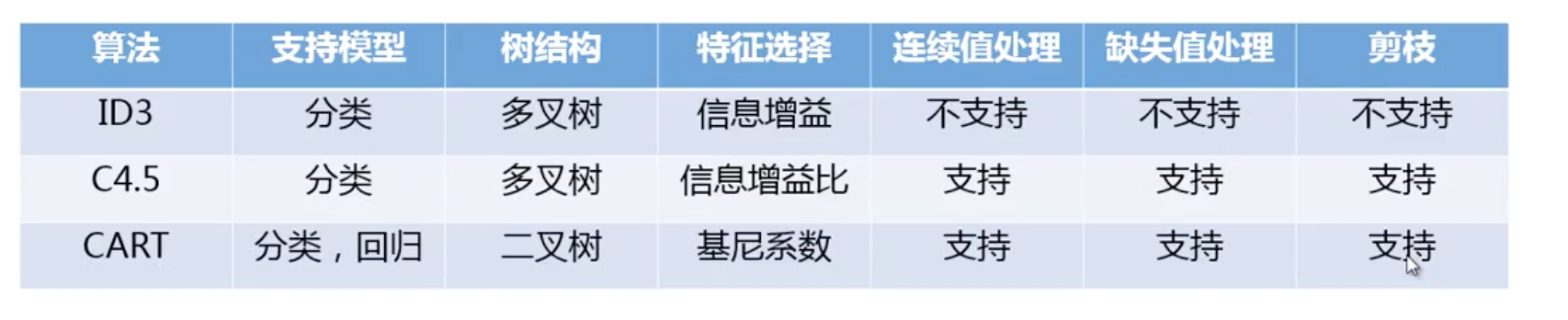
如何构建决策树
- 准备工作:
- 明确自变量和因变量
- 确定信息度量的方式
- 确定终止条件
- 选择特征
- 得到当前待处理子集
- 计算所有特征信息度量
- 得到当前最佳分类特征
- 创建分支
- 根据选中特征将当前记录分成不同分支,分支个数取决于算法
- 是否终止
- 判断是否满足终止条件
- 生成结果
- 判断是否需要剪枝
案例
根据部分电脑购买记录,对购买者建模。该模型可以基于客户的一些信息预测他是否会购买电脑。
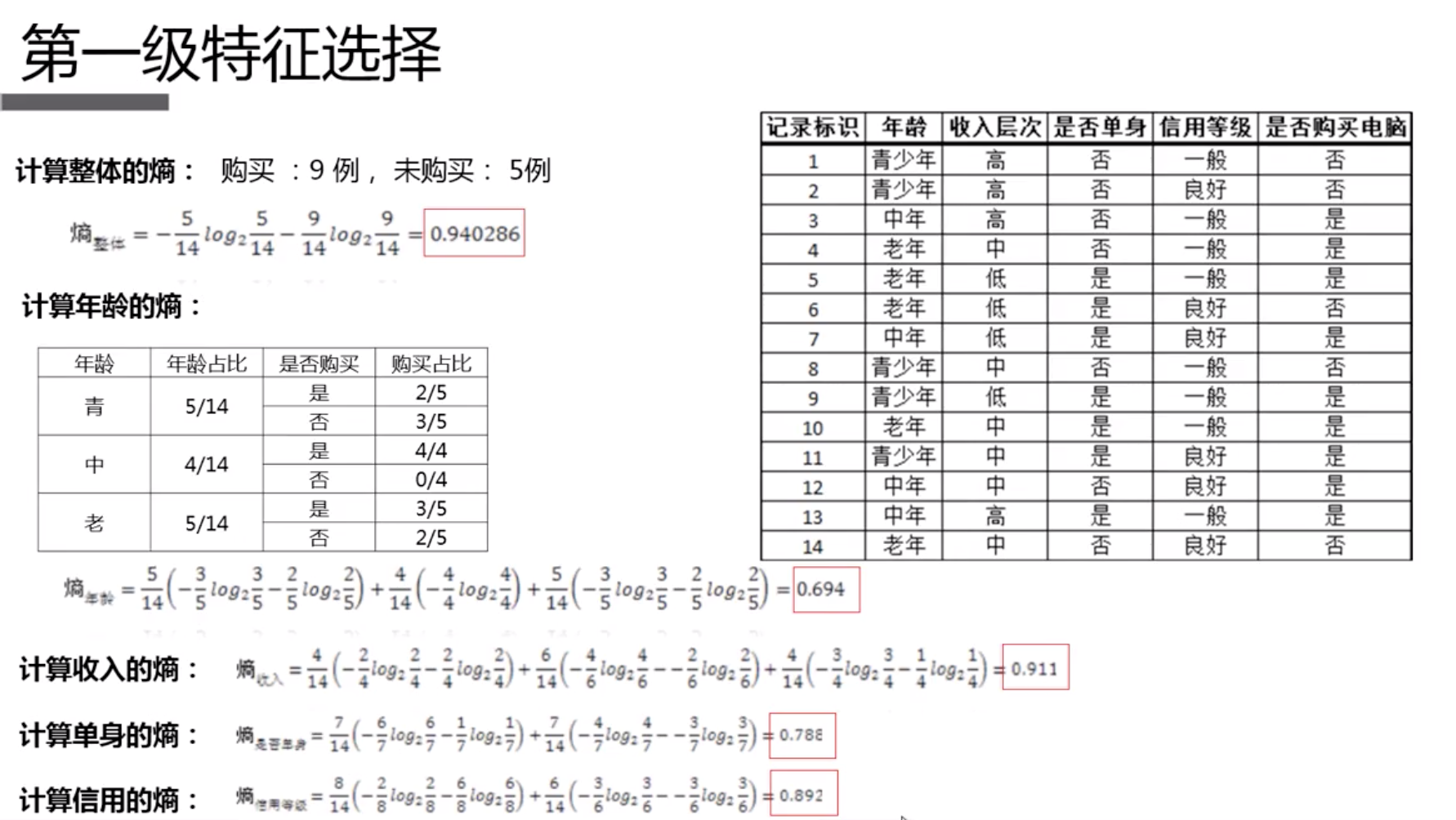
| 记录标识 | 人群群体 | 收入层次 | 是否单身 | 信用等级 | 是否购买电脑 |
|---|---|---|---|---|---|
| 1 | 青年 | 高 | 否 | 一般 | 否 |
| 2 | 青年 | 高 | 否 | 良好 | 否 |
| 3 | 中年 | 高 | 否 | 一般 | 是 |
| 4 | 老年 | 中 | 否 | 一般 | 是 |
| 5 | 老年 | 低 | 是 | 一般 | 是 |
| 6 | 老年 | 低 | 是 | 良好 | 否 |
| 7 | 中年 | 低 | 是 | 良好 | 是 |
| 8 | 青年 | 中 | 否 | 一般 | 否 |
| 9 | 青年 | 低 | 是 | 一般 | 是 |
| 10 | 老年 | 中 | 是 | 一般 | 是 |
| 11 | 青年 | 中 | 是 | 良好 | 是 |
| 12 | 中年 | 中 | 否 | 良好 | 是 |
| 13 | 中年 | 高 | 是 | 一般 | 是 |
| 14 | 老年 | 中 | 否 | 良好 | 否 |
准备工作
- 观察数据,明确自变量和因变量
- 自变量:人群群体、收入层次、是否单身、信用等级
- 因变量:是否购买电脑
- 明确信息度量方式:信息增益
- 熵
- 基尼系数
- 明确分支终止条件
- 纯度
- 记录条数
- 循环次数
**构建一棵决策树**
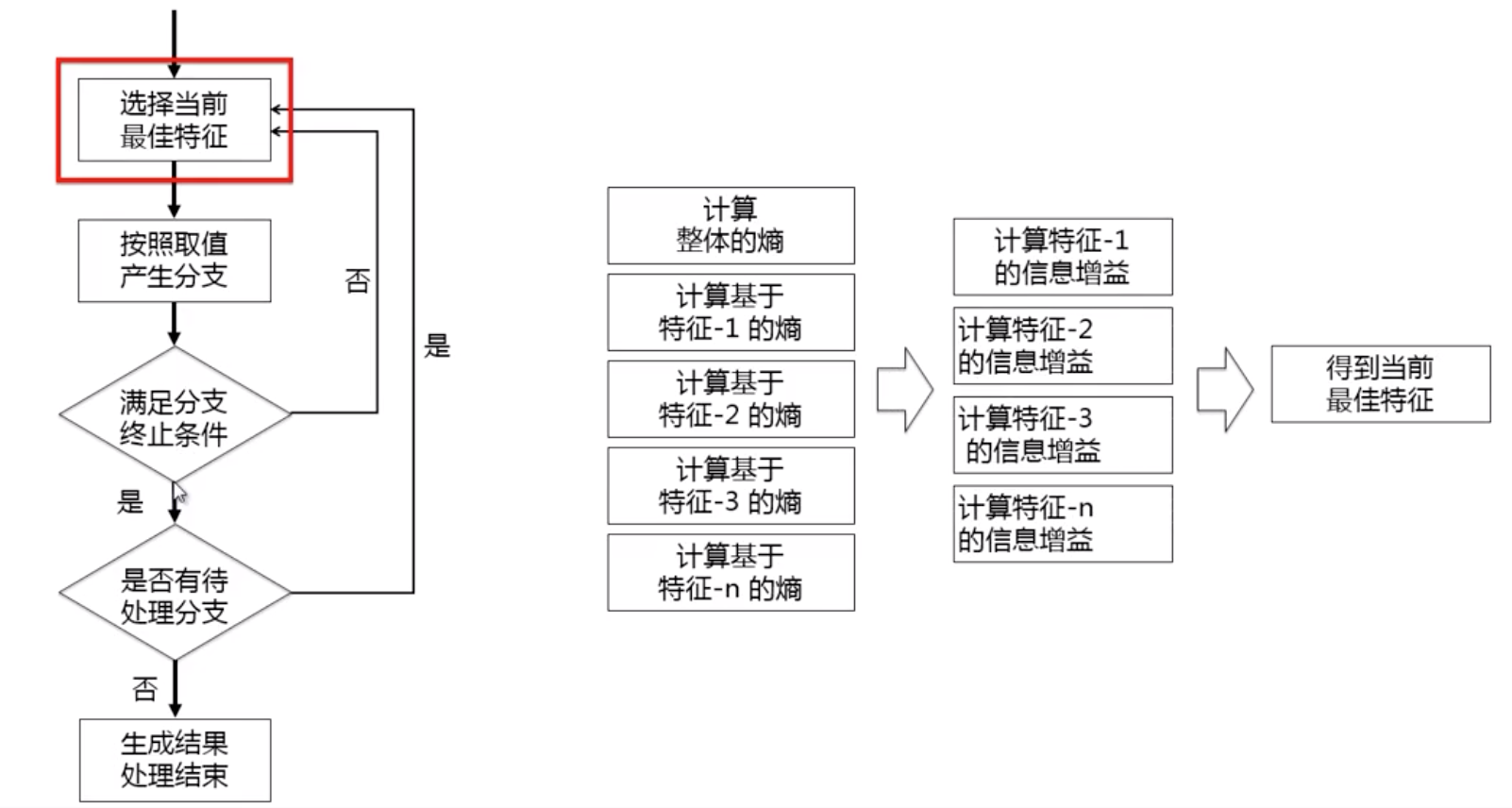
 观察各自的分支,再根据情况选择是否还需要再次挑选特征进行区分,最终的结果如下。
观察各自的分支,再根据情况选择是否还需要再次挑选特征进行区分,最终的结果如下。
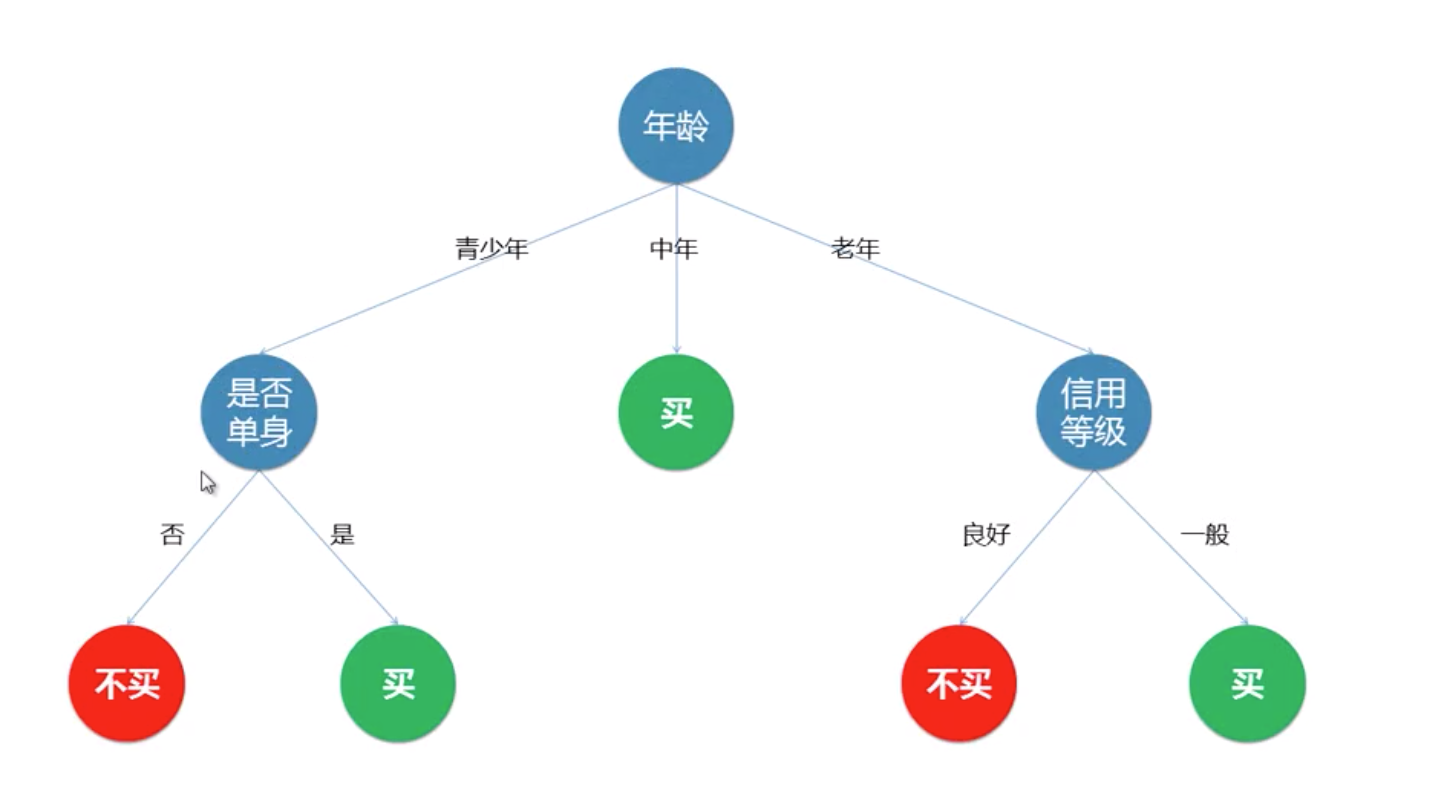
各类决策树算法的对比