线性最小二乘拟合 y = w0 +w1x (参数 w0, w1)
(1)如何评价一条拟合好的直线 y = w0 +w1x 的误差?
"cost" of a given line : Residual sum of squares (RSS)
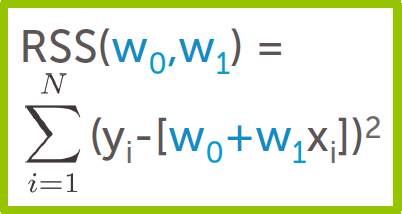
(2)最小二乘方法的思路
使 RSS 尽量小。
即
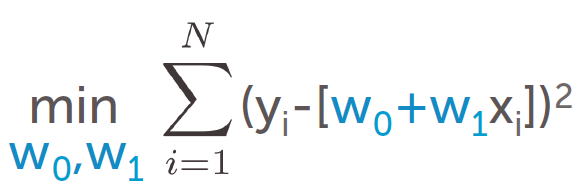
而RSS 函数的图像是这样的:
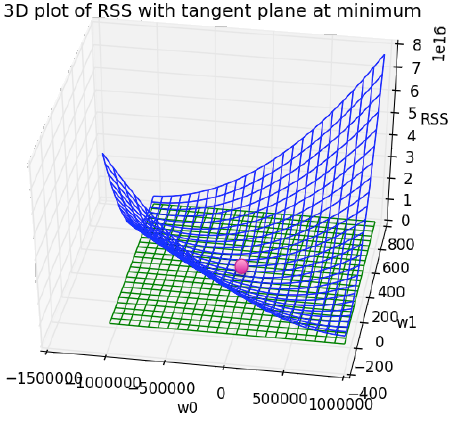
极小值 处导数为0.
对RSS 求导:
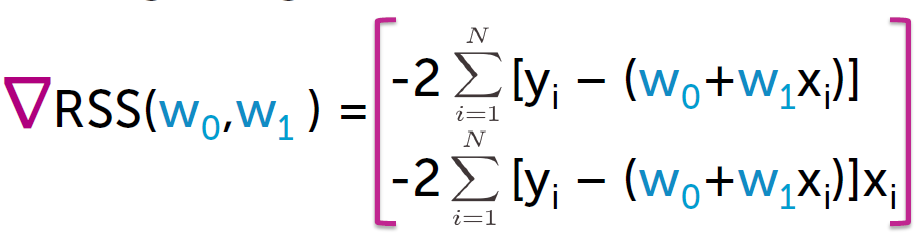
有两种方法求解。
1.closed form:
解析解, 使gradient = 0
得到:
w1: slope = ((sum of X * Y) - (1/N)*(sum of X)*(sum of Y)) / ((sum of X^2) -(1/N)* (sum of X)*(sum of X))
w0: intercept = (1/N)*(sum of Y) - slope * (1/N)* (sum of X)
2.gradient descent
梯度下降方法。
对于简单的函数拟合,可以直接求出解析解。但对于一些不能直接求出解析解的情况(例如神经网络),就可以使用梯度下降方法。
注意到:
w0 的导数 = sum (yi - (w0+w1xi) ) ,即 w0导数 = sum( error )
w1的导数 = sum( error*x )
算法过程:
step 0.初始化:
initial_w0 = 0
initial_w1 = 0
step_size = 0.05
tolerance = 0.01
step 1 ~. 对于接下来的每一步:
(1)根据当前 w0、 w1 计算 y ,并计算w0 、w1的导数 sum( error ) 和 sum( error *x)
(2)更新 w0 、w1 的值:
adjustment = step_size * derivative(导数)
w0 = w0 - adjustment (w1 同理)
(3)检查算法是否应该结束(导数是否已经收敛到一个很小的值了):
magnitude = sqrt(sum (derivative ^2))
if magnitude < tolerance:
end
出处:华盛顿大学machine learning:regression week 1