引言
Pandas是一个开源的Python库,使用其强大的数据结构提供高性能的数据处理和分析工具。在Pandas之前,Python主要用于数据管理和准备。它对数据分析的贡献很小。Pandas解决了这个问题。使用Pandas,无论数据来源如何 - 加载,准备,操作,建模和分析,我们都可以完成数据处理和分析中的五个典型步骤。它可以将数据从不同文件格式加载到内存数据对象的工具,然后进行数据清洗和预分析。
pandas数据结构介绍
- Series:一种类似于一维数组的对象,它是由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生简单的 Series。
- DataFrame:一个表格型的数据结构,含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等),DataFrame既有行索引也有列索引。
Series
series 和字典有些类似,字典是通过 key 索引找到对象的 value。series 通过 index 索引找到一组对象的 value。series 用的不多,主要介绍下怎么创建,我们把重点篇幅放在 dateframe 上。
1、一维数组创建
可以通过 Series() 创建 Series 对象,index可以指定,也可以不写。
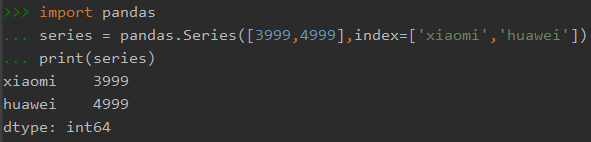
import pandas # 指定index值 series = pandas.Series([3999,4999],index=['xiaomi','huawei']) print(series)
输出:
import pandas # 默认index series = pandas.Series([3999,4999]) print(series)
输出:

2、字典创建
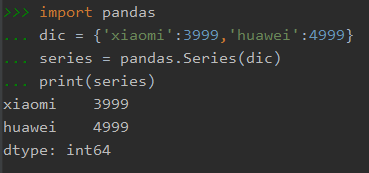
import pandas dic = {'xiaomi':3999,'huawei':4999} series = pandas.Series(dic) print(series)
输出:
Dateframe
Dateframe 有两个索引,一个行索引,另一个列索引。想象一下 excel 表格,就比较好理解了。
- 行索引:index,区分不同的行,axis = 0
- 列索引:column:区分不同的列,axis=1
1、创建 Dateframe 表格的几种方式:
import pandas '''通过列表创建''' # 一、默认方式 df = pandas.DataFrame([['xiaomi',3999],['huawei',4999]]) # 二、list(dict) 方式 df = pandas.DataFrame([{'xiaomi':3999,'huawei':4999},{'xiaomi':2999,'huawei':5999}]) # 三、指定 index 和 columns df = pandas.DataFrame([['xiaomi',3999],['huawei',4999]],index=['100','101'],columns=['品牌','价格']) '''通过字典创建''' dic = {'xiaomi':[3999,2999],'huawei':[4999,5999]} df = pandas.DataFrame(dic) '''创建一个空表格''' # 指定列名的空表格 df = pandas.DataFrame(columns=['xiaomi','huawei'])
2、向表格中添加一行/列数据
'''添加行数据''' # ignore_index=True 要记得加上,表示新的表格不按原来的索引,从0开始自动递增 df = pandas.DataFrame({'xiaomi':[3999,2999],'huawei':[4999,5999]}) # 添加一行数据 df = df.append({'xiaomi':1999,'huawei':6999},ignore_index=True) # 添加多行数据,使用list,list内元素为dict df = df.append([{'xiaomi':1999,'huawei':6999},{'xiaomi':999,'huawei':7999}],ignore_index=True) '''添加列数据''' # 方式一 df = pandas.DataFrame({'xiaomi':[3999,2999],'huawei':[4999,5999]}) # 直接命名列名,增加列的元素个数要跟原数据列的个数一样。 df['颜色'] = ['白色','黑色'] # 方式二 # 第一个参数为列的位置,第二个参数为列名,第三个为列的values df.insert(2,'颜色',['白色','黑色']) # 添加一列空值 df['颜色']=numpy.nan
3、修改数据
df = pandas.DataFrame({'xiaomi':[3999,2999],'huawei':[4999,5999]})
'''方式一'''
# 使用loc方法,loc[row_index,column]
df.loc[0,'xiaomi'] = 1999
df.loc[1,'huawei'] = 6999
'''方式二'''
# 使用iloc方法,iloc[row_index,column_index]
df.iloc[0,0] = 1999
df.iloc[1,1] = 6999
4、查询数据
df = pandas.DataFrame({'xiaomi':[3999,2999,2000,3000],'huawei':[4999,5999,4000,5000]})
'''查询数据的几种方式'''
# 列名查询
df['xiaomi']
df[['xiaomo','huawei']]
# 行索引查询
df[0:] # 第0行及以后的行索引,相当于全部数据
df[-1:] # 最后一行
df[1:3] # 第1行到第2行,不包含第3行
# loc方法
df.loc[1,'huawei'] # 精准查询5999
df.loc[0:2,'huawei'] # huawei列第0到2行
df.loc[[1,2],['xiaomi','huawei']] #指定第1行到第2行,xiaomi和huawei列的数据
df.loc[df['xiaomi']==2000,'huawei'] #条件查询,列xiaomi值为2000对应列huawei的值
df.loc[df['xiaomi']==2000,['huawei','xiaomi']]
#iloc方法
df.iloc[0,0] # 精准查询3999
df.iloc[[1,3],0:1] #第1行和3行,第0列和第1列的数据
df.iloc[1:3,[0,1]] # 第1行到第2行(不含第3行),第0列和第1列的数据
5、删除数据
df = pandas.DataFrame({'xiaomi':[3999,2999,2000,3000],'huawei':[4999,5999,4000,5000]})
# 删除第1和3行,axis : {0 or 'index', 1 or 'columns'}
df.drop([1,3],axis=0,inplace=True)
# 删除列,axis : {0 or 'index', 1 or 'columns'}
df.drop(['xiaomi'],axis=1,inplace=True)
# 或者使用del ,也能达到同样效果
del df['xiaomi']
6、替换所有表格中的 nan
# 将 nan 替换为0,inplace=True 原表格生效 df.fillna(0,inplace=True)
7、修改列名
df = pandas.DataFrame({'xiaomi':[3999,2999],'huawei':[4999,5999],'颜色':['白色','黑色']})
# 方式一
# rename方法
df.rename(columns={'xiaomi':'xiaomi','huawei':'huawei'},inplace=True)
# 方式二
# 直接修改所有列名
df.columns = ['xiaomi','huawei','颜色']
8、调整列顺序
df = pandas.DataFrame({'xiaomi':[3999,2999],'huawei':[4999,5999],'颜色':['白色','黑色']})
# 只改变列的顺序,values随着列的顺序移动
df = df[['xiaomi','颜色','huawei']]
9、sort_values 方法排序
# 按'xiaomi'列values 排倒序。ascending=Ture 正序,False 倒序 df.sort_values(by=['xiaomi'], ascending=False,inplace=True)
10、分组统计
df = pandas.DataFrame({'xiaomi':[3999,2999,1999,999],'huawei':[4999,5999,6999,7999],'颜色':['白色','黑色','白色','黑色']})
#根据颜色分组,对各列进行计数。分组过后组名会变成外索引,as_index=False,不变成索引
df = df.groupby(['颜色'],as_index=False).count()
#根据颜色分组,对xiaomi来计数
df = df.groupby(['颜色'],as_index=False).xiaomi.count()
#根据颜色分组,对xiaomi来计数
df = df.groupby(['颜色'],as_index=False)['xiaomi'].count()
#agg函数的用法:
#用法1:对一列用2个函数
df = df.groupby(['颜色'],as_index=False).agg(['mean','max'])
#用法2:对不同的列所用不同的聚合函数
df = df.groupby(['颜色'],as_index=False).agg({'xiaomi':'sum', 'huawei':'sum'})
11、dateframe 转成 list、dict
df = pandas.DataFrame({'xiaomi':[3999,2999,1999,999],'huawei':[4999,5999,6999,7999],'颜色':['白色','黑色','白色','黑色']})
# 转成list[list]
df.values.tolist()
# 转成dict,orient参数有6组值,源码里有注解,按需取即可
def to_dict(self, orient="dict", into=dict):
"""
Convert the DataFrame to a dictionary.
The type of the key-value pairs can be customized with the parameters
(see below).
Parameters
----------
orient : str {'dict', 'list', 'series', 'split', 'records', 'index'}
Determines the type of the values of the dictionary.
- 'dict' (default) : dict like {column -> {index -> value}}
- 'list' : dict like {column -> [values]}
- 'series' : dict like {column -> Series(values)}
- 'split' : dict like
{'index' -> [index], 'columns' -> [columns], 'data' -> [values]}
- 'records' : list like
[{column -> value}, ... , {column -> value}]
- 'index' : dict like {index -> {column -> value}}
Abbreviations are allowed. `s` indicates `series` and `sp`
indicates `split`.
into : class, default dict
The collections.abc.Mapping subclass used for all Mappings
in the return value. Can be the actual class or an empty
instance of the mapping type you want. If you want a
collections.defaultdict, you must pass it initialized.
'''
12、DataFrame与标量的加法运算
# 方式一 df = pandas.DataFrame({'xiaomi':[3999,2999,1999,999],'huawei':[4999,5999,6999,7999]}) # dataframe 所有的元素都+1000 df = df +1000 # dataframe 某一列元素+1000 df['xiaomi'] = df['xiaomi']+1000 # 方式二 # dataframe 所有的元素都+1000 df = df.add(1000) # 所有元素都加1000,fill_value给所有缺失值添加默认值 df = df.add(1000,fill_value=100)