1 Lucene的分页查询
搜索内容过多时, 需要考虑分页显示, 像这样:

说明: Lucene的分页查询是在内存中实现的.
2 代码示例
/**
* 检索索引(实现分页)
* @throws Exception
*/
@Test
public void searchIndexByPage() throws Exception {
// 1. 创建分析器对象(Analyzer), 用于分词
// Analyzer analyzer = new StandardAnalyzer();
// 使用ik中文分词器
Analyzer analyzer = new IKAnalyzer();
// 2. 创建查询对象(Query)
// bookName:lucene
// 2.1 创建查询解析器对象
// 参数一: 指定一个默认的搜索域
// 参数二: 分析器
QueryParser queryParser = new QueryParser("bookName", analyzer);
// 2.2 使用查询解析器对象, 实例化Query对象
// 参数: 查询表达式
Query query = queryParser.parse("bookName:lucene");
// 3. 创建索引库目录位置对象(Directory), 指定索引库的位置
Directory directory = FSDirectory.open(new File("/Users/healchow/Documents/index"));
// 4. 创建索引读取对象(IndexReader), 用于读取索引
IndexReader reader = DirectoryReader.open(directory);
// 5. 创建索引搜索对象(IndexSearcher), 用于执行搜索
IndexSearcher searcher = new IndexSearcher(reader);
// 6. 使用IndexSearcher对象, 执行搜索, 返回搜索结果集TopDocs
// search方法: 执行搜索
// 参数一: 查询对象
// 参数二: n - 指定返回排序以后的搜索结果的前n个
TopDocs topDocs = searcher.search(query, 10);
// 7. 处理结果集
// 7.1 打印实际查询到的结果数量
System.out.println("实际查询的结果数量: "+topDocs.totalHits);
// 7.2获取搜索的结果数组
// ScoreDoc中: 有我们需要的文档的id, 有我们需要的文档的评分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
// 增加分页实现 ========= start
// 当前页
int page = 2;
// 每页的大小
int pageSize = 2;
// 计算记录起始数
int start = (page - 1) * pageSize;
// 计算记录终止数 -- 得到数据索引与实际结果数量中的最小值, 防止数组越界
// 数据索引: start + pageSize
// 实际的结果数量: scoreDocs.length
int end = Math.min(start + pageSize, scoreDocs.length);
// 增加分页实现 ========= end
for(int i = start; i < end; i++){
System.out.println("= = = = = = = = = = = = = = = = = = =");
// 获取文档Id和评分
int docId = scoreDocs[i].doc;
float score =scoreDocs[i].score;
System.out.println("文档Id: " + docId + " , 文档评分: " + score);
// 根据文档Id, 查询文档数据 -- 相当于关系数据库中根据主键Id查询
Document doc = searcher.doc(docId);
System.out.println("图书Id: " + doc.get("bookId"));
System.out.println("图书名称: " + doc.get("bookName"));
System.out.println("图书价格: " + doc.get("bookPrice"));
System.out.println("图书图片: " + doc.get("bookPic"));
System.out.println("图书描述: " + doc.get("bookDesc"));
}
// 8. 释放资源
reader.close();
}
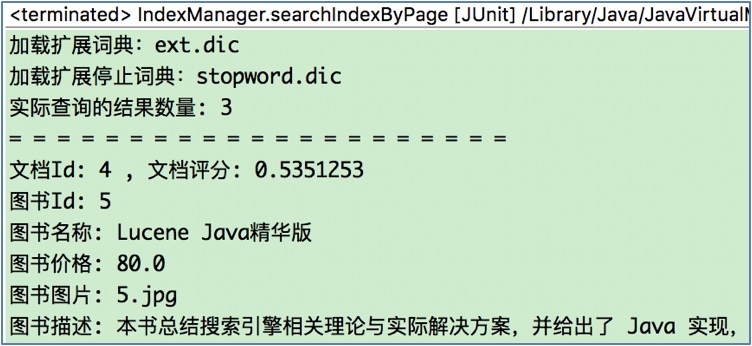
3 分页查询结果
这里查询到的结果共有3条, 所以第2页只有一条结果:
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.