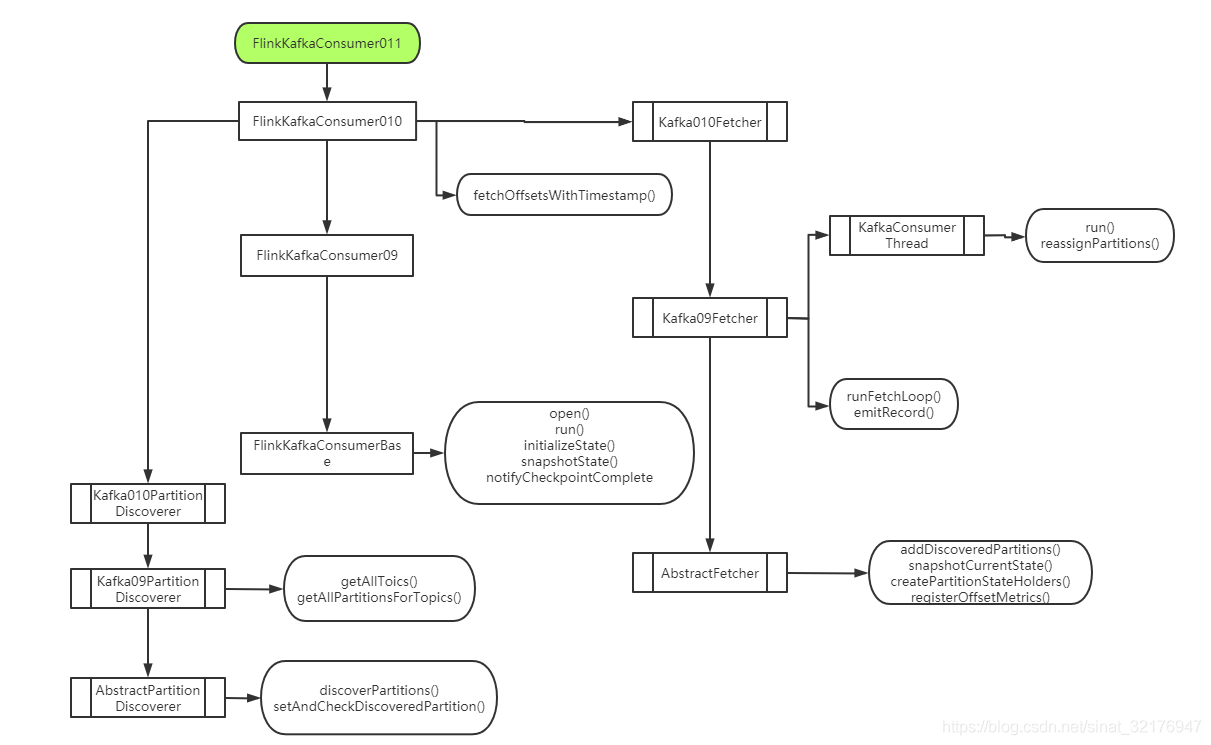
消费过程
当我们新建一个FlinkKafkaConsumer011的时候,根据继承关系,我们依次调用FlinkKafkaConsumer010、FlinkKafkaConsumer09、FlinkKafkaConsumerBase等父类的构造方法,在这过程中,还会生成每个类对应的KafkaFetcher和PartitionDiscover.
FlinkKafkaConsumer作为Flink的一个source,它除了实现了sourceFunction的open、run、cancel、close等方法之外,为了保证excatly once 语义,它也实现了CheckpointedFunction,重写了snapshotState和initializeState方法来保证任务在异常恢复的时候,能从上次checkpoint的地方恢复。
先从open方法看起,open方法的解析如下代码里的注释:
@Override public void open(Configuration configuration) throws Exception { // 设置提交模式,没有启用checkpoint则周期性向kafka提交,启用了checkpoint的话,则在checkpoint的时候向kafka集群提交offset this.offsetCommitMode = OffsetCommitModes.fromConfiguration( getIsAutoCommitEnabled(), enableCommitOnCheckpoints, ((StreamingRuntimeContext) getRuntimeContext()).isCheckpointingEnabled()); // 新建一个“分区发现器”,用于自动获取新分区,FlinkKafkaConsumer011中起作用的是Kafka09PartitionDiscoverer this.partitionDiscoverer = createPartitionDiscoverer( topicsDescriptor, getRuntimeContext().getIndexOfThisSubtask(), getRuntimeContext().getNumberOfParallelSubtasks()); this.partitionDiscoverer.open(); //获取消费的起始位置,存在subscribedPartitionsToStartOffsets这个map里 subscribedPartitionsToStartOffsets = new HashMap<>(); final List<KafkaTopicPartition> allPartitions = partitionDiscoverer.discoverPartitions(); //如果是从checkpoint恢复,则去checkpoint里获取消费的起点 if (restoredState != null) { ....... } //如果是重新启动,则根据配置的startupMode来决定从哪儿(EARLIEST/LATEST/TIMESTAMP/SPECIFIC_OFFSETS/GROUP_OFFSETS)启动消费 else { ....... } }
当open方法执行完毕后,后续就会真正开始执行我们的Flink任务,此时调用的run方法,下面是run方法到底做了什么:
@Override public void run(SourceContext<T> sourceContext) throws Exception { if (subscribedPartitionsToStartOffsets == null) { throw new Exception("The partitions were not set for the consumer"); } // 重写consumer commit之后的回调方法,并记录到metric里,供外部系统监控使用 this.successfulCommits = this.getRuntimeContext().getMetricGroup().counter(COMMITS_SUCCEEDED_METRICS_COUNTER); this.failedCommits = this.getRuntimeContext().getMetricGroup().counter(COMMITS_FAILED_METRICS_COUNTER); this.offsetCommitCallback = new KafkaCommitCallback() { @Override public void onSuccess() { successfulCommits.inc(); } @Override public void onException(Throwable cause) { LOG.warn("Async Kafka commit failed.", cause); failedCommits.inc(); } }; // 判断是否没有topic消费,是的话就暂时进入闲置状态,如果partitionDiscover发现了要消费的topic,就自动启动 if (subscribedPartitionsToStartOffsets.isEmpty()) { sourceContext.markAsTemporarilyIdle(); } //创建一个Fetcher,这是和kafka交互的核心类,具体工作的类是Kafka09Fetcher this.kafkaFetcher = createFetcher( sourceContext, subscribedPartitionsToStartOffsets, periodicWatermarkAssigner, punctuatedWatermarkAssigner, (StreamingRuntimeContext) getRuntimeContext(), offsetCommitMode, getRuntimeContext().getMetricGroup().addGroup(KAFKA_CONSUMER_METRICS_GROUP), useMetrics); if (!running) { return; } //如果discoveryIntervalMillis不等于Long.MIN_VALUE,则启用自动发现新partition,通过在kafka consumer的prop里prop.put("flink.partition-discovery.interval-millis","30000")这样来配置 if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) { //若不启用分区自动发现,则直接运行消费数据的循环 kafkaFetcher.runFetchLoop(); } else { //若启用分区自动发现,则运行消费数据的循环之外,还会启动一个分区发现的线程 runWithPartitionDiscovery(); } }
看下runWithPartitionDiscovery方法的逻辑:
private void runWithPartitionDiscovery() throws Exception { final AtomicReference<Exception> discoveryLoopErrorRef = new AtomicReference<>(); //创建分区发现线程 createAndStartDiscoveryLoop(discoveryLoopErrorRef); //启动正常的消费程序 kafkaFetcher.runFetchLoop(); //唤醒分区发现线程 partitionDiscoverer.wakeup(); joinDiscoveryLoopThread(); ....... } private void createAndStartDiscoveryLoop(AtomicReference<Exception> discoveryLoopErrorRef) { discoveryLoopThread = new Thread(() -> { ....... try { //获取“新发现”的分区,注意是新发型的分区 discoveredPartitions = partitionDiscoverer.discoverPartitions(); } catch (AbstractPartitionDiscoverer.WakeupException | AbstractPartitionDiscoverer.ClosedException e) { if (running && !discoveredPartitions.isEmpty()) { //如果获取到了,就加到kafkaFetcher里供consumer消费 kafkaFetcher.addDiscoveredPartitions(discoveredPartitions); } ....... discoveryLoopThread.start(); }
看看新分区发现和怎么把新分区添加到consumer的逻辑
public List<KafkaTopicPartition> discoverPartitions() throws WakeupException, ClosedException { ....... //如果consumer写死的是一个topic,则只消费这一个Topic if (topicsDescriptor.isFixedTopics()) { newDiscoveredPartitions = getAllPartitionsForTopics(topicsDescriptor.getFixedTopics()); } else { //先获取集群里所有Topic List<String> matchedTopics = getAllTopics(); // 判断是否匹配我们配置里指定的Topic格式,不匹配就移除 Iterator<String> iter = matchedTopics.iterator(); while (iter.hasNext()) { if (!topicsDescriptor.getTopicPattern().matcher(iter.next()).matches()) { iter.remove(); } } ....... } // 移除已经在消费的Partition,获取“新发现”的Partiton if (newDiscoveredPartitions == null || newDiscoveredPartitions.isEmpty()) { throw new RuntimeException("Unable to retrieve any partitions with KafkaTopicsDescriptor: " + topicsDescriptor); } else { Iterator<KafkaTopicPartition> iter = newDiscoveredPartitions.iterator(); KafkaTopicPartition nextPartition; while (iter.hasNext()) { nextPartition = iter.next(); if (!setAndCheckDiscoveredPartition(nextPartition)) { iter.remove(); } } } return newDiscoveredPartitions; ....... } public void addDiscoveredPartitions(List<KafkaTopicPartition> newPartitions) throws IOException, ClassNotFoundException { ....... //如果发现了新分区,先记到state里,再记到一个“未分配的parition”的队列里 for (KafkaTopicPartitionState<KPH> newPartitionState : newPartitionStates) { // the ordering is crucial here; first register the state holder, then // push it to the partitions queue to be read subscribedPartitionStates.add(newPartitionState); unassignedPartitionsQueue.add(newPartitionState); } }
看完了新分区发现的逻辑,看看KafkaFetcher怎么从Topic里取数据的:
public Kafka09Fetcher(......) throws Exception { super(......) //创建一个消费线程,注意这里把unassignedPartitionsQueue传到里面去了 this.consumerThread = new KafkaConsumerThread( LOG, handover, kafkaProperties, unassignedPartitionsQueue, createCallBridge(), getFetcherName() + " for " + taskNameWithSubtasks, pollTimeout, useMetrics, consumerMetricGroup, subtaskMetricGroup); } @Override public void runFetchLoop() throws Exception { try { ....... // 启动消费线程 consumerThread.start(); while (running) { final ConsumerRecords<byte[], byte[]> records = handover.pollNext(); // 逐个分区的消费数据 for (KafkaTopicPartitionState<TopicPartition> partition : subscribedPartitionStates()) { //获取消费出来的数据,并序列化,加上是否消费完毕的判断, //这些我们可以通过重写序列化方法来修改 //比如说我们为了测试方便可以设置消费到一百条就停止消费 //或者把消息的key和offset都加到我们消费出来的数据里。 List<ConsumerRecord<byte[], byte[]>> partitionRecords = records.records(partition.getKafkaPartitionHandle()); for (ConsumerRecord<byte[], byte[]> record : partitionRecords) { final T value = deserializer.deserialize( record.key(), record.value(), record.topic(), record.partition(), record.offset()); if (deserializer.isEndOfStream(value)) { // end of stream signaled running = false; break; } // 把消费到数据往下游发送,并更新offset记录和watermark状态 emitRecord(value, partition, record.offset(), record); } } } } finally { // this signals the consumer thread that no more work is to be done consumerThread.shutdown(); }
到现在还没发现是怎么发现的新分区,继续看kafkaConsumerThread
@Override public void run() { ...... ConsumerRecords<byte[], byte[]> records = null; List<KafkaTopicPartitionState<TopicPartition>> newPartitions; while (running) { ...... if (hasAssignedPartitions) { //后续试探性的从unassignedPartitionsQueue获取新分区,没有新分区则返回null newPartitions = unassignedPartitionsQueue.pollBatch(); } else { //第一次启动时,会一直阻塞直到unassignedPartitionsQueue返回至少一个Partition newPartitions = unassignedPartitionsQueue.getBatchBlocking(); } //第一次启动,必不为null,获取到parition进行消费,后续若发现新分区再重新分配 if (newPartitions != null) { //将获取到的partiton进行分配,并将hasAssignedPartitions置位true reassignPartitions(newPartitions); } ...... } } void reassignPartitions(List<KafkaTopicPartitionState<TopicPartition>> newPartitions) throws Exception { ...... final KafkaConsumer<byte[], byte[]> consumerTmp; //在重新分配parition的时候,需要获取锁 synchronized (consumerReassignmentLock) { consumerTmp = this.consumer; this.consumer = null; } final Map<TopicPartition, Long> oldPartitionAssignmentsToPosition = new HashMap<>(); try { //获取正在消费的parition和对应的offset信息 for (TopicPartition oldPartition : consumerTmp.assignment()) { oldPartitionAssignmentsToPosition.put(oldPartition, consumerTmp.position(oldPartition)); } final List<TopicPartition> newPartitionAssignments = new ArrayList<>(newPartitions.size() + oldPartitionAssignmentsToPosition.size()); newPartitionAssignments.addAll(oldPartitionAssignmentsToPosition.keySet()); //将“新发现”的分区加到待消费的组中 newPartitionAssignments.addAll(convertKafkaPartitions(newPartitions)); // 重新分配分区信息 consumerCallBridge.assignPartitions(consumerTmp, newPartitionAssignments); reassignmentStarted = true; // 老分区恢复到之前的消费位置 for (Map.Entry<TopicPartition, Long> oldPartitionToPosition : oldPartitionAssignmentsToPosition.entrySet()) { consumerTmp.seek(oldPartitionToPosition.getKey(), oldPartitionToPosition.getValue()); } //设置新发现的分区的消费起始位置,默认从最早开始消费,如果是第一次启动或者从检查点恢复则根据情况来决定从哪儿消费 for (KafkaTopicPartitionState<TopicPartition> newPartitionState : newPartitions) { ...... } //catch部分,若重新分配parition失败,将旧parition和offset恢复到原有位置 ...... }
checkpoint过程
进行checkpoint
@Override public final void snapshotState(FunctionSnapshotContext context) throws Exception { if (!running) { LOG.debug("snapshotState() called on closed source"); } else { unionOffsetStates.clear(); final AbstractFetcher<?, ?> fetcher = this.kafkaFetcher; if (fetcher == null) { // fetcher 没有初始化, 记录设置的起始位置或者从上一个checkpoint恢复出来的记录值 ....... } else { //从fetcher里获取当前消费的partition和对应的offset HashMap<KafkaTopicPartition, Long> currentOffsets = fetcher.snapshotCurrentState(); for (Map.Entry<KafkaTopicPartition, Long> kafkaTopicPartitionLongEntry : currentOffsets.entrySet()) { unionOffsetStates.add( Tuple2.of(kafkaTopicPartitionLongEntry.getKey(), kafkaTopicPartitionLongEntry.getValue())); } } } } public HashMap<KafkaTopicPartition, Long> snapshotCurrentState() { // checkpoint的过程有锁,过于频繁的chekcpoint会对consumer的性能有影响,五分钟左右其实很足够 assert Thread.holdsLock(checkpointLock); HashMap<KafkaTopicPartition, Long> state = new HashMap<>(subscribedPartitionStates.size()); for (KafkaTopicPartitionState<KPH> partition : subscribedPartitionStates) { state.put(partition.getKafkaTopicPartition(), partition.getOffset()); } return state; }
从checkpoint恢复过程和感知checkpoint是否完成没什么好说的,一个就是简单的从保存点对应的文件中获取记录和值;加了一些错误判断和异常处理;感知chekcpoint完成之后,就将检查点对应的offset提交到kafka中这些都是常规处理了,没有那么复杂。