前言
kafka是一种分布式的基于发布/订阅模式的消息队列,主要用于大数据实时处理领域;下面总结下kafka集群搭建方法
准备工作
1、三台linux环境,地址分别为192.168.1.51、192.168.1.52、192.168.1.53
2、jdk1.8.0_252,当然其他版本也行
3、apache-zookeeper-3.6.1,下载地址https://zookeeper.apache.org/releases.html
4、kafka_2.13-2.5.0,下载地址https://kafka.apache.org/downloads#2.5.0
JDK、Zookeeper、Kafka安装
在三台linux机器上usr目录下创建bale目录,将jdk-8u252-linux-x64.tar.gz、apache-zookeeper-3.6.1-bin.tar.gz、kafka_2.13-2.5.0.tgz放到/usr/bale目录下
1、JDK安装
(1)tar -xvf jdk-8u252-linux-x64.tar.gz解压到当前文件夹
(2)vi /etc/profile,配置环境变量,将如下内容写入/etc/profile,然后source /etc/profile使环境变量生效
export JAVA_HOME=/usr/bale/jdk1.8.0_252
export JRE_HOME=/usr/bale/jdk1.8.0_252/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
2、Zookeeper安装
(1)tar -xvf apache-zookeeper-3.6.1-bin.tar.gz解压到当前文件夹,然后将文件夹的名字改为zookeeper
(2)vi /etc/profile,配置环境变量,将如下内容写入/etc/profile,然后source /etc/profile使环境变量生效
#set zookeeper environment
export ZK_HOME=/usr/bale/zookeeper
export PATH=$ZK_HOME/bin:$PATH
3、kafka安装
(1)tar -xvf kafka_2.13-2.5.0.tgz解压到当前文件夹,然后将文件夹的名字改为kafka
(2)vi /etc/profile,配置环境变量,将如下内容写入/etc/profile,然后source /etc/profile使环境变量生效
#set kafka environment
export KAFKA_HOME=/usr/bale/kafka
PATH=${KAFKA_HOME}/bin:$PATH
Zookeeper集群搭建
简单的说kafka集群依赖zookeeper集群,这里先说下该如何配置并启动zookeeper集群
1、进入/usr/bale/zookeeper/conf目录,将zoo.sample.cfg更名为zoo.cfg
2、创建/usr/bale/zookeeper/zkdata目录,用来存储zookeeper数据
3、修改zoo.cfg配置文件如下:
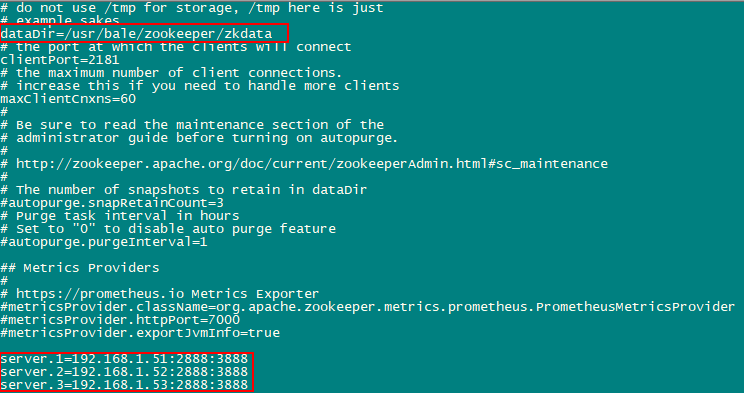
其中server.A=B:C:D的含义是:
A --- 数字,表示zookeeper服务器编号
B --- IP地址,表示zookeeper服务器地址
C --- zk集群Leader选举的端口号
D --- zookeeper服务器间通信端口号
4、在三台机器的/usr/bale/zookeeper/zkdata目录下分别执行如下命令:
echo "1" > /usr/bale/zookeeper/zkdata/myid
echo "2" > /usr/bale/zookeeper/zkdata/myid
echo "3" > /usr/bale/zookeeper/zkdata/myid
5、上述配置完成后,执行zkServer.sh start启动zookeeper集群,启动后可以用zkServer.sh status查看zookeeper集群状态
192.168.1.51

192.168.1.52

192.168.1.53

如上图所示,表示zookeeper集群启动成功
kafka集群搭建
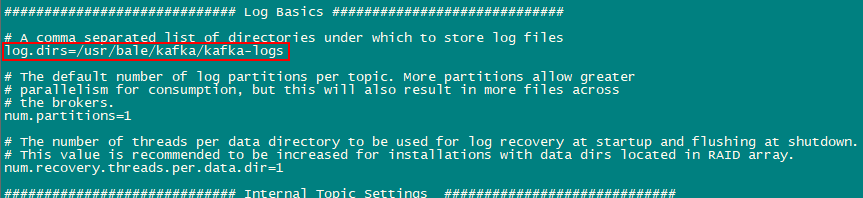
1、创建/usr/bale/kafka/kafka-logs目录,作为kafka数据存储路径
2、修改kafka配置文件/usr/bale/kafka/config/server.properties文件
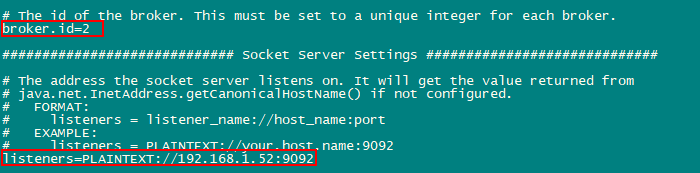
(1)broker.id分别指定为1/2/3,然后修改listeners参数
(2)指定kafka数据存储路径
(3)指定zookeeper连接地址以及topic可删除
delete.topic.enable=true
zookeeper.connect=192.168.1.51:2181,192.168.1.52:2181,192.168.1.53:2181
3、启动kafka集群kafka-server-start.sh -daemon config/server.properties
4、通过shell脚本,创建topic,验证kafka集群是否正常
kafka-topics.sh --create --zookeeper 192.168.1.51:2181 --partitions 2 --replication-factor 2 --topic test-kafka-cluster
kafka-topics.sh --describe --zookeeper 192.168.1.51:2181 --topic test-kafka-cluster

如图所示该topic有两个分区,两个副本,kafka集群正常启动