本文转自Rancher Labs
作者介绍
王海龙,Rancher中国社区技术经理,负责Rancher中国技术社区的维护和运营。拥有6年的云计算领域经验,经历了OpenStack到Kubernetes的技术变革,无论底层操作系统Linux,还是虚拟化KVM或是Docker容器技术都有丰富的运维和实践经验。
Rancher提供两种安装方法,单节点和高可用安装。单节点安装允许用户快速部署适用于短期开发测试为目的的安装工作。高可用部署明显更适合Rancher的长期使用。
在实际使用中可能会遇到需要将Rancher Server迁移到其他的节点或local集群去管理的情况。 虽然可以使用最简单的import集群方式纳管,但带来的问题是后续无法做集群的管理和升级维护,而且一些namespace和project的关联关系将会消失。所以本文主要介绍如何将Rancher Server迁移到其他节点或local集群。
本文主要针对3个场景去讲解如何迁移Rancher Server:
-
Rancher单节点安装迁移至其他主机
-
Rancher单节点安装迁移至高可用安装
-
Rancher高可用安装迁移至其他Local集群
重要说明
-
Rancher 官方文档文档中并没有说明支持以下场景的迁移,本文档只是利用一些Rancher和RKE现有的功能实现迁移。
-
如果您在此过程中遇到问题,则应该熟悉Rancher架构/故障排除
-
迁移非常危险,迁移前一定刚要做好备份,以免发生意外无法恢复
-
您应该熟悉单节点安装和高可用安装之间的体系结构差异
-
本文档基于Rancher 2.4.x测试,其他版本操作可能会略有不同
-
本文档主要讲解Rancher Server的迁移,迁移过程中不会影响业务集群的使用
准备集群直连 kubeconfig 配置文件
默认情况下, Rancher UI 上复制的 kubeconfig 通过cluster agent代理连接到 kubernetes 集群。变更 Rancher Server会导致cluster agent无法连接 Rancher Server,从而导致kubectl无法使用 Rancher UI 上复制的 kubeconfig 去操作 kubernetes 集群。但可以使用kubectl --context <CLUSTER_NAME>-fqdn 直接连接kubernetes集群进行操作。所以在执行迁移之前,请准备好所有集群的直连 kubeconfig 配置文件。
Rancher v2.2.2以及之后的版本,可以直接从UI上下载kubeconfig文件。
Rancher v2.2.2之前的版本,请参考:恢复 kubectl 配置文件
场景1:Rancher单节点安装迁移至其他主机
Rancher单节点安装迁移至其他主机,只需要将旧集群Rancher Server容器的/var/lib/rancher目录打包,然后替换到新Rancher Server对应的目录,最后启动新Rancher Server容器之后再更新agent相关配置即可。
1. Rancher 单节点安装
提示:以下步骤创建用于演示迁移的 Rancher 单节点环境,如果您需要迁移正式环境可以跳过此步骤。
执行以下 docker 命令运行单节点 Rancher Server 服务
docker run -itd -p 80:80 -p 443:443 --restart=unless-stopped rancher/rancher:v2.4.3
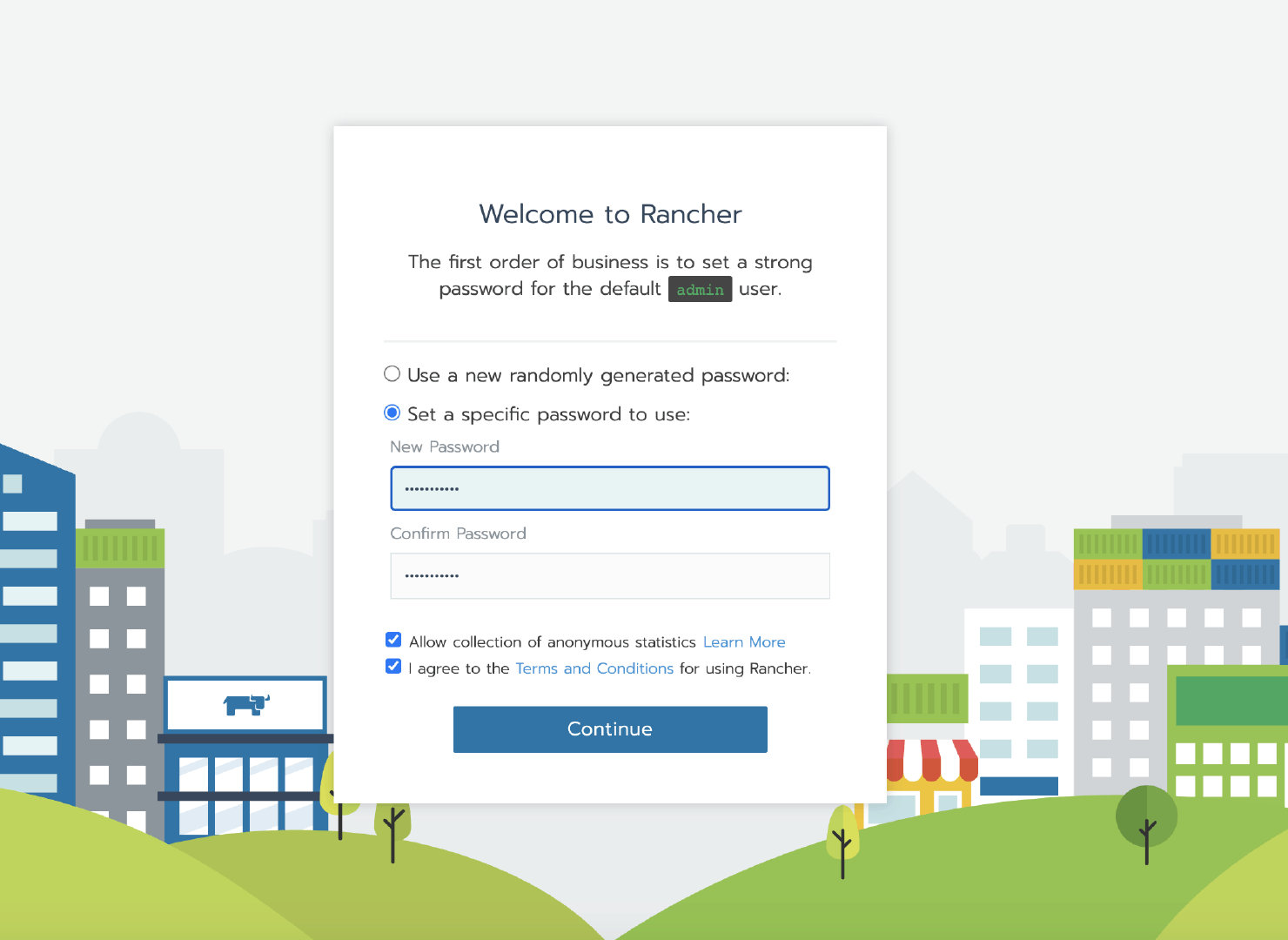
等容器初始化完成后,通过节点 IP 访问 Rancher Server UI,设置密码并登录。
2. 创建自定义集群
提示: 以下步骤创建用于演示的业务集群,用来验证 Rancher 迁移后数据是否丢失,如果您需要迁移正式环境可以跳过此步骤。
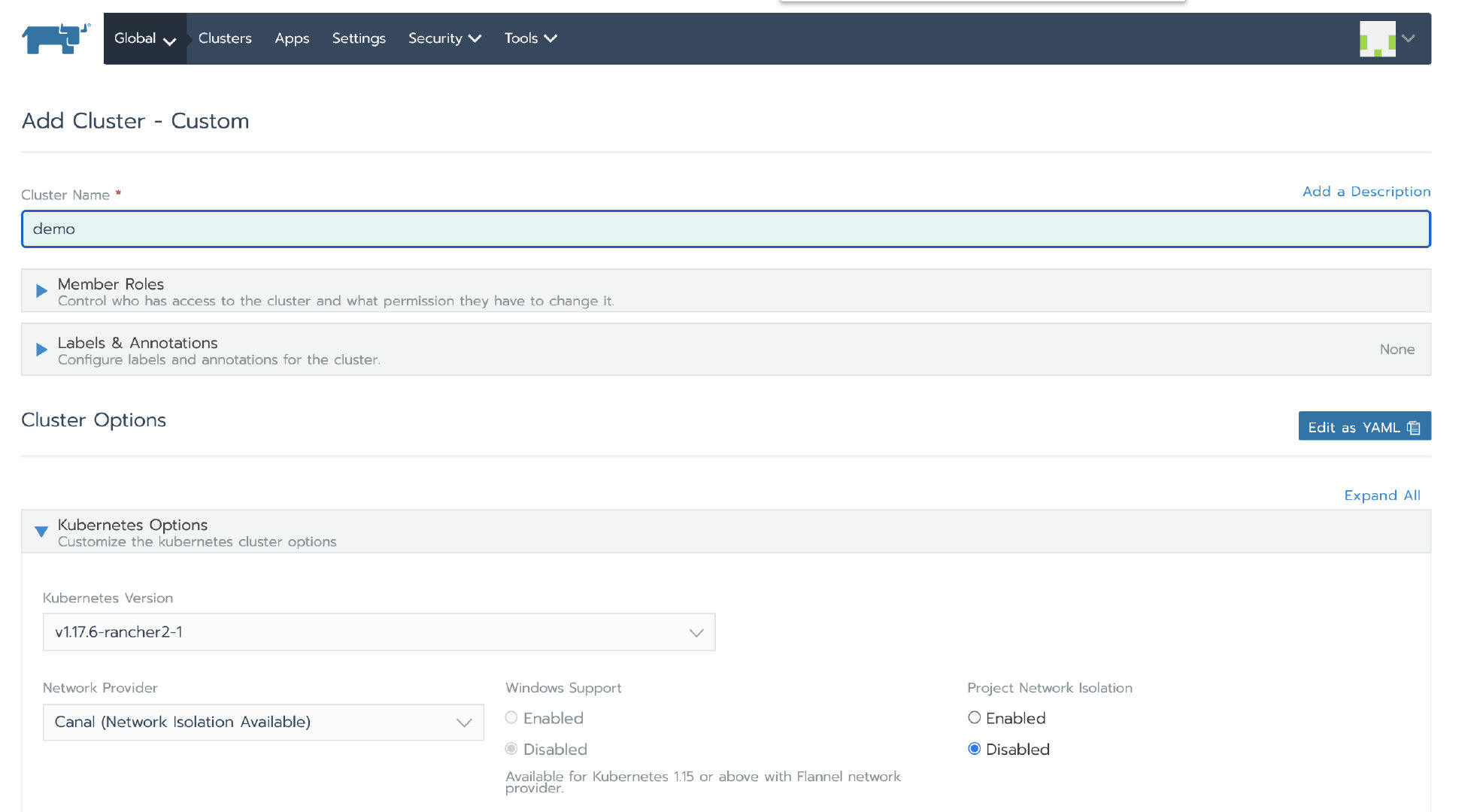
登录 Rancher UI 后,添加一个自定义集群
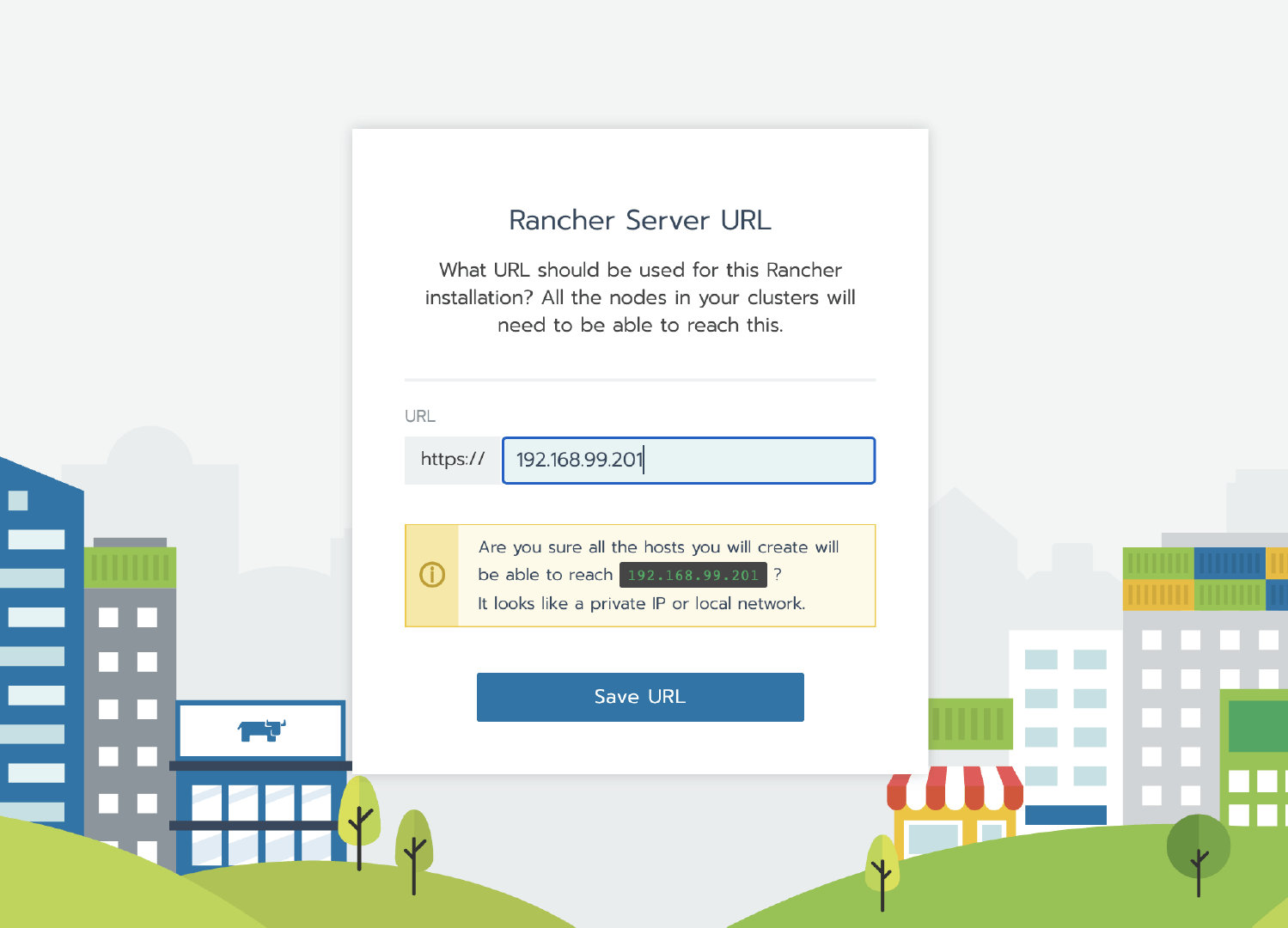
授权集群访问地址设置为启用,FQDN 和证书可以不用填写。
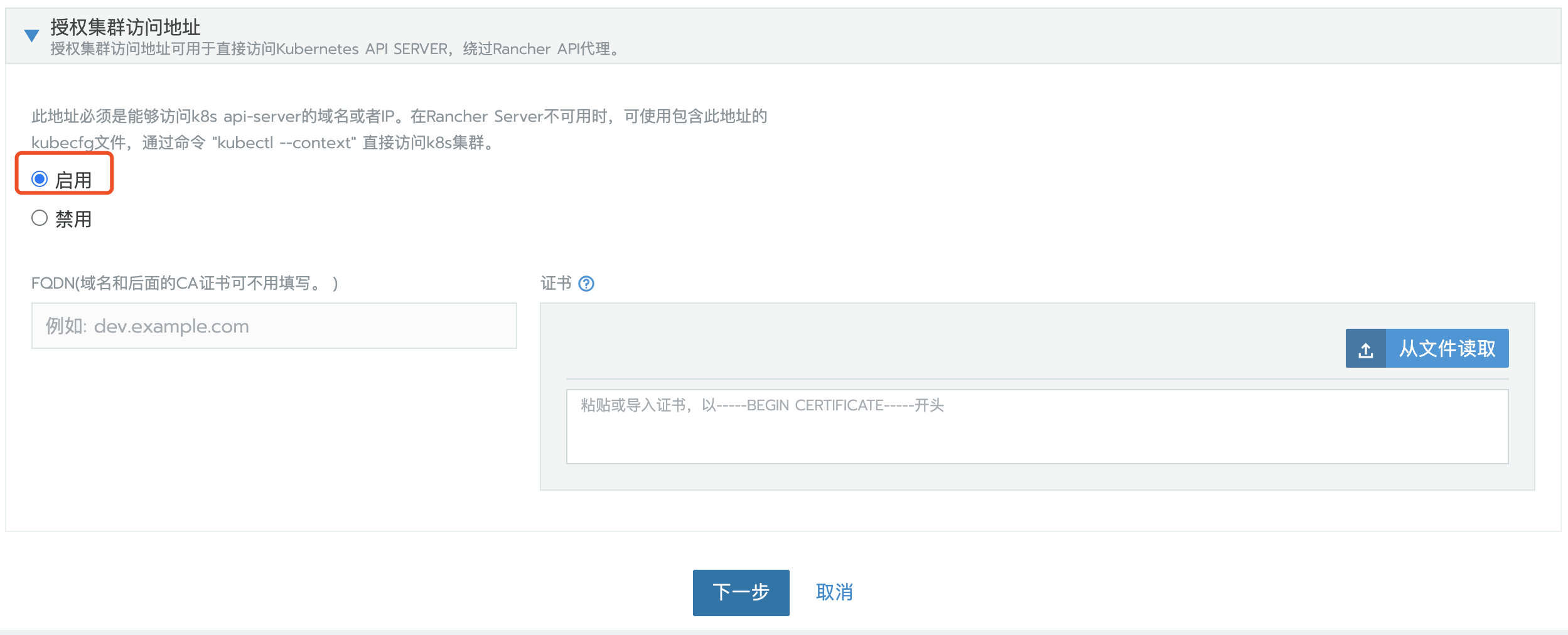
注意:
这一步很关键。因为Rancher 迁移后,地址或者 token 或者证书的变更,将会导致 agent 无法连接 Rancher Server。迁移后,需要通过 kubectl 去编辑配置文件更新一些 agent 相关的参数。默认 UI 上的 kubeconfig文件是通过 agent 代理连接到 Kubernetes,如果 agent 无法连接 Rancher Server,则通过这个 kubeconfig 文件也无法访问 Kubernetes 集群。开启授权集群访问地址功能会生成多个 Contexts Cluster,这些 Contexts Cluster 是直连 Kubernetes,不通过 agent 代理。如果业务集群未开启这个功能,可以通过编辑集群来开启这个功能。
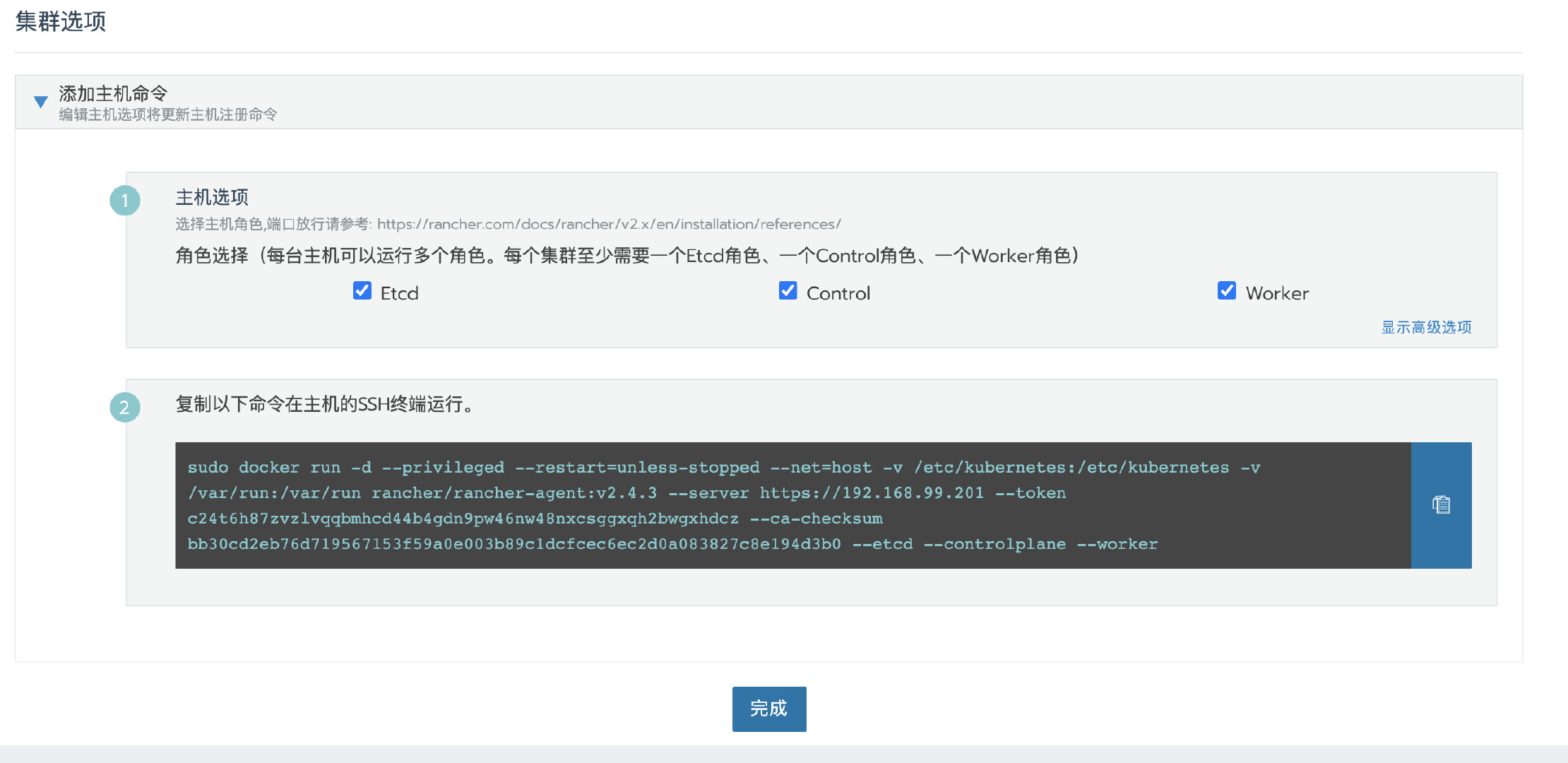
点击下一步,根据预先分配的节点角色选择需要的角色,然后复制命令到主机终端执行。
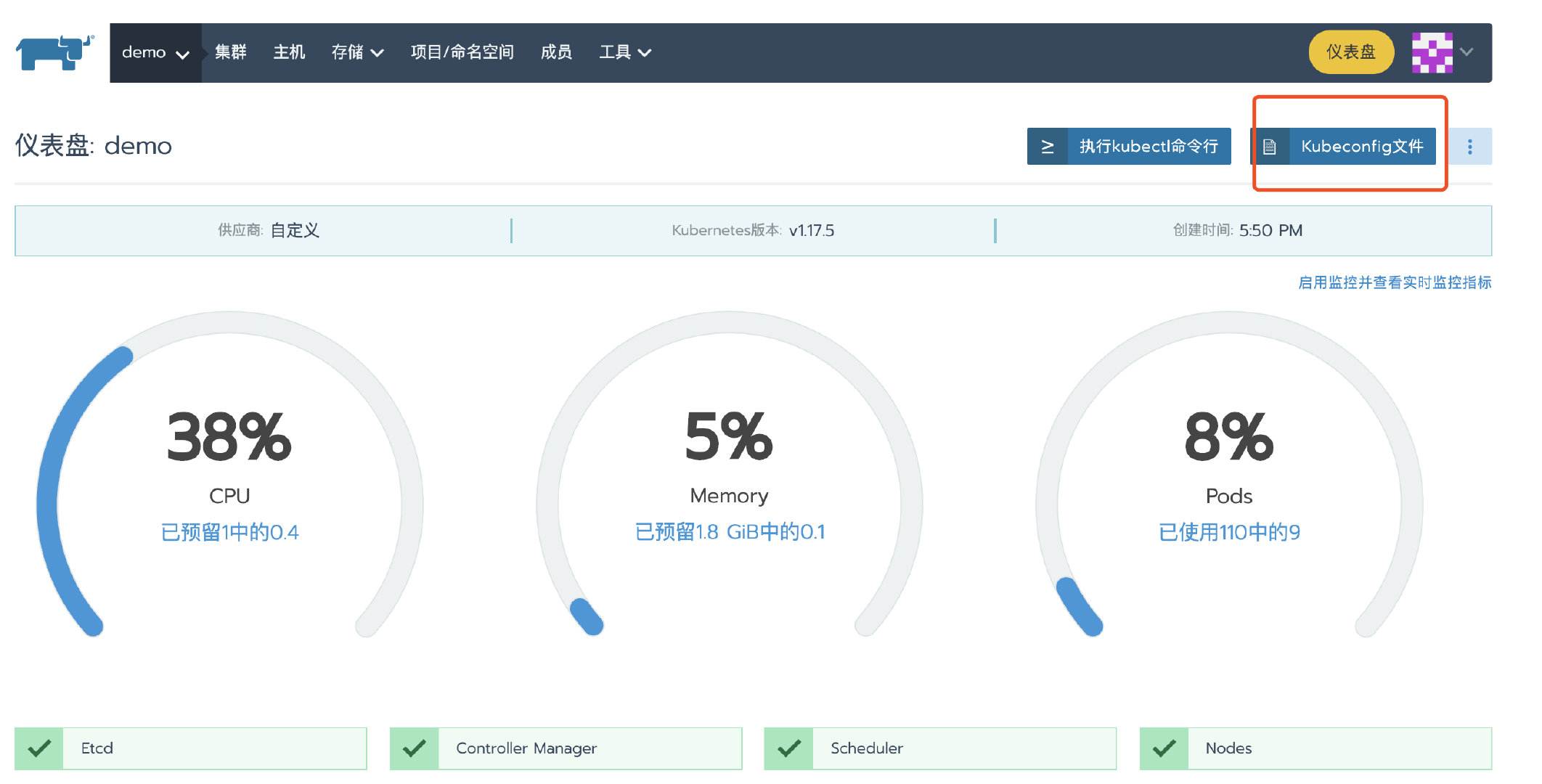
集群部署完成后,进入集群首页,点击kubeconfig文件按钮。在弹窗页面中复制 kubeconfg 配置文件备用。
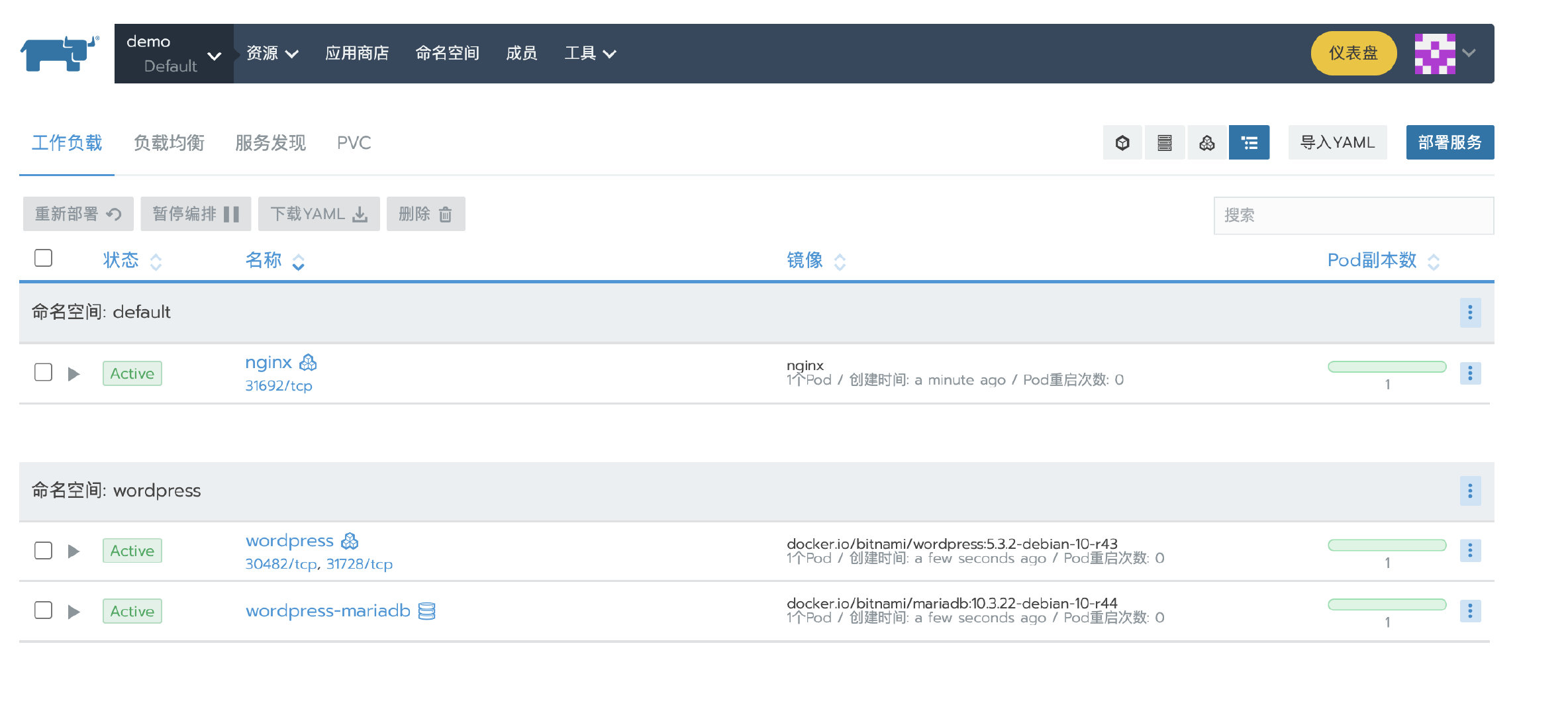
3.部署测试应用
部署一个nginx workload。再从应用商店部署一个测试应用。
4. 备份单节点Racher Server数据
docker create --volumes-from <RANCHER_CONTAINER_NAME> --name rancher-data-<DATE> rancher/rancher:<RANCHER_CONTAINER_TAG>
docker run --volumes-from rancher-data-<DATE> -v $PWD:/backup:z busybox tar pzcvf /backup/rancher-data-backup-<RANCHER_VERSION>-<DATE>.tar.gz -C /var/lib rancher
详细请参考Rancher中文官网单节点备份指南。
5. 将生成的rancher-data-backup-<RANCHER_VERSION>-<DATE>.tar.gz复制到新的Rancher Server节点
scp rancher-data-backup-<RANCHER_VERSION>-<DATE>.tar.gz root@<new_rancher_ip>:/opt/
6. 使用备份数据启动新节点Rancher Server
如果原Rancher Server通过使用已有的自签名证书或使用已有的可信证书安装,迁移时,需要将证书一起复制到新Rancher Server,使用相同启动命令挂载证书和备份数据启动Rancher Server。
cd /opt && tar -xvz -f rancher-data-backup-<RANCHER_VERSION>-<DATE>.tar.gz
docker run -itd -p 80:80 -p 443:443 -v /opt/rancher:/var/lib/rancher --restart=unless-stopped rancher/rancher:v2.4.3
7. 更新Rancher Server IP或域名
注意:
如果您的环境使用自签名证书或Let's Encrypt 证书,并且配置域名访问Rancher Server。迁移之后集群状态为
Active,请直接跳到第9步去验证集群。
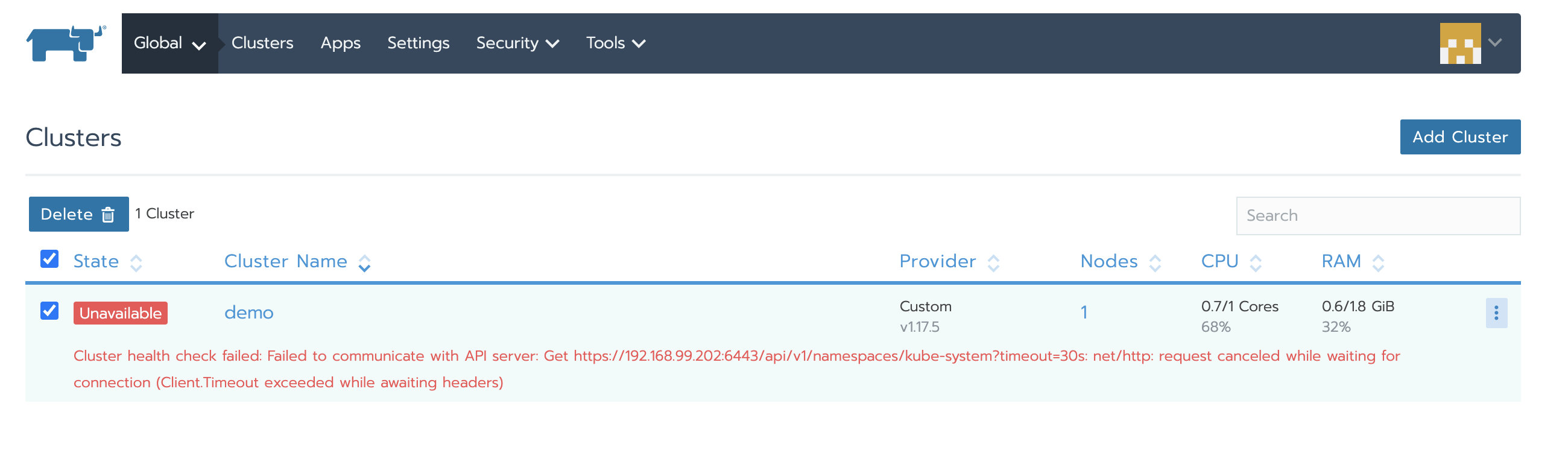
此时访问新的Rancher Server就可以看见已经被管理的Kubernetes集群了,但此时集群状态是unavailable,因为agent还连的是旧Rancher Server所以需要更新agent信息。
-
依次访问全局 > 系统设置,页面往下翻找到server-url文件
-
单击右侧的省略号菜单,选择升级
-
修改server-url地址为新Rancher Server的地址
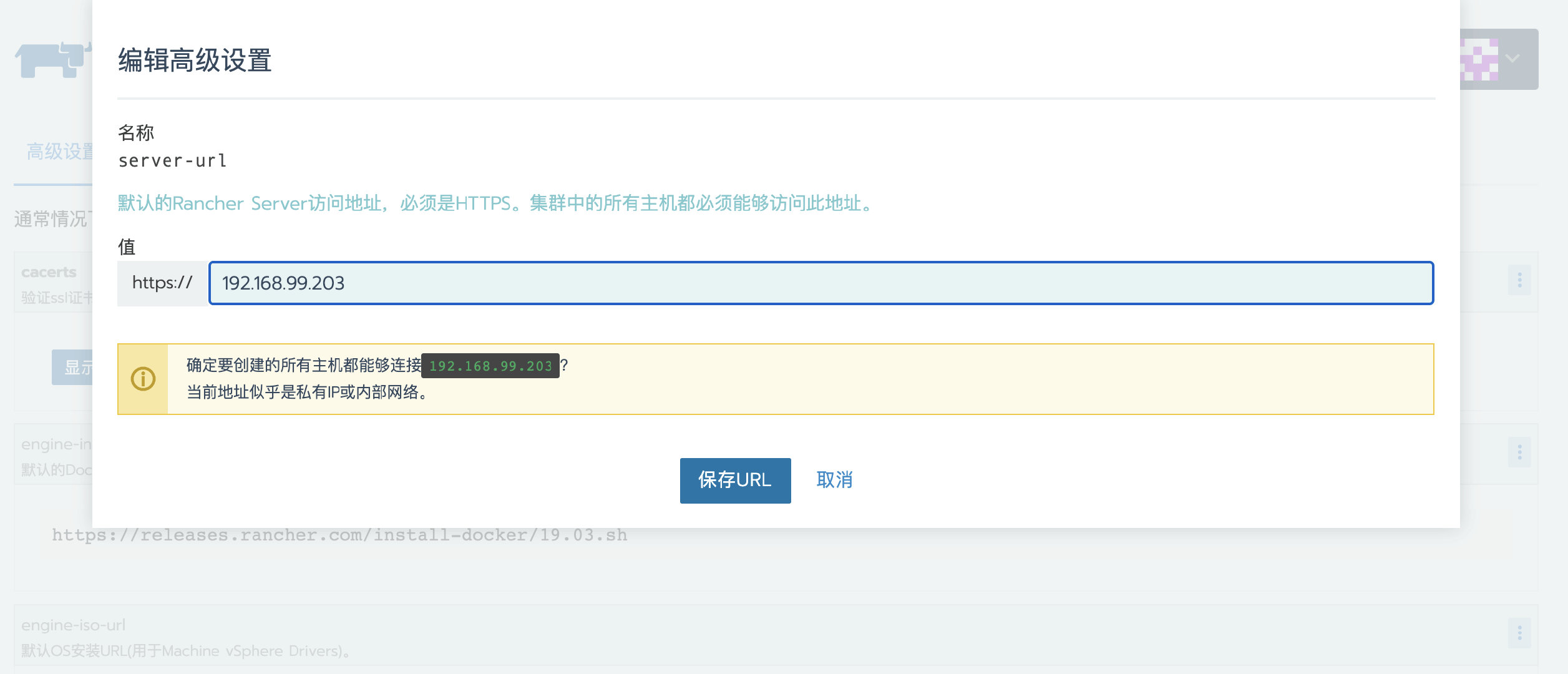
- 保存
8. 更新agent配置
通过新域名或IP登录 Rancher Server;
通过浏览器地址栏查询集群ID, c/后面以c开头的字段即为集群 ID,本例的集群ID为c-4wzvf;
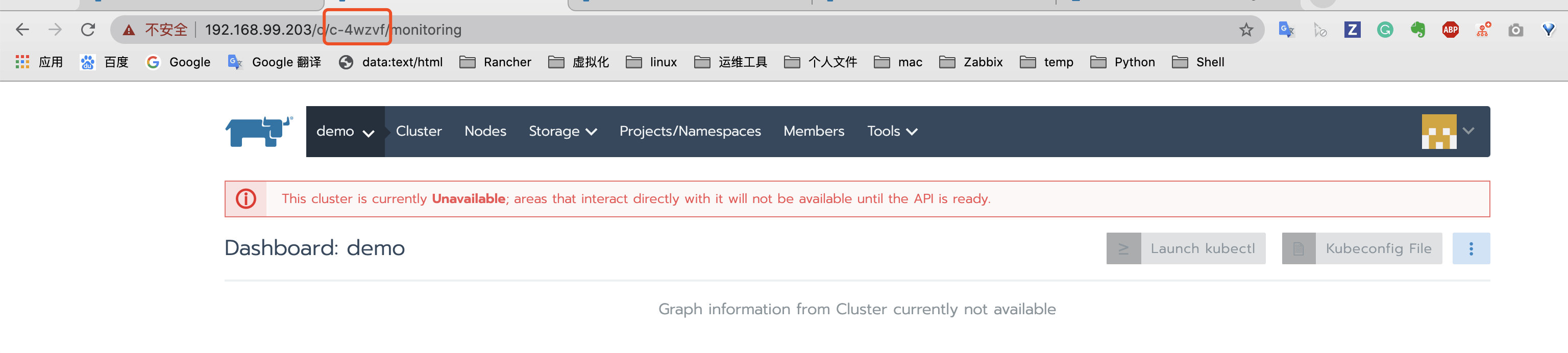
-
访问https://<新的server_url>/v3/clusters/<集群ID>/clusterregistrationtokens页面;
-
打开
clusterRegistrationTokens页面后,定位到data字段;找到insecureCommand字段,复制 YAML 连接备用;
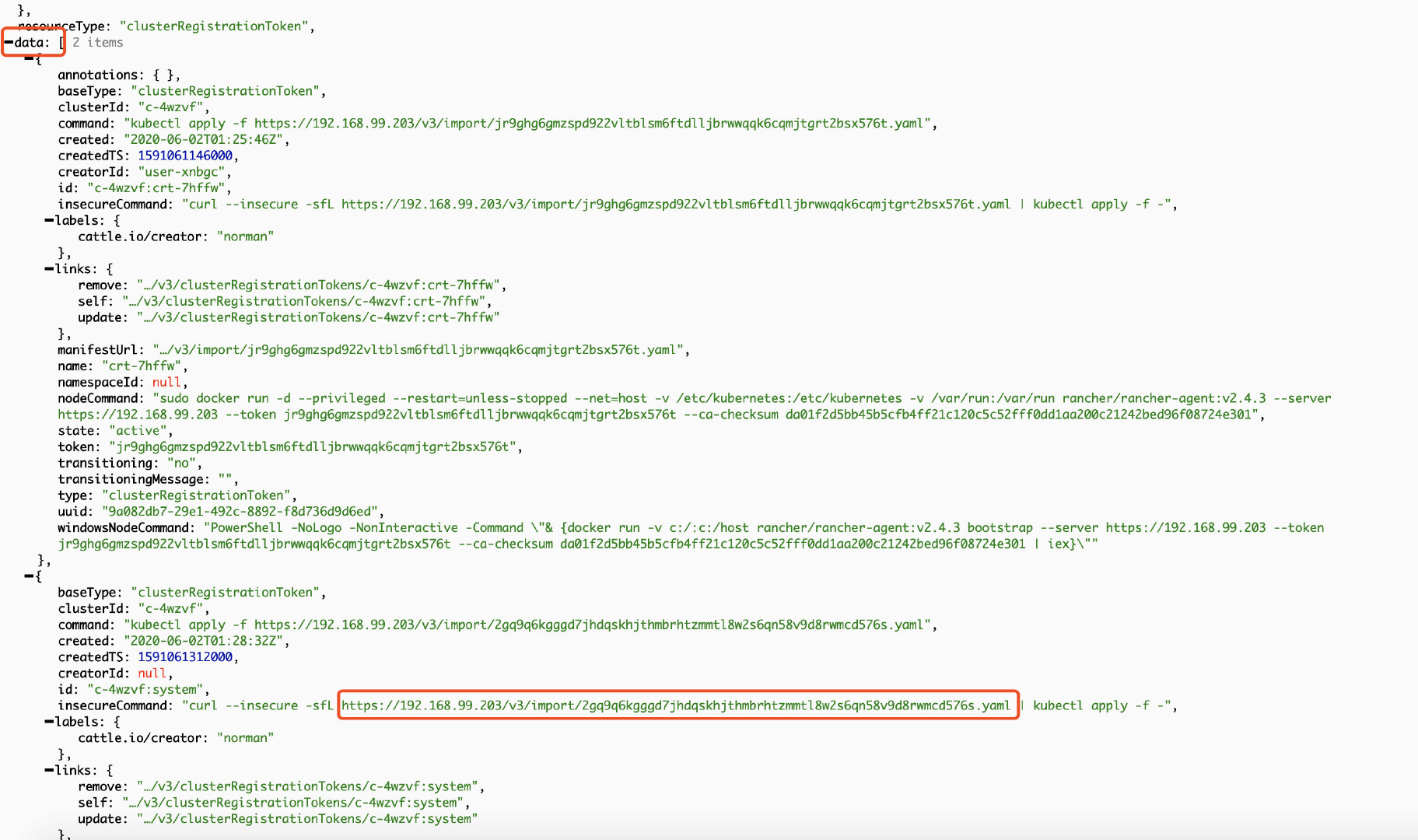
可能会有多组
"baseType": "clusterRegistrationToken",如上图。这种情况以createdTS最大、时间最新的一组为准,一般是最后一组。
使用kubectl工具,通过前文中准备的直连kubeconfig配置文件和上面步骤中获取的 YAML 文件,执行以下命令更新agent相关配置。
curl --insecure -sfL <替换为上面步骤获取的YAML文件链接> | kubectl --context=xxx apply -f -
关于--context=xxx说明请参考直接使用下游集群进行身份验证。
9. 验证
过一会,集群变为Active状态,然后验证我们之前部署的应用是否可用。
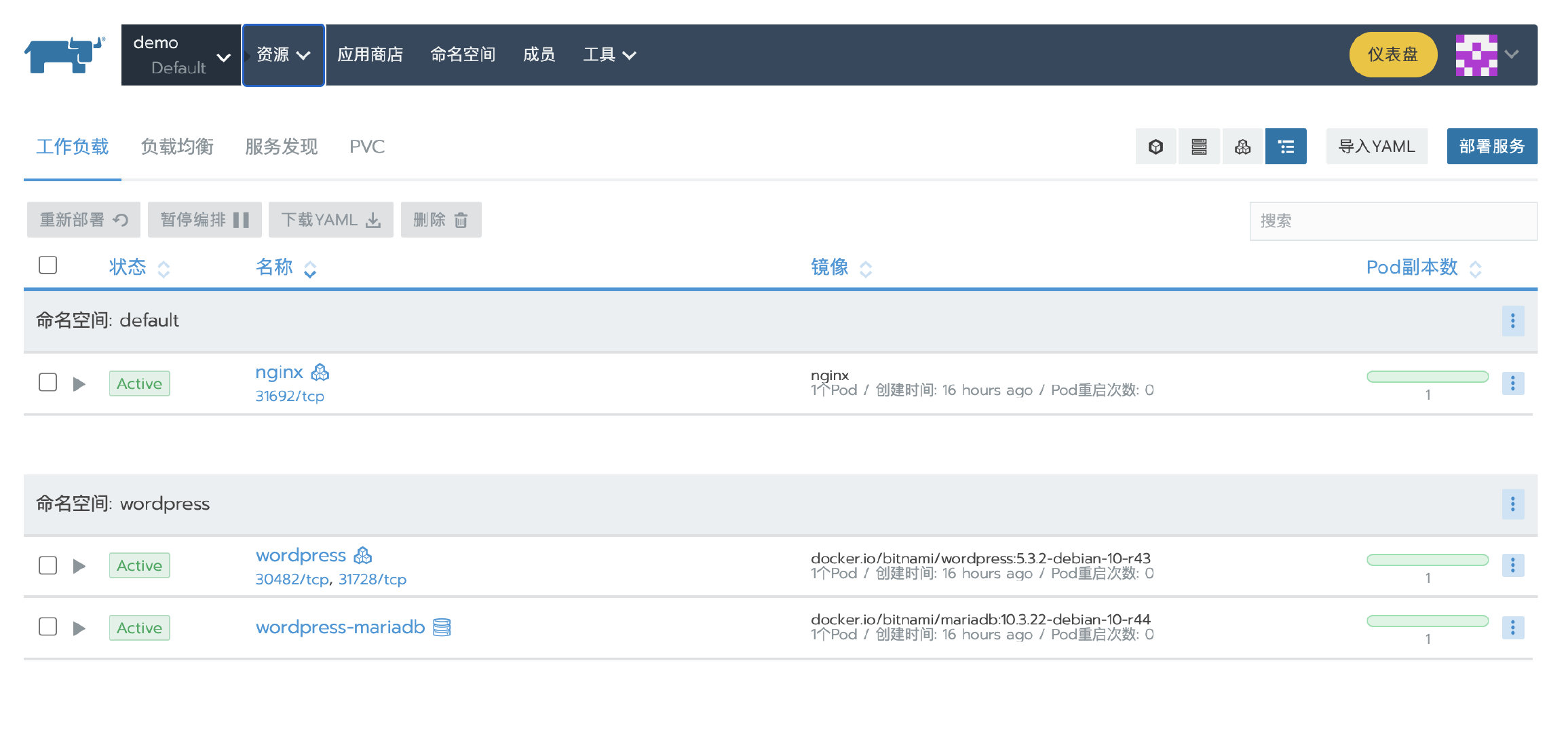
场景2:Rancher单节点安装迁移至高可用安装
从单个节点迁移到Rancher的高可用性安装的过程可以概括为以下几个步骤:
在Rancher单节点实例上:
-
备份Rancher单节点容器
-
备份etcd快照
-
停止旧的Rancher单节点容器
在RKE Local集群上:
-
使用RKE启动Rancher Local集群
-
利用rke etcd snapshot-restore,将单节点备份的etcd快照恢复到RKE HA
-
在RKE Local集群中安装Rancher
-
更新Local集群和业务集群的相关配置,使agent可以连接到正确的Rancher Server
在单节点Rancher Server上操作
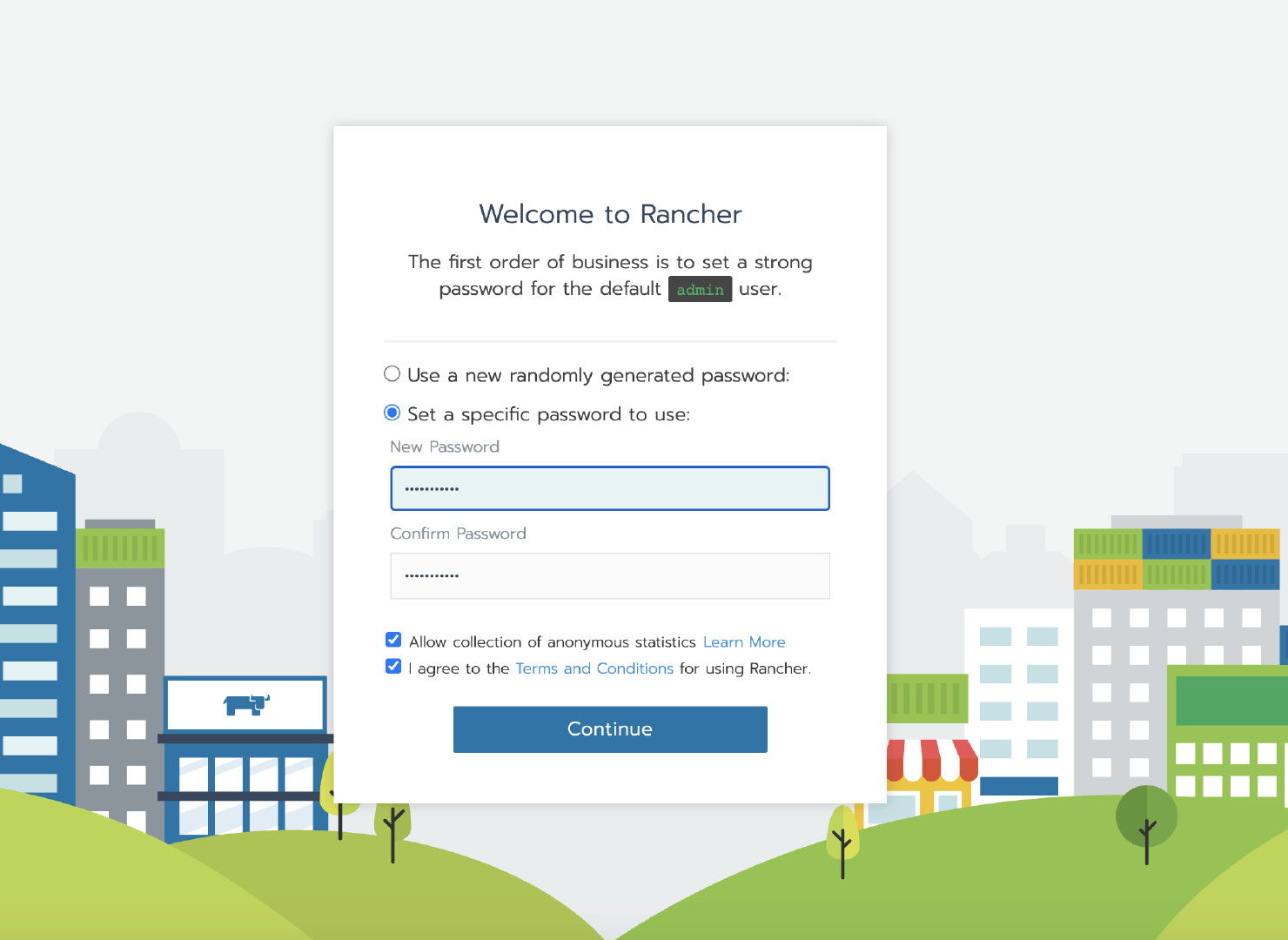
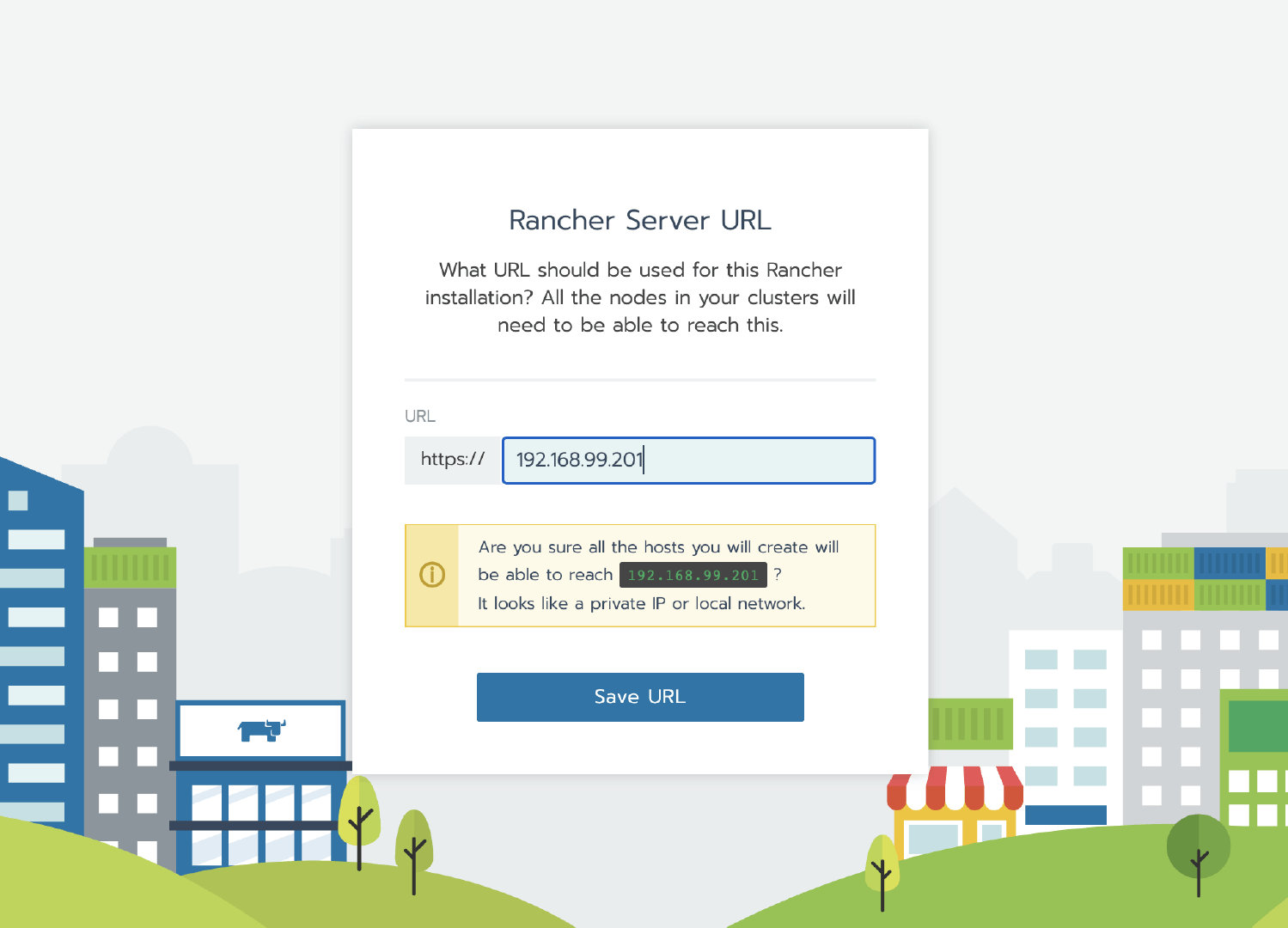
1. Rancher 单节点安装
提示: 以下步骤创建用于演示迁移的 Rancher 环境,如果您需要迁移正式环境可以跳过此步骤。
执行以下 docker 命令运行单节点 Rancher Server 服务
docker run -itd -p 80:80 -p 443:443 --restart=unless-stopped rancher/rancher:v2.4.3
等容器初始化完成后,通过节点 IP 访问 Rancher Server UI,设置密码并登录。
2. 创建自定义集群
提示: 以下步骤创建用于演示的业务集群,用来验证 Rancher 迁移后数据是否丢失,如果您需要迁移正式环境可以跳过此步骤。
登录 Rancher UI 后,添加一个自定义集群
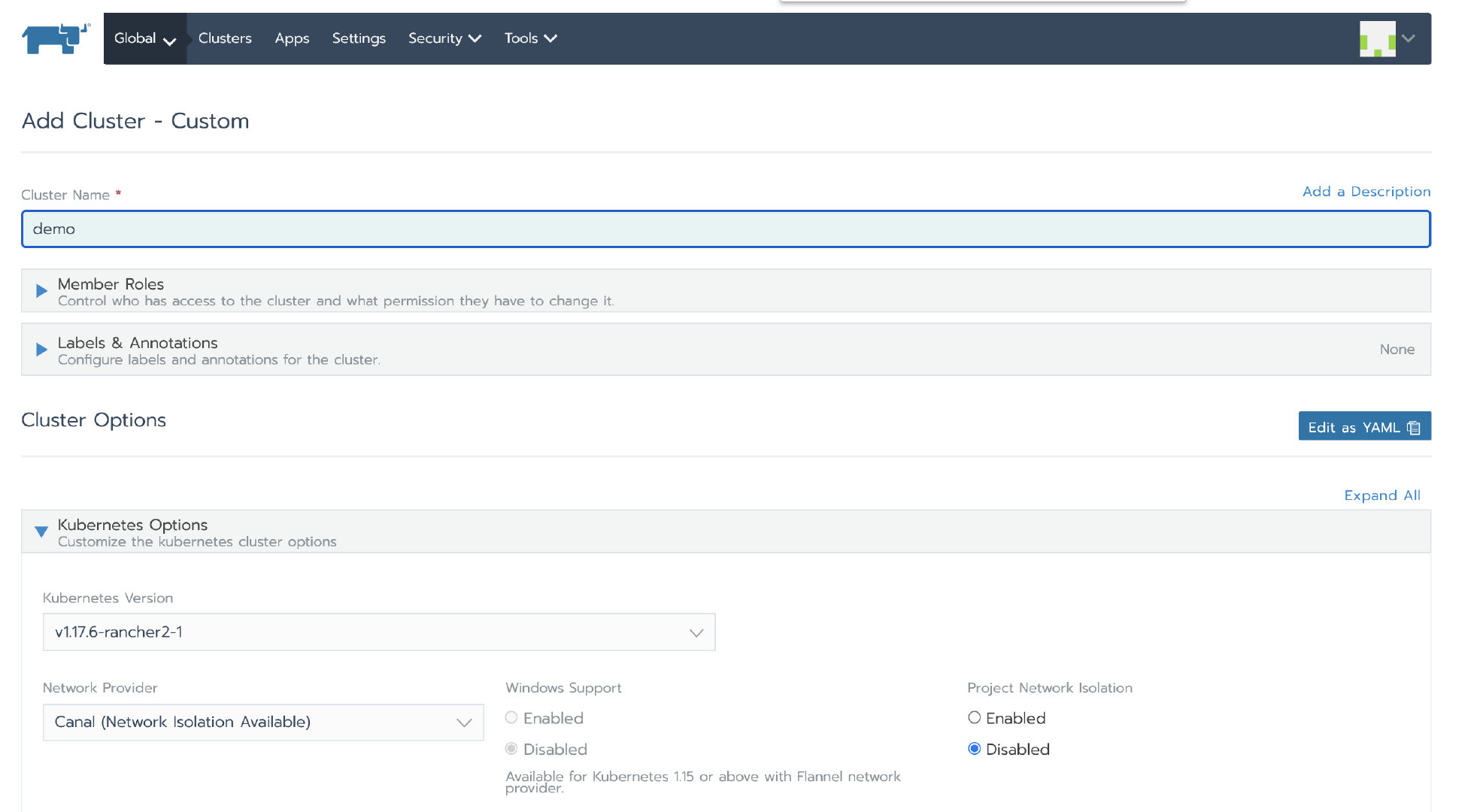
授权集群访问地址设置为启用,FQDN 和证书可以不用填写。
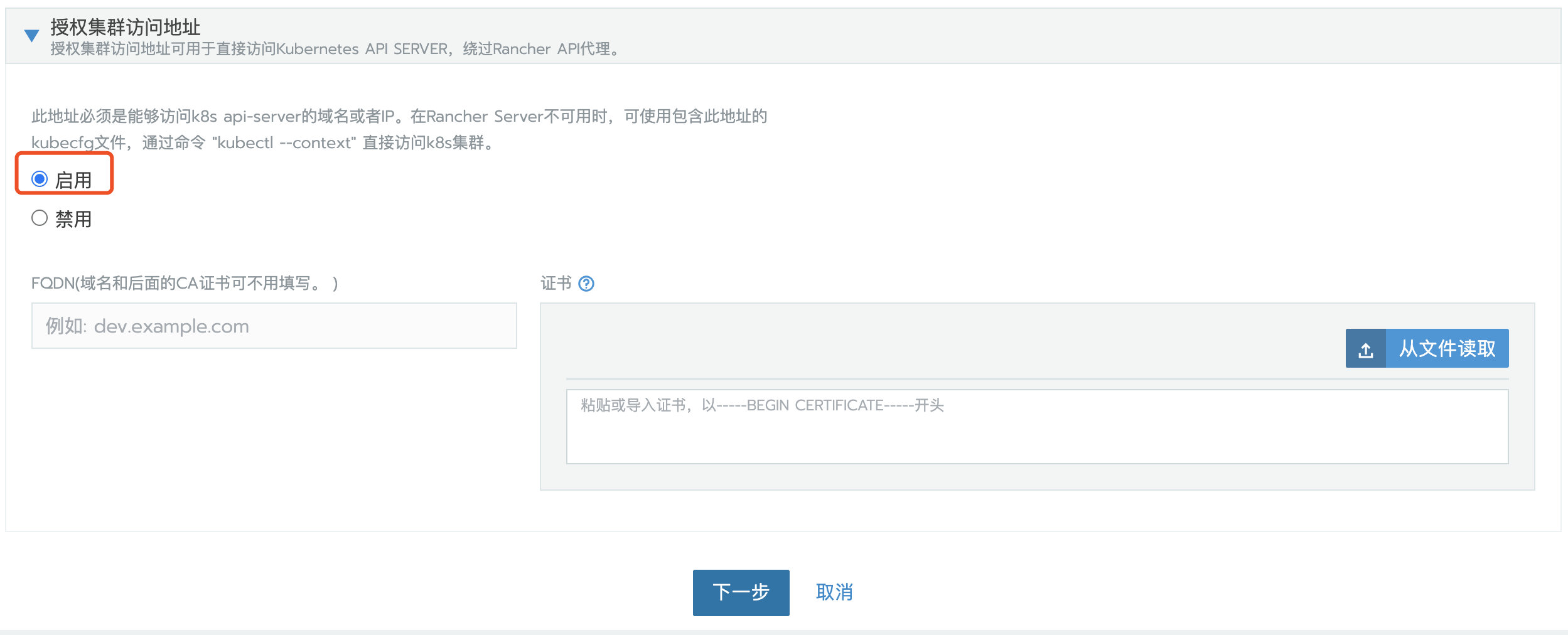
注意: 这一步很关键。因为Rancher 迁移后,地址或者 token 或者证书的变更,将会导致 agent 无法连接 Rancher Server。迁移后,需要通过 kubectl 去编辑配置文件更新一些 agent 相关的参数。默认 UI 上的 kubeconfig文件是通过 agent 代理连接到 Kubernetes,如果 agent 无法连接 Rancher Server,则通过这个 kubeconfig 文件也无法访问 Kubernetes 集群。开启授权集群访问地址功能会生成多个 Contexts Cluster,这些 Contexts Cluster 是直连 Kubernetes,不通过 agent 代理。如果业务集群未开启这个功能,可以通过编辑集群来开启这个功能。
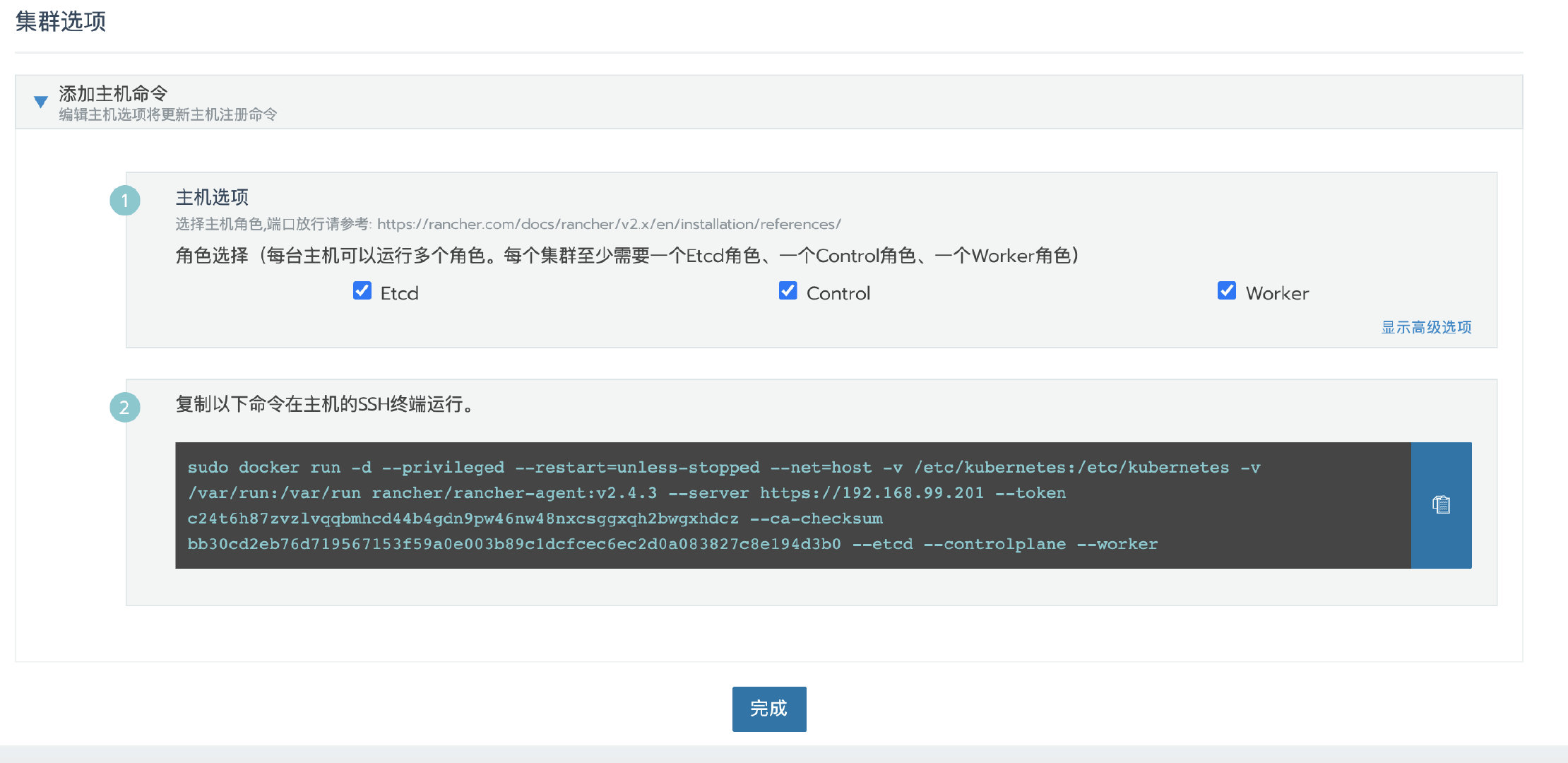
点击 下一步 ,根据预先分配的节点角色选择需要的角色,然后复制命令到主机终端执行。
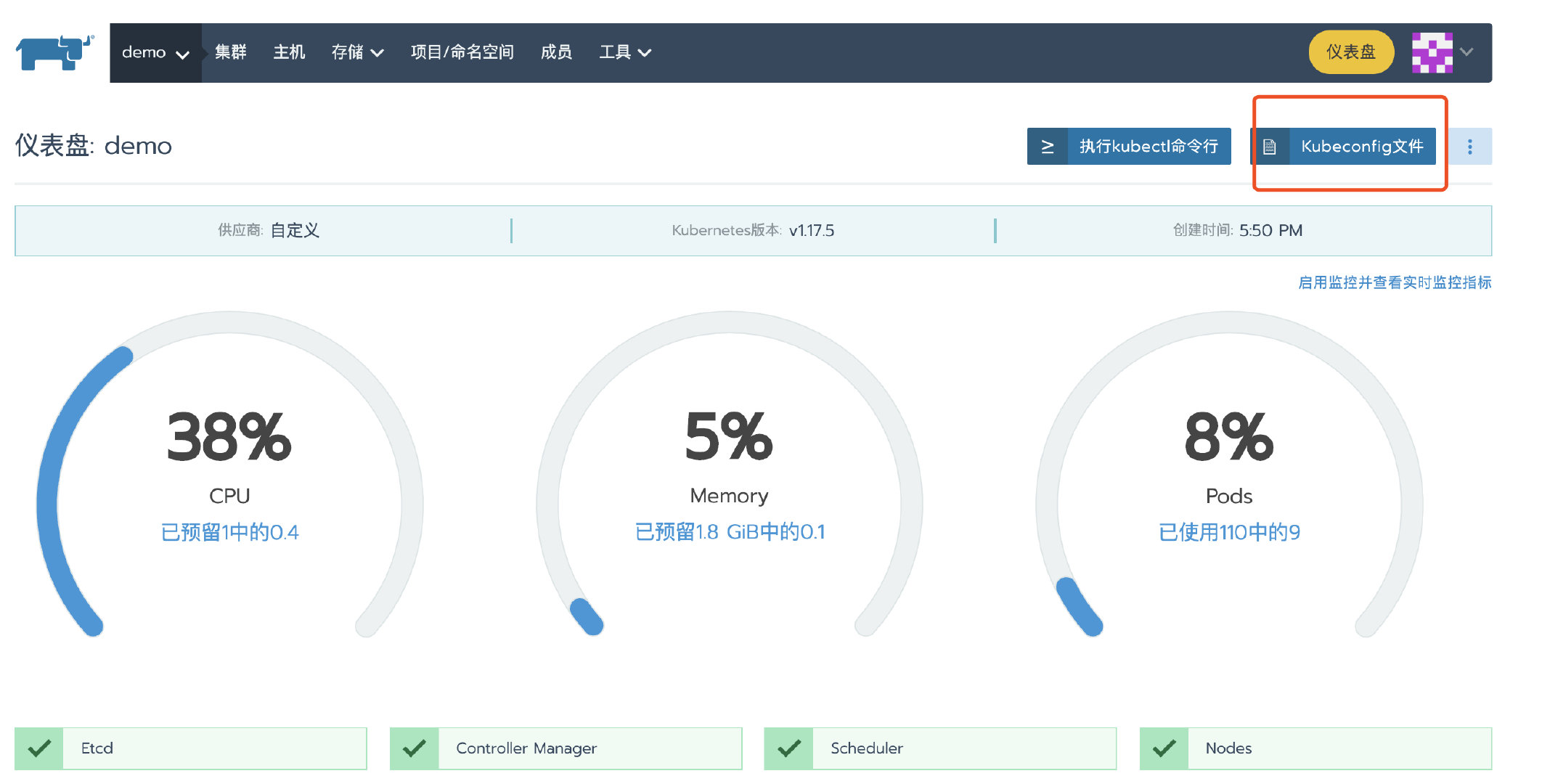
集群部署完成后,进入集群首页,点击kubeconfig文件按钮。在弹窗页面中复制 kubeconfg 配置文件备用。
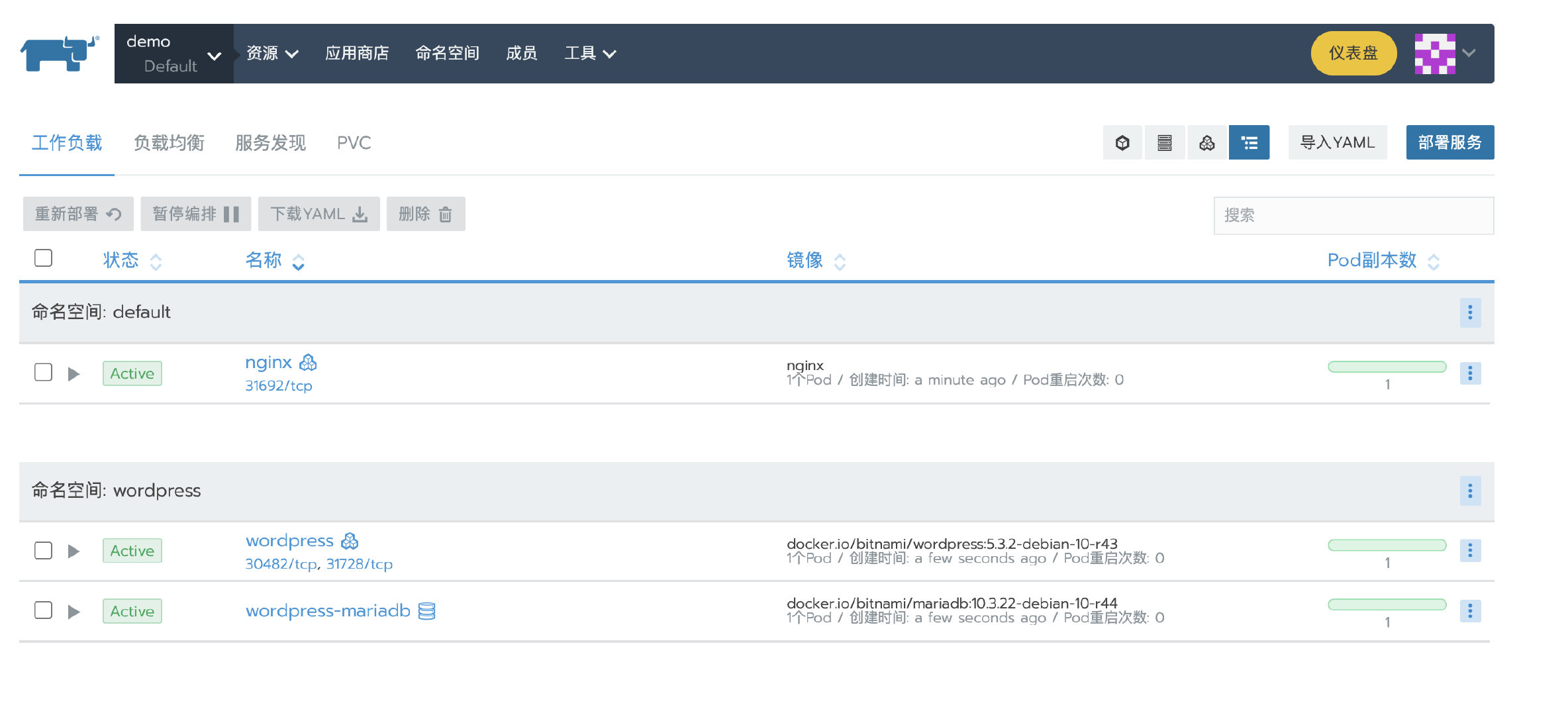
3. 部署测试应用
部署一个nginx workload。再从应用商店部署一个测试应用。
4. 创建将单节点etcd快照
docker exec -it <RANCHER_CONTAINER_NAME> bash
root@78efdcbe08a6:/# cd /
root@78efdcbe08a6:/# ETCDCTL_API=3 etcdctl snapshot save single-node-etcd-snapshot
root@78efdcbe08a6:/# exit
docker cp <RANCHER_CONTAINER_NAME>:/single-node-etcd-snapshot .
5. 关闭单节点Rancher Server
docker stop <RANCHER_CONTAINER_NAME>
在RKE Local集群上
1. RKE部署Local Kubernetes 集群
根据RKE示例配置 创建 RKE 配置文件 cluster.yml:
nodes:
- address: 99.79.49.94
internal_address: 172.31.13.209
user: ubuntu
role: [controlplane, worker, etcd]
- address: 35.183.174.120
internal_address: 172.31.8.28
user: ubuntu
role: [controlplane, worker, etcd]
- address: 15.223.49.238
internal_address: 172.31.0.199
user: ubuntu
role: [controlplane, worker, etcd]
执行 rke 命令创建 Local Kubernetes 集群
rke up --config cluster.yml
检查 Kubernetes 集群运行状态
使用kubectl检查节点状态,确认节点状态为Ready
kubectl get nodes
NAME STATUS ROLES AGE VERSION
15.223.49.238 Ready controlplane,etcd,worker 93s v1.17.6
35.183.174.120 Ready controlplane,etcd,worker 92s v1.17.6
99.79.49.94 Ready controlplane,etcd,worker 93s v1.17.6
检查所有必需的 Pod 和容器是否状况良好,然后可以继续进行
kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
ingress-nginx default-http-backend-67cf578fc4-9vjq4 1/1 Running 0 67s
ingress-nginx nginx-ingress-controller-8g7kq 1/1 Running 0 67s
ingress-nginx nginx-ingress-controller-8jvsd 1/1 Running 0 67s
ingress-nginx nginx-ingress-controller-lrt57 1/1 Running 0 67s
kube-system canal-68j4r 2/2 Running 0 100s
kube-system canal-ff4qg 2/2 Running 0 100s
kube-system canal-wl9hd 2/2 Running 0 100s
kube-system coredns-7c5566588d-bhbmm 1/1 Running 0 64s
kube-system coredns-7c5566588d-rhjpv 1/1 Running 0 87s
kube-system coredns-autoscaler-65bfc8d47d-tq4gj 1/1 Running 0 86s
kube-system metrics-server-6b55c64f86-vg7qs 1/1 Running 0 79s
kube-system rke-coredns-addon-deploy-job-fr2bx 0/1 Completed 0 92s
kube-system rke-ingress-controller-deploy-job-vksrk 0/1 Completed 0 72s
kube-system rke-metrics-addon-deploy-job-d9hlv 0/1 Completed 0 82s
kube-system rke-network-plugin-deploy-job-kf8bn 0/1 Completed 0 103s
2. 将生成的单节点etcd快照从Rancher单节点实例传到RKE Local集群节点上
在RKE HA Local节点上创建一个/opt/rke/etcd-snapshots目录,并将single-node-etcd-snapshot文件复制到该目录:
mkdir -p /opt/rke/etcd-snapshots
scp root@<old_rancher_ip>:/root/single-node-etcd-snapshot /opt/rke/etcd-snapshots
3. 使用RKE将单节点etcd快照还原到新的HA节点
rke etcd snapshot-restore --name single-node-etcd-snapshot --config cluster.yml
4. Rancher HA 安装
参考安装文档安装 Rancher HA。
5. 为Rancher HA配置NGINX 负载均衡
参考NGINX 配置示例为Rancher HA配置负载均衡。
Nginx 配置:
worker_processes 4;
worker_rlimit_nofile 40000;
events {
worker_connections 8192;
}
stream {
upstream rancher_servers_http {
least_conn;
server 172.31.11.95:80 max_fails=3 fail_timeout=5s;
server 172.31.0.201:80 max_fails=3 fail_timeout=5s;
server 172.31.15.236:80 max_fails=3 fail_timeout=5s;
}
server {
listen 80;
proxy_pass rancher_servers_http;
}
upstream rancher_servers_https {
least_conn;
server 172.31.11.95:443 max_fails=3 fail_timeout=5s;
server 172.31.0.201:443 max_fails=3 fail_timeout=5s;
server 172.31.15.236:443 max_fails=3 fail_timeout=5s;
}
server {
listen 443;
proxy_pass rancher_servers_https;
}
}
Nginx启动后,我们就可以通过配置的域名/IP去访问Rancher UI。可以看到业务集群demo为Unavailable状态,local集群虽然为Active,但cluster-agent和node-agent均启动失败。
这两种情况都是因为agent依然连接的旧的Rancher Server。
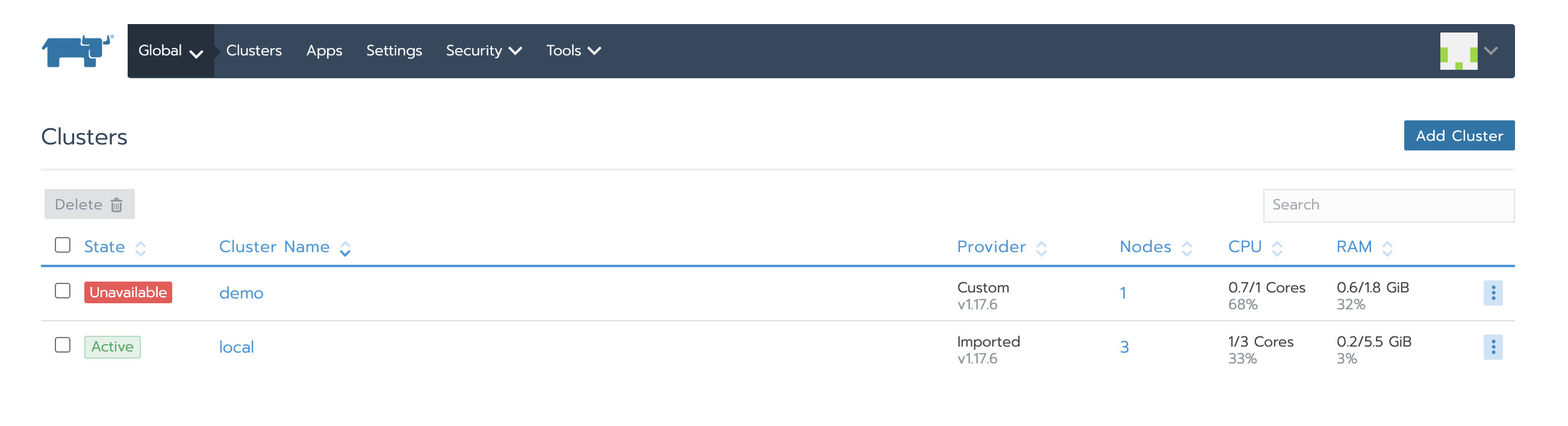
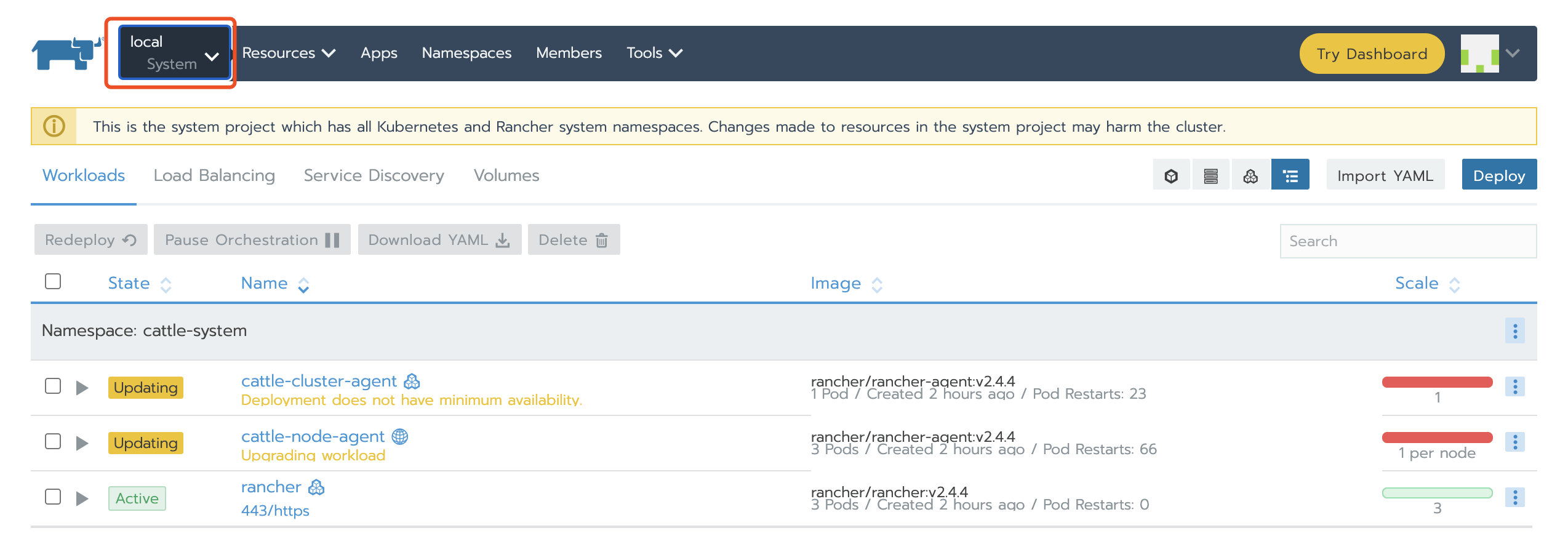
6. 更新Rancher Server IP或域名
-
依次访问全局 > 系统设置,页面往下翻找到server-url文件
-
单击右侧的省略号菜单,选择升级
-
修改server-url地址为新Rancher server的地址
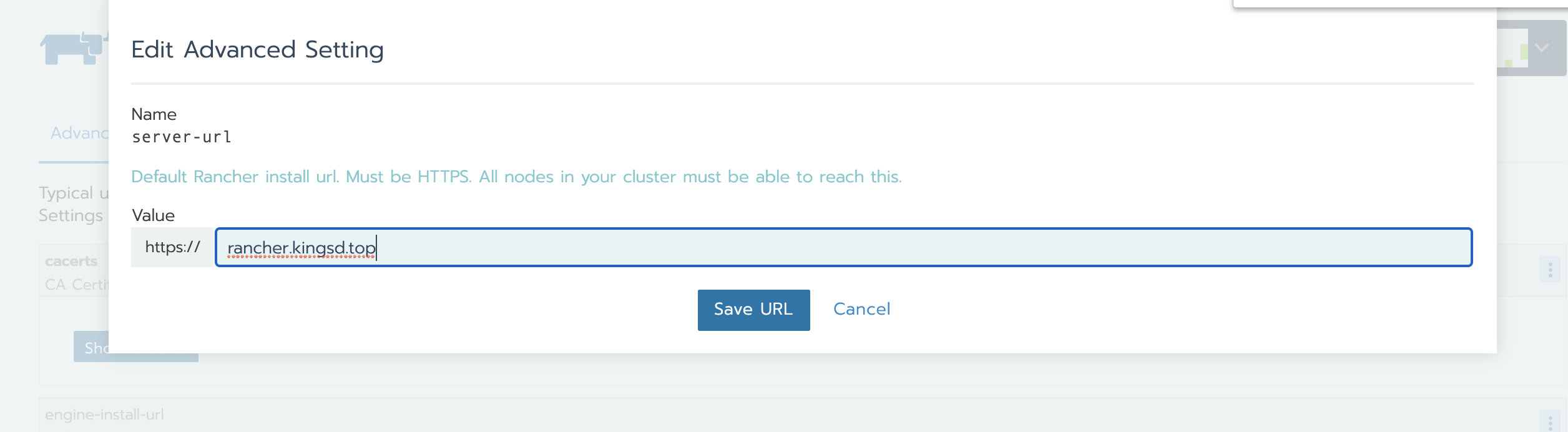
- 保存
7. 更新local集群和业务集群的agent配置
通过新域名或IP登录 Rancher Server;
通过浏览器地址栏查询集群ID, c/后面以c开头的字段即为集群 ID,本例的集群ID为c-hftcn;
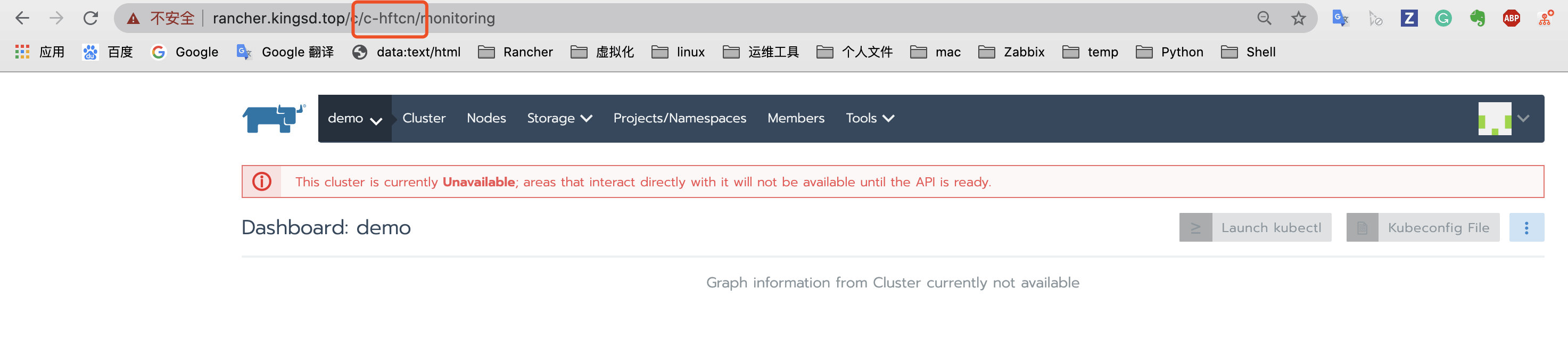
访问https://<新的server_url>/v3/clusters/<集群ID>/clusterregistrationtokens页面;
打开clusterRegistrationTokens页面后,定位到data字段;找到insecureCommand字段,复制 YAML 连接备用;
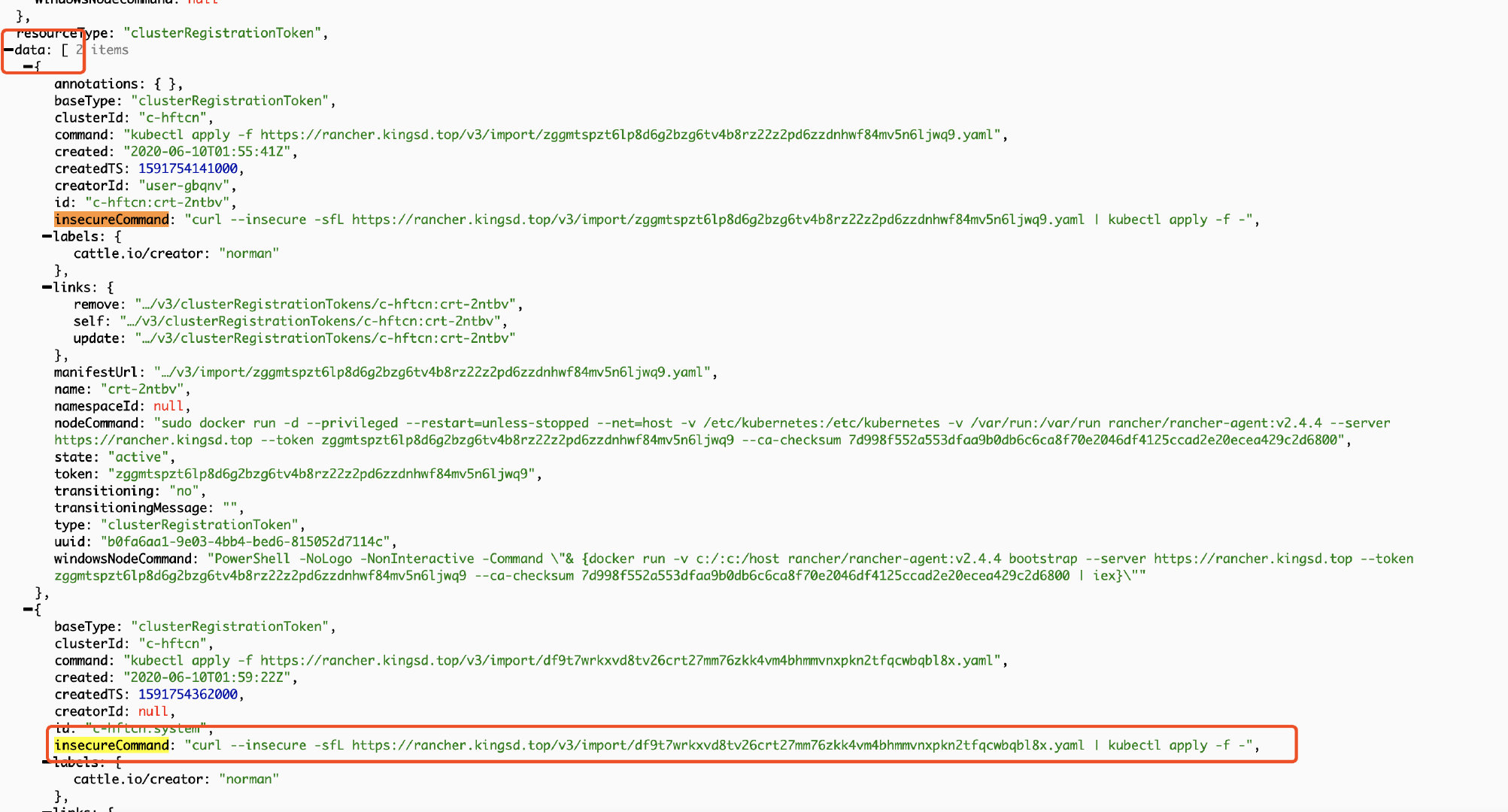
可能会有多组
"baseType": "clusterRegistrationToken",如上图。这种情况以createdTS最大、时间最新的一组为准,一般是最后一组。
使用kubectl工具,通过前文中准备的直连kubeconfig配置文件和上面步骤中获取的 YAML 文件,执行以下命令更新agent相关配置。
注意:
更新local集群和业务集群使用的kubeconfig是不同的,请针对不通集群选择需要的kubeconfig。
关于
--context=xxx说明请参考直接使用下游集群进行身份验证。
curl --insecure -sfL <替换为上面步骤获取的YAML文件链接> | kubectl --context=xxx apply -f -
业务集群agent更新成功后,使用相同的方法更新local集群agent配置。
9. 验证
过一会,local和demo集群都变为Active状态:
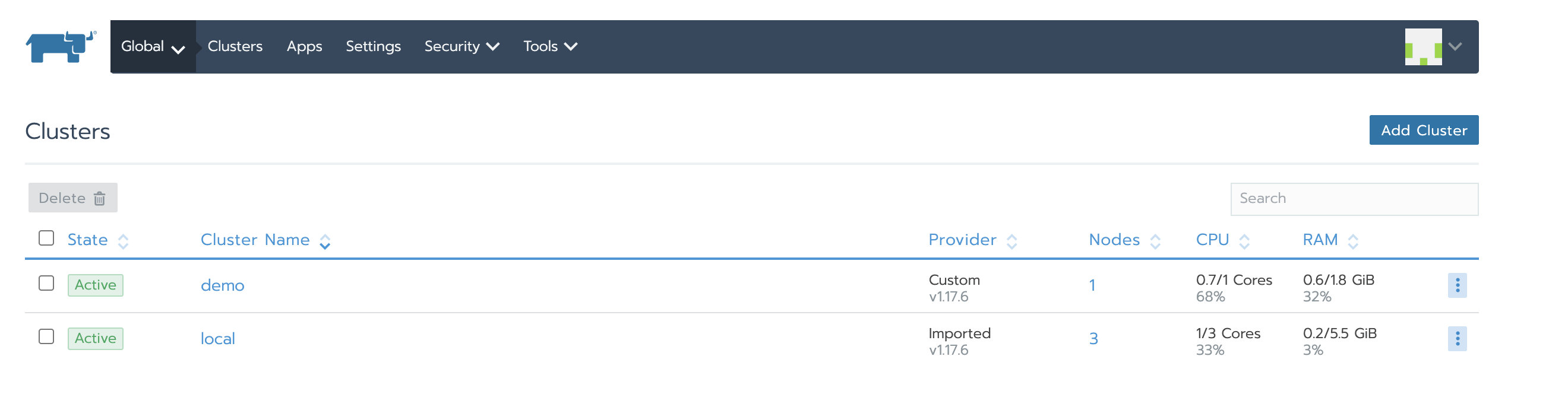
Local集群的cluster-agent和node-agent启动成功
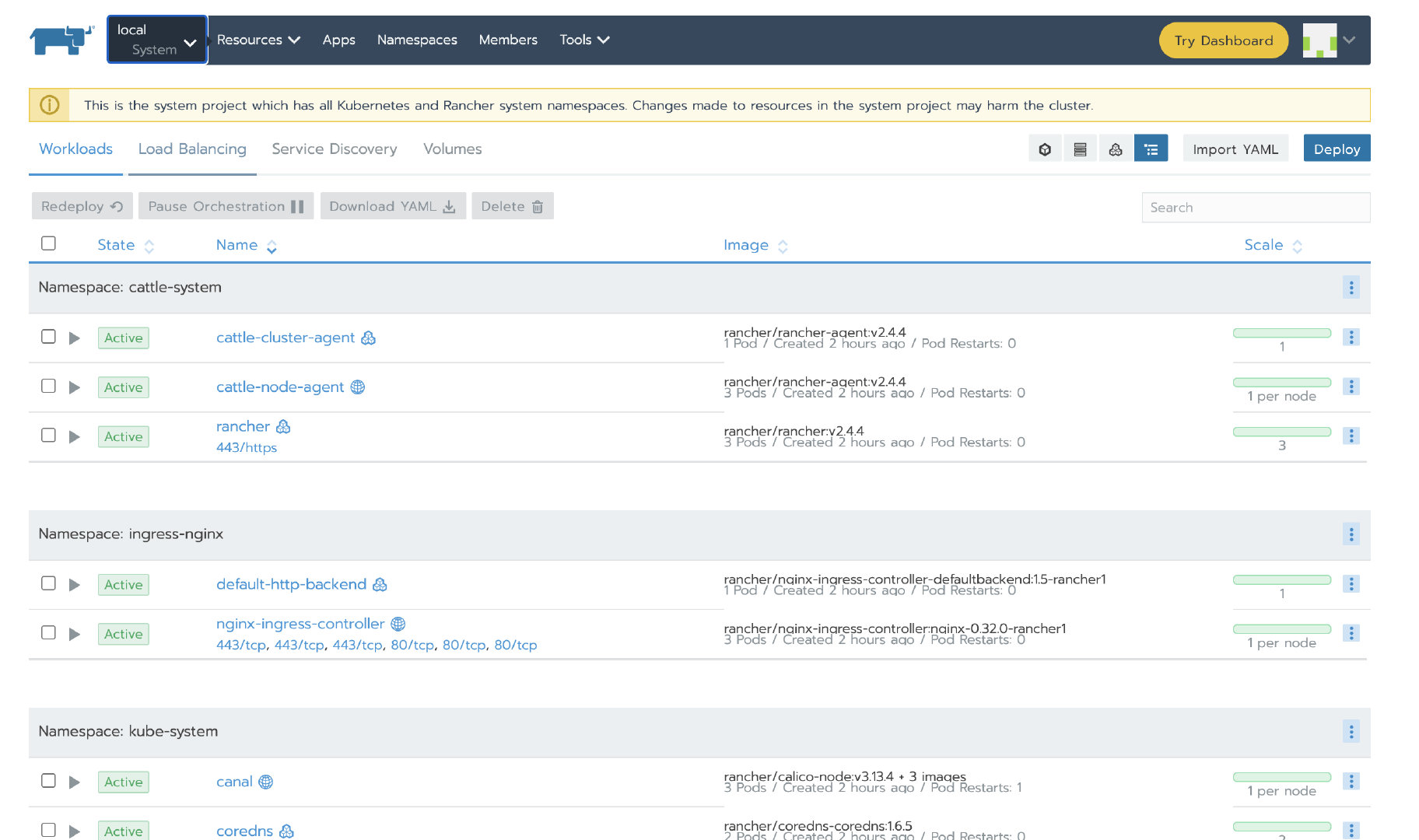
Demo集群的cluster-agent和node-agent启动成功
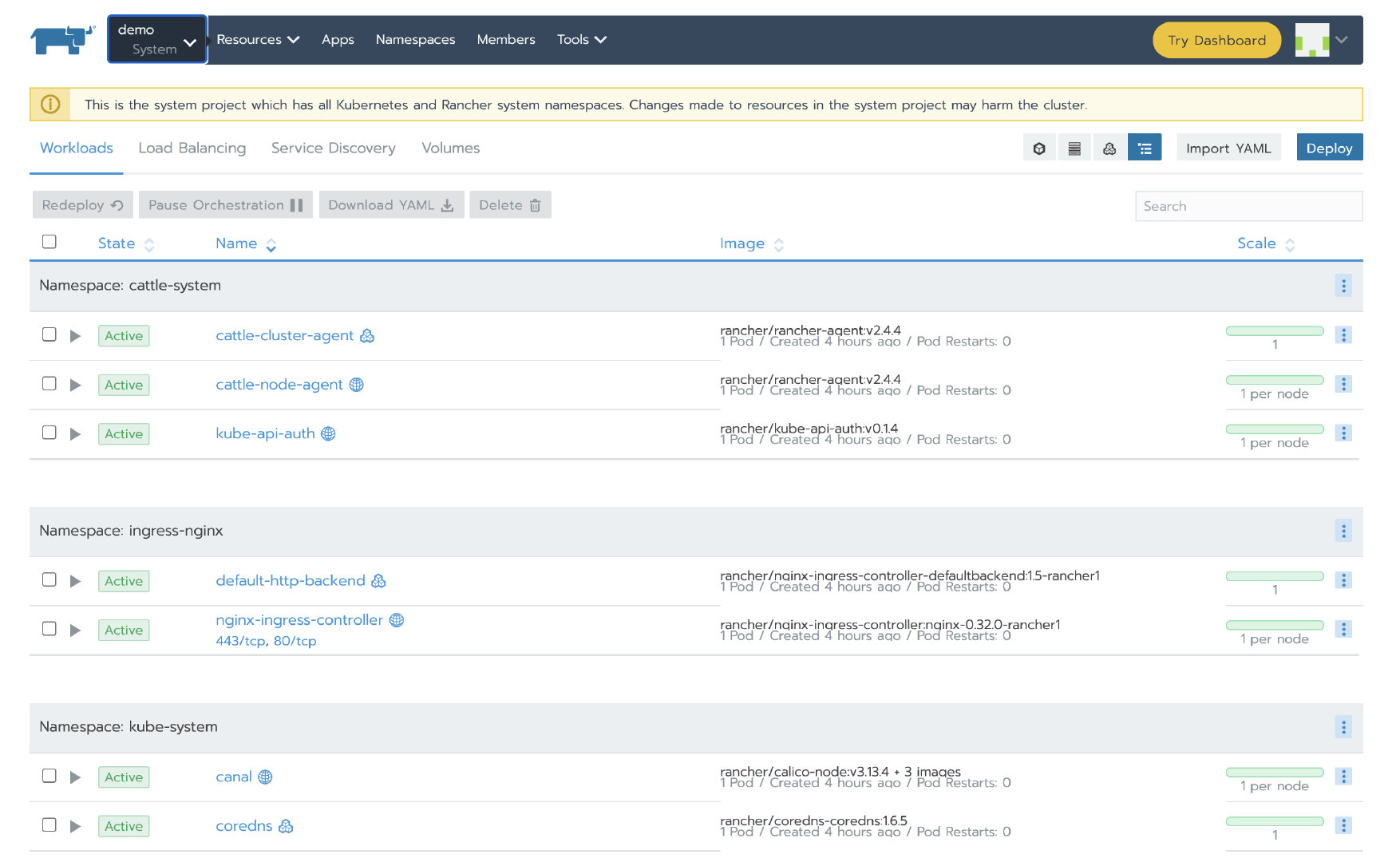
然后验证我们之前部署的应用是否可用。
场景3:Rancehr高可用安装迁移至其他Local集群
Rancehr高可用安装迁移至其他Local集群,可以借助rke的更新功能完成。通过rke将原来的3节点local集群扩展成6个节点,此时etcd数据将自动同步到local集群内的6个节点上,然后再使用rke将原有的3台节点移除,再次更新。这样就将Rancher Server可以平滑的迁移到新的Rancher local集群。
1. RKE部署Local Kubernetes 集群
根据RKE示例配置创建 RKE 配置文件 cluster.yml:
nodes:
- address: 3.96.52.186
internal_address: 172.31.11.95
user: ubuntu
role: [controlplane, worker, etcd]
- address: 35.183.186.213
internal_address: 172.31.0.201
user: ubuntu
role: [controlplane, worker, etcd]
- address: 35.183.130.12
internal_address: 172.31.15.236
user: ubuntu
role: [controlplane, worker, etcd]
执行 rke 命令创建 Local Kubernetes 集群
rke up --config cluster.yml
检查 Kubernetes 集群运行状态
使用kubectl检查节点状态,确认节点状态为Ready
kubectl get nodes
NAME STATUS ROLES AGE VERSION
3.96.52.186 Ready controlplane,etcd,worker 71s v1.17.6
35.183.130.12 Ready controlplane,etcd,worker 72s v1.17.6
35.183.186.213 Ready controlplane,etcd,worker 72s v1.17.6
检查所有必需的 Pod 和容器是否状况良好,然后可以继续进行
kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
ingress-nginx default-http-backend-67cf578fc4-gnt5c 1/1 Running 0 72s
ingress-nginx nginx-ingress-controller-47p4b 1/1 Running 0 72s
ingress-nginx nginx-ingress-controller-85284 1/1 Running 0 72s
ingress-nginx nginx-ingress-controller-9qbdz 1/1 Running 0 72s
kube-system canal-9bx8k 2/2 Running 0 97s
kube-system canal-l2fjb 2/2 Running 0 97s
kube-system canal-v7fzs 2/2 Running 0 97s
kube-system coredns-7c5566588d-7kv7b 1/1 Running 0 67s
kube-system coredns-7c5566588d-t4jfm 1/1 Running 0 90s
kube-system coredns-autoscaler-65bfc8d47d-vnrzc 1/1 Running 0 90s
kube-system metrics-server-6b55c64f86-r4p8w 1/1 Running 0 79s
kube-system rke-coredns-addon-deploy-job-lx667 0/1 Completed 0 94s
kube-system rke-ingress-controller-deploy-job-r2nw5 0/1 Completed 0 74s
kube-system rke-metrics-addon-deploy-job-4bq76 0/1 Completed 0 84s
kube-system rke-network-plugin-deploy-job-gjpm8 0/1 Completed 0 99s
2. Rancher HA 安装
参考安装文档安装 Rancher HA。
3. 为Rancher HA配置NGINX 负载均衡
参考NGINX 配置示例为Rancher HA配置负载均衡。
Nginx 配置:
worker_processes 4;
worker_rlimit_nofile 40000;
events {
worker_connections 8192;
}
stream {
upstream rancher_servers_http {
least_conn;
server 172.31.11.95:80 max_fails=3 fail_timeout=5s;
server 172.31.0.201:80 max_fails=3 fail_timeout=5s;
server 172.31.15.236:80 max_fails=3 fail_timeout=5s;
}
server {
listen 80;
proxy_pass rancher_servers_http;
}
upstream rancher_servers_https {
least_conn;
server 172.31.11.95:443 max_fails=3 fail_timeout=5s;
server 172.31.0.201:443 max_fails=3 fail_timeout=5s;
server 172.31.15.236:443 max_fails=3 fail_timeout=5s;
}
server {
listen 443;
proxy_pass rancher_servers_https;
}
}
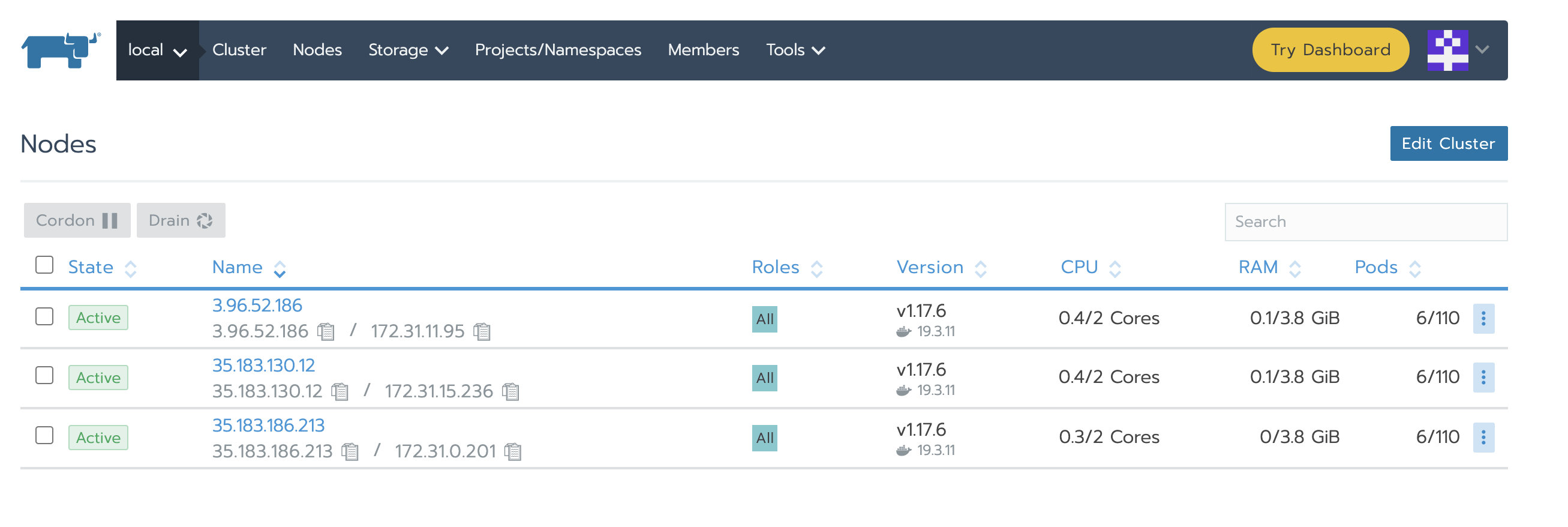
Nginx启动后,我们就可以通过配置的域名/IP去访问Rancher UI。可以导航到local->Nodes 查看到local集群三个节点的状态:
4. 部署测试集群及应用
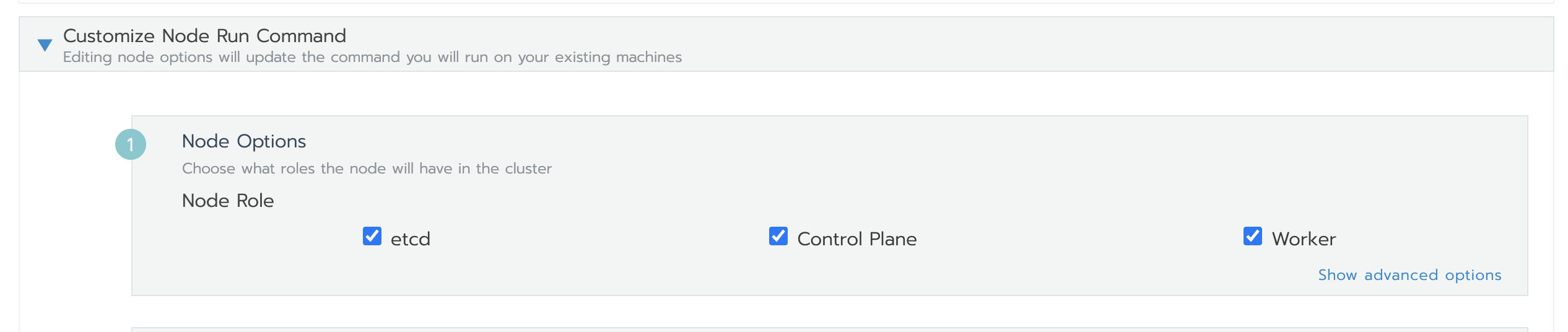
添加测试集群,Node Role同时选中etcd、Control Plane、Worker
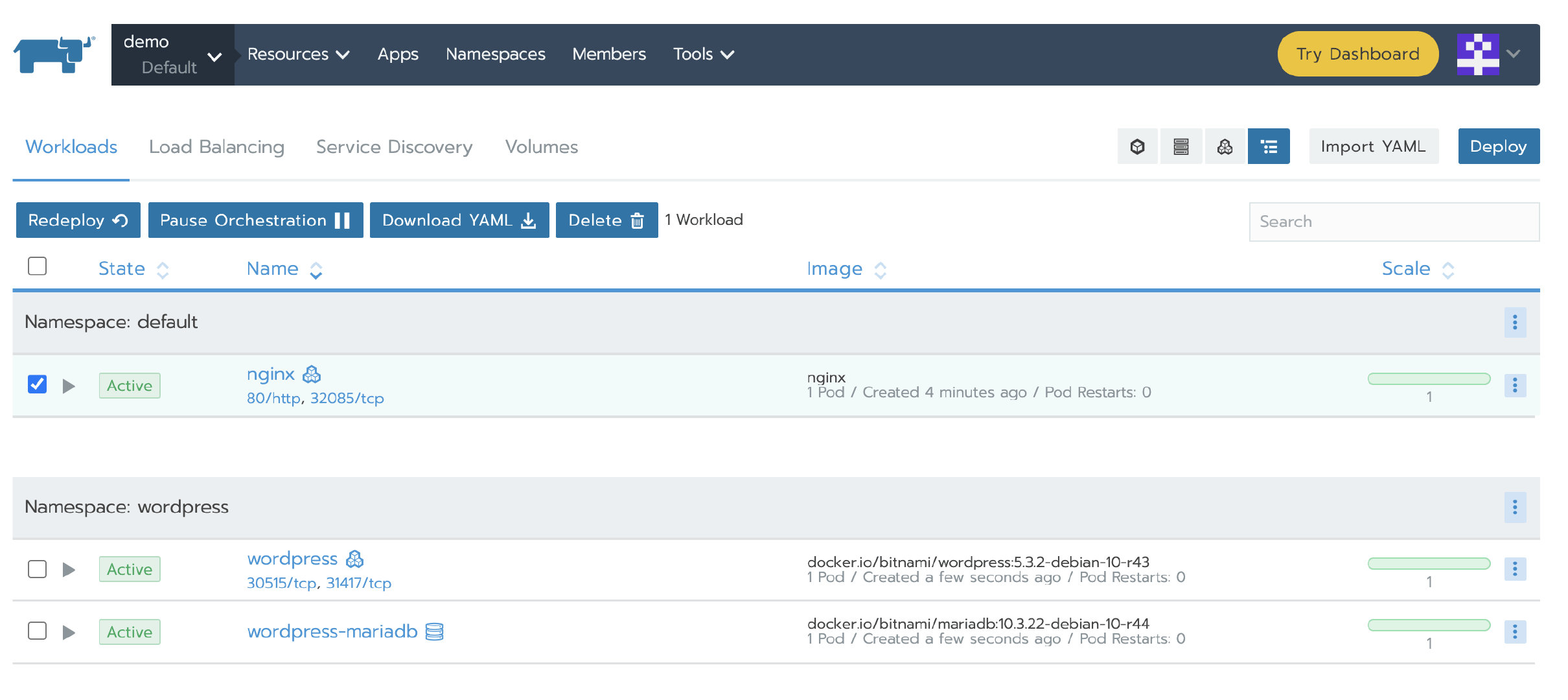
等待测试集群添加成功后,部署一个nginx workload。再从应用商店部署一个测试应用。
5. 将新集群的节点添加到Local集群
修改刚才创建local集群所使用的rke配置文件,增加新集群的配置。
cluster.yml:
nodes:
- address: 3.96.52.186
internal_address: 172.31.11.95
user: ubuntu
role: [controlplane, worker, etcd]
- address: 35.183.186.213
internal_address: 172.31.0.201
user: ubuntu
role: [controlplane, worker, etcd]
- address: 35.183.130.12
internal_address: 172.31.15.236
user: ubuntu
role: [controlplane, worker, etcd]
# 以下内容为新增节点的配置
- address: 52.60.116.56
internal_address: 172.31.14.146
user: ubuntu
role: [controlplane, worker, etcd]
- address: 99.79.9.244
internal_address: 172.31.15.215
user: ubuntu
role: [controlplane, worker, etcd]
- address: 15.223.77.84
internal_address: 172.31.8.64
user: ubuntu
role: [controlplane, worker, etcd]
更新集群,将local集群节点扩展到6个
rke up --cluster.yml
检查 Kubernetes 集群运行状态
使用kubectl测试您的连通性,并确认原节点(3.96.52.186、35.183.186.213、35.183.130.12)和新增节点(52.60.116.56、99.79.9.244、15.223.77.84)都处于Ready状态
kubectl get nodes
NAME STATUS ROLES AGE VERSION
15.223.77.84 Ready controlplane,etcd,worker 33s v1.17.6
3.96.52.186 Ready controlplane,etcd,worker 88m v1.17.6
35.183.130.12 Ready controlplane,etcd,worker 89m v1.17.6
35.183.186.213 Ready controlplane,etcd,worker 89m v1.17.6
52.60.116.56 Ready controlplane,etcd,worker 101s v1.17.6
99.79.9.244 Ready controlplane,etcd,worker 67s v1.17.6
检查所有必需的 Pod 和容器是否状况良好,然后可以继续进行
kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
cattle-system cattle-cluster-agent-68898b5c4d-lkz5m 1/1 Running 0 46m
cattle-system cattle-node-agent-9xrbs 1/1 Running 0 109s
cattle-system cattle-node-agent-lvdlf 1/1 Running 0 46m
cattle-system cattle-node-agent-mnk76 1/1 Running 0 46m
cattle-system cattle-node-agent-qfwcm 1/1 Running 0 75s
cattle-system cattle-node-agent-tk66h 1/1 Running 0 2m23s
cattle-system cattle-node-agent-v2vpf 1/1 Running 0 46m
cattle-system rancher-749fd64664-8cg4w 1/1 Running 1 58m
cattle-system rancher-749fd64664-fms8x 1/1 Running 1 58m
cattle-system rancher-749fd64664-rb5pt 1/1 Running 1 58m
ingress-nginx default-http-backend-67cf578fc4-gnt5c 1/1 Running 0 89m
ingress-nginx nginx-ingress-controller-44c5z 1/1 Running 0 61s
ingress-nginx nginx-ingress-controller-47p4b 1/1 Running 0 89m
ingress-nginx nginx-ingress-controller-85284 1/1 Running 0 89m
ingress-nginx nginx-ingress-controller-9qbdz 1/1 Running 0 89m
ingress-nginx nginx-ingress-controller-kp7p6 1/1 Running 0 61s
ingress-nginx nginx-ingress-controller-tfjrw 1/1 Running 0 61s
kube-system canal-9bx8k 2/2 Running 0 89m
kube-system canal-fqrqv 2/2 Running 0 109s
kube-system canal-kkj7q 2/2 Running 0 75s
kube-system canal-l2fjb 2/2 Running 0 89m
kube-system canal-v7fzs 2/2 Running 0 89m
kube-system canal-w7t58 2/2 Running 0 2m23s
kube-system coredns-7c5566588d-7kv7b 1/1 Running 0 89m
kube-system coredns-7c5566588d-t4jfm 1/1 Running 0 89m
kube-system coredns-autoscaler-65bfc8d47d-vnrzc 1/1 Running 0 89m
kube-system metrics-server-6b55c64f86-r4p8w 1/1 Running 0 89m
kube-system rke-coredns-addon-deploy-job-lx667 0/1 Completed 0 89m
kube-system rke-ingress-controller-deploy-job-r2nw5 0/1 Completed 0 89m
kube-system rke-metrics-addon-deploy-job-4bq76 0/1 Completed 0 89m
kube-system rke-network-plugin-deploy-job-gjpm8 0/1 Completed 0 89m
从上面的信息可以确认现在local集群已经扩展到6个,并且所有workload均正常运行。
6. 再次更新集群,剔除掉原Local集群节点
再次修改local集群所使用的rke配置文件,将原local集群节点配置注释掉。
cluster.yml:
nodes:
# - address: 3.96.52.186
# internal_address: 172.31.11.95
# user: ubuntu
# role: [controlplane, worker, etcd]
# - address: 35.183.186.213
# internal_address: 172.31.0.201
# user: ubuntu
# role: [controlplane, worker, etcd]
# - address: 35.183.130.12
# internal_address: 172.31.15.236
# user: ubuntu
# role: [controlplane, worker, etcd]
# 以下内容为新增节点
- address: 52.60.116.56
internal_address: 172.31.14.146
user: ubuntu
role: [controlplane, worker, etcd]
- address: 99.79.9.244
internal_address: 172.31.15.215
user: ubuntu
role: [controlplane, worker, etcd]
- address: 15.223.77.84
internal_address: 172.31.8.64
user: ubuntu
role: [controlplane, worker, etcd]
更新集群,完成迁移。
rke up --cluster.yml
检查 Kubernetes 集群运行状态
使用kubectl检查节点状态为Ready,可以看到local集群的节点已经替换成了以下3个:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
15.223.77.84 Ready controlplane,etcd,worker 11m v1.17.6
52.60.116.56 Ready controlplane,etcd,worker 13m v1.17.6
99.79.9.244 Ready controlplane,etcd,worker 12m v1.17.6
检查所有必需的 Pod 和容器是否状况良好,然后可以继续进行
kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
cattle-system cattle-cluster-agent-68898b5c4d-tm6db 1/1 Running 3 3m14s
cattle-system cattle-node-agent-9xrbs 1/1 Running 0 14m
cattle-system cattle-node-agent-qfwcm 1/1 Running 0 14m
cattle-system cattle-node-agent-tk66h 1/1 Running 0 15m
cattle-system rancher-749fd64664-47jw2 1/1 Running 0 3m14s
cattle-system rancher-749fd64664-jpqdd 1/1 Running 0 3m14s
cattle-system rancher-749fd64664-xn6js 1/1 Running 0 3m14s
ingress-nginx default-http-backend-67cf578fc4-4668g 1/1 Running 0 3m14s
ingress-nginx nginx-ingress-controller-44c5z 1/1 Running 0 13m
ingress-nginx nginx-ingress-controller-kp7p6 1/1 Running 0 13m
ingress-nginx nginx-ingress-controller-tfjrw 1/1 Running 0 13m
kube-system canal-fqrqv 2/2 Running 0 14m
kube-system canal-kkj7q 2/2 Running 0 14m
kube-system canal-w7t58 2/2 Running 0 15m
kube-system coredns-7c5566588d-nmtrn 1/1 Running 0 3m13s
kube-system coredns-7c5566588d-q6hlb 1/1 Running 0 3m13s
kube-system coredns-autoscaler-65bfc8d47d-rx7fm 1/1 Running 0 3m14s
kube-system metrics-server-6b55c64f86-mcx9z 1/1 Running 0 3m14s
从上面的信息可以确认现在local集群已经迁移成功,并且所有workload均正常运行。
修改nginx负载均衡配置,将新节点的信息更新到nginx配置文件中
worker_processes 4;
worker_rlimit_nofile 40000;
events {
worker_connections 8192;
}
stream {
upstream rancher_servers_http {
least_conn;
server 172.31.14.146:80 max_fails=3 fail_timeout=5s;
server 172.31.8.64:80 max_fails=3 fail_timeout=5s;
server 172.31.15.215:80 max_fails=3 fail_timeout=5s;
}
server {
listen 80;
proxy_pass rancher_servers_http;
}
upstream rancher_servers_https {
least_conn;
server 172.31.14.146:443 max_fails=3 fail_timeout=5s;
server 172.31.8.64:443 max_fails=3 fail_timeout=5s;
server 172.31.15.215:443 max_fails=3 fail_timeout=5s;
}
server {
listen 443;
proxy_pass rancher_servers_https;
}
}
7. 验证
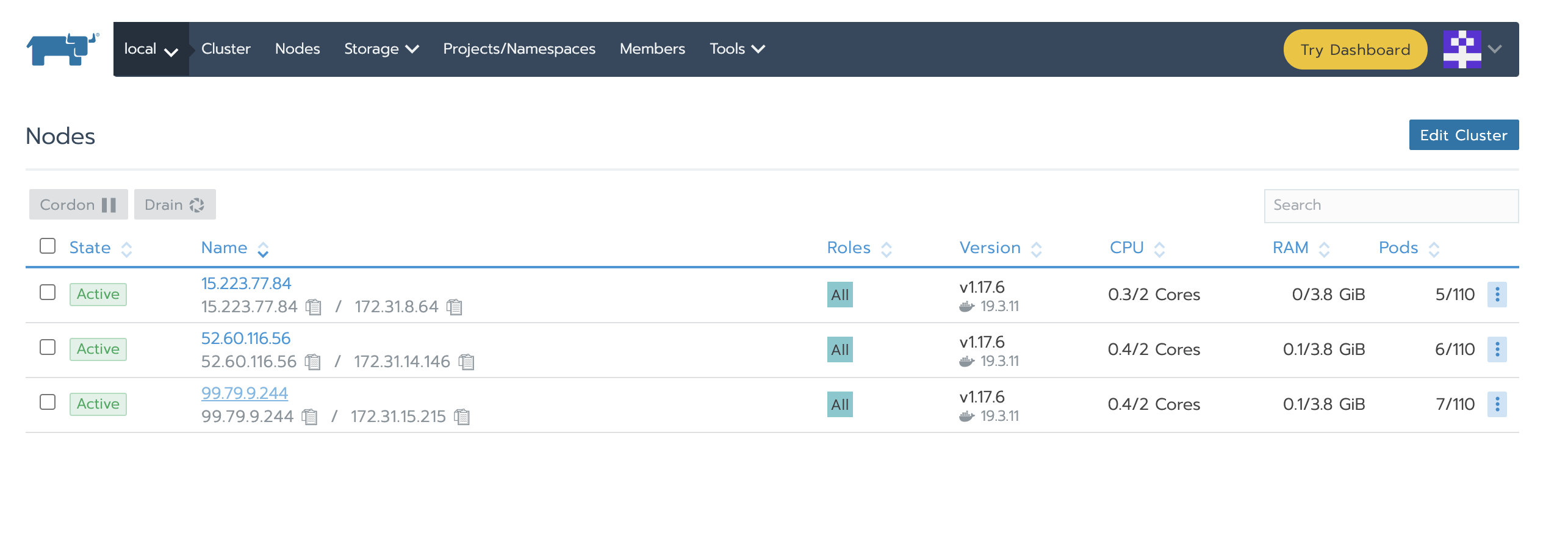
确认local集群和业务集群状态为Active
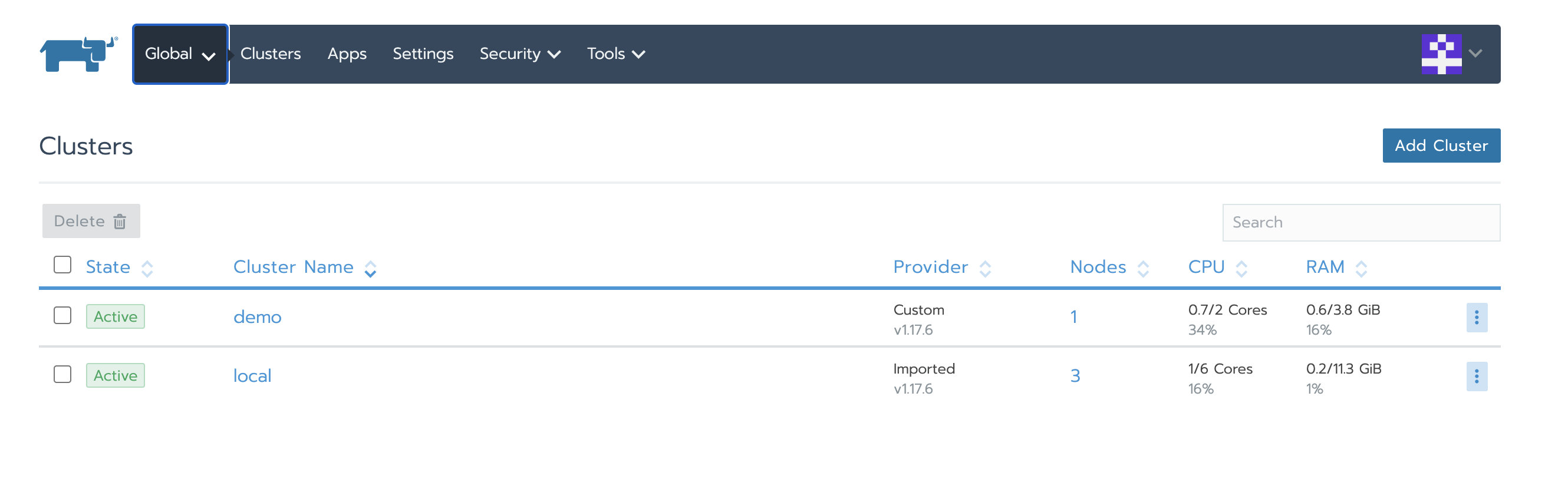
确认Local集群节点已被替换
原集群节点IP分别为:3.96.52.186、35.183.186.213、35.183.130.12
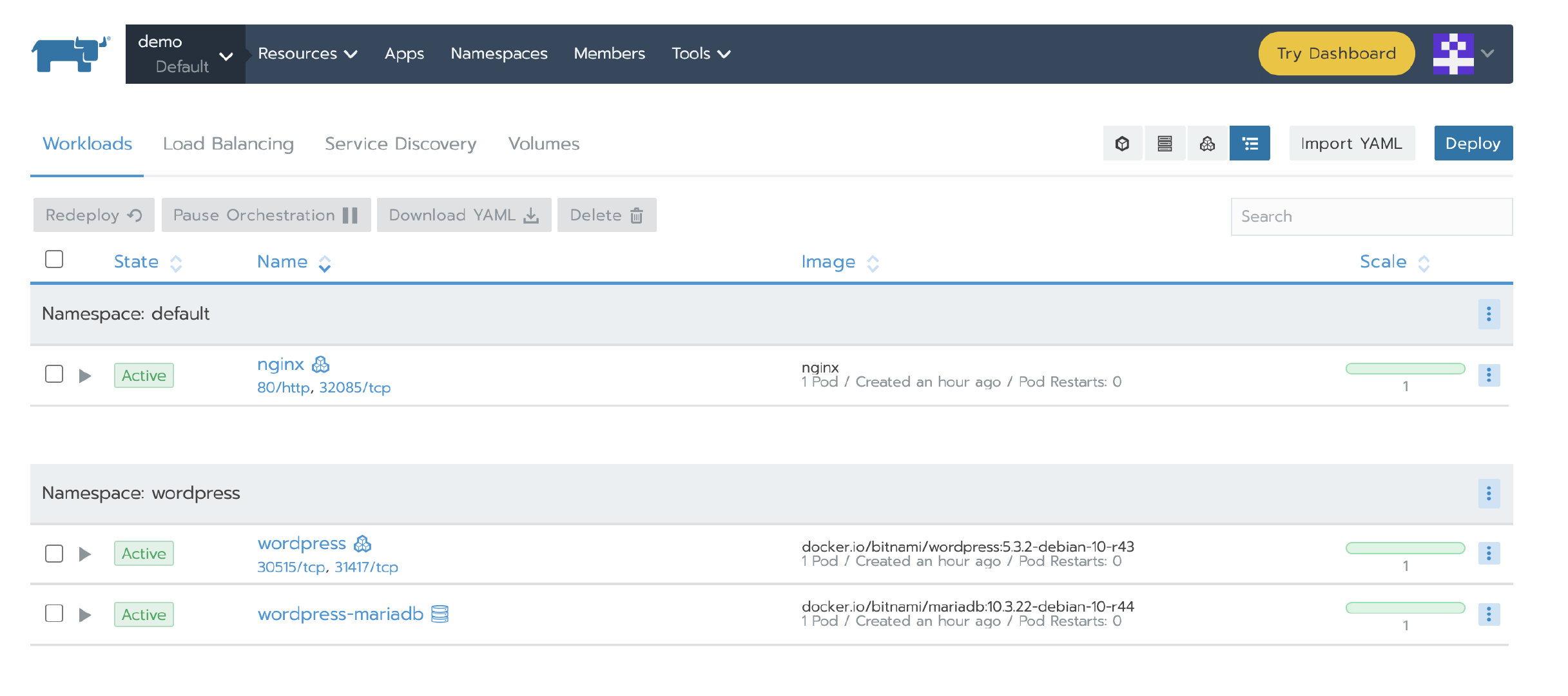
然后验证我们之前部署的应用是否可用。
总 结
开源一直是Rancher的产品理念,我们也一向重视与开源社区用户的交流,为此创建了20个微信交流群。本篇文章的诞生源于和社区用户的多次交流,发现许多Rancher用户都有类似的问题。于是,我总结了三个场景并经过反复测试,最终完成这篇教程。我们也十分欢迎各位Rancher用户以各种形式分享自己的使用经验,一起共建愉快的开源社区。