从架构上看,Microsoft NLayerApp对“复杂的业务系统应用程序”这样一种应用程序的架构设计提供了一系列的设计准则。所谓“复杂的业务系统应用程序”是指这样一类业务系统应用程序,这类应用程序具有相对较长的生命周期,在其生命周期中,将发生一些可预期的“革命性变更”(比如,所使用的技术/框架的版本升级甚至替换),因此后期维护会变得非常重要。于是,针对这种类型应用程序的设计,我们应该做到,当“革命性变更”来临时,将这种变更对应用程序其他部分的影响减少到最小程度,例如,我们要确保基于基础结构层的设施变更不会影响到其上层的各个部分。更确切地说,应用程序的领域模型部分应该只关注领域本身,变更应用程序的其它部分,不会影响到领域模型。在“复杂的业务系统应用程序”中,业务规则的行为方式(也就是“领域逻辑”)将会是经常变化的,因此,使其具有很好的可修改性和可测试性将会非常重要。要达到这样的效果,就需要实现领域模型部分与系统其它部分的解耦。作为领域驱动设计(DDD)的一部分的面向领域的多层分布式架构,关注的就是这样的问题。
不选用面向领域的多层分布式架构(DDD风格架构)的理由
如果应用程序相对简单,而且在其生命周期的整个过程中,基础结构所使用的技术和框架以及业务逻辑层等各方面都不会有太大的变更,那么你就不需要选用基于DDD的多层分布式架构。你可以选择一些RAD(Rapid Application Development)的技术,比如WCF RIA Services或者Visual Studio Lightswitch等,它能使得开发简单的应用程序变得非常高效。这些简单的应用程序关注的是Time to Market(TTM),而对于合理的结构、分层解耦等概念却并不是很关注。通常,我们把这样的应用程序成为“数据驱动的应用程序”。
选用面向领域的多层分布式架构(DDD风格架构)的理由
如果你希望你的应用程序在较长的一段时间内都能够适应业务逻辑的变化,那么,强烈建议你选用面向领域的多层分布式架构。在这种情况下,领域模型将降低由业务逻辑变化而引起的高额代价,组件之间、层与层之间低耦合的结构,使得在每次出现业务逻辑变更的时候,你都能够将领域模型隔离出来进行调整和测试,而不需要更改应用程序的其它部分,这样有效地降低了需求变更带来的开发风险,并节省了项目开支。
分布式DDD(Distributed DDD, DDDD)
这个概念是Microsoft NLayerApp在其Guide Book中提及的,就是在DDD风格架构的基础上,将分布式的特性包含进来。在Eric Evans的《领域驱动设计-软件核心复杂性应对之道》一书中,他并没有提及太多的有关分布式技术的内容(比如Web Service技术等),主要也是因为针对DDD的讨论本身也是立足于Domain的。然而,在实际的应用程序实现和部署过程中,分布式技术是必不可少的。事实上,Microsoft NLayerApp是面向分布式DDD的,在实现“分布式”的过程中,采用了微软特有的技术,比如WCF等。DDDD也使得应用程序能够更好地适应分布式场景,甚至可以使应用程序更方便地部署到云计算的环境中。
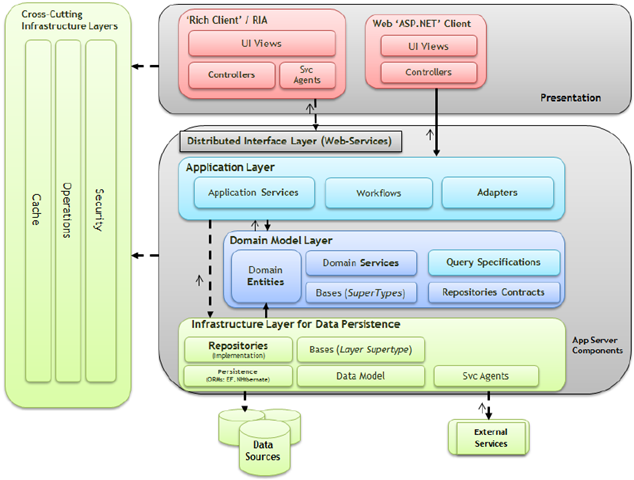
表现层(Presentation):该层的主要职责是通过用户界面向用户展示必要的数据信息,同时接收用户的反馈。该层中的组件主要实现了与图形界面、用户操作捕获、数据转发等用户界面功能。建议根据项目的实际情况,选用相关的模式(比如MVC、MVP或者MVVM等)将这些组件细分到更小的层中。
分布式服务层(Distributed Service Layer):当应用程序以服务提供商(Service Provider)的方式向其它远程应用程序提供业务功能时,或者应用程序的客户端本身是被部署在另一个远程位置时,其业务逻辑就必须通过分布式服务层向外界发布。分布式服务层(通常被实现为Web Service)可以根据可配置的通信通道与数据消息格式,为应用程序提供远程访问的功能。需要注意的是,分布式服务层中不应该包含任何业务逻辑的实现。
应用层(Application Layer):应用层用于协调领域模型与其它应用组件的工作,以完成一个特定的、明确的系统任务。这种协调可以包括:事务调度、UoW(Unit Of Work,PoEAA)的执行,以及调用一些系统必须的处理任务等。应用层同时还可以包括应用程序的优化、数据的转发和格式转换等工作,当然,我们将这些工作统称为“任务调度”,至于每个任务的核心部分,应用层都会将其转发到下层去处理。应用层通常会被看做是一种“业务层外观(Business Facade)”,但它却不仅仅是转发领域模型层的处理请求/反馈那么简单。它通常可以包含下面这些内容:
通过仓储契约(Repository Contract)来访问持久层机制,以读取或保存领域对象。注意这里访问的是仓储契约,而并非仓储的具体实现。仓储的具体实现是基础结构层的内容。
对来自于不同领域对象的数据进行组织和整理,以便能够让分布式服务层更有效地传递这些数据。通常,我们会将数据整理在数据传输对象(Data Transfer Object,PoEAA)中,例如WCF的Data Contracts。
管理和维护应用程序的状态(而不是领域模型中领域对象的状态)。
协调领域对象之间、领域模型与基础结构层组件之间的协作关系。比如在银行转账系统中,资金从一个账户转移到另一个账户,首先需要通过仓储读取“账户”领域对象,然后在领域对象上进行转账操作(可以是“账户”本身的行为,也可以是,按Evans的举例,使用领域服务(Domain Service))。或许在完成转账后,无论成功与否,都需要向外发送电子邮件,这就需要基础结构层的电子邮件组件协作完成。
应用服务(Application Services):首先需要注意,DDD中提到的服务与平时所说的Web Service等并不是一个概念,它可以存在于应用层、领域模型层甚至基础结构层。DDD中Service所表述的概念,其实是“无法归结到任何一个对象”的一系列操作的集合,因此,Service通常是在协调不同对象之间的工作。应用服务也是如此,它会对其它下层组件(比如领域模型层与基础结构层)进行协调。
业务工作流(Business Workflow):业务工作流并非必须的,对于某些由特定步骤组成的业务过程,引入业务工作流会使问题变得简单。
领域模型层(Domain Model Layer):该层的主要职责是展现业务/领域逻辑、业务处理状态,以及实现业务规则,它同时也包含了领域对象的状态信息。这一层是整个应用程序的核心部分,它可以包含下面这些概念和内容:
实体(Entities)
值对象(Value Objects)
领域服务(Domain Services)
仓储契约/接口(Repository Contracts/Interfaces)
聚合及其工厂(Aggregates and Factories)
聚合根(Aggregate Roots)
规约对象(Specifications)
基础结构层(数据持久化部分)(Data Persistence Infrastructure Layer):该层为应用程序的数据存取提供服务,它可以是应用程序本身的持久化机制,也可以是外部系统提供的数据访问的Web Service等。根据分层架构的设计原则,该层应该以“低耦合”的方式向上层提供数据持久化服务。因此,该层可以包含如下这些内容:
仓储的具体实现:从概念上看,“仓储”意味着对一组相同类型对象的集中管理,就好像是存取同一类型对象的仓库。然而在实践中,仓储主要用来在特定的持久化机制/技术上执行对象的读取和保存操作。这些持久化机制/技术可以是Entity Framework、NHibernate或者是针对某一数据库引擎的ADO.NET组件。为了简单起见,我们将数据访问操作集中到仓储中,并针对不同的持久化机制/技术开发一个仓储的具体实现,这将会对应用程序的维护和部署带来便捷。在设计仓储时,通常的做法是,首先对领域模型划分聚合并区分聚合根,然后针对每一个聚合设计一个仓储,仓储通过聚合根对聚合进行管理。在领域模型层中,各组件是通过仓储契约(接口)来实现对仓储的访问的,这样做就使得领域模型层无需了解任何仓储的具体实现和持久化细节(Persistence Ignorance)。此外,我们通常所讲的“数据访问对象(Data Access Object)”并不是仓储,首先,仓储通过聚合根,负责整个聚合的读取和存储,它是一个领域概念,而数据访问对象则是对单个对象(更确切地说应该是单个数据结构)直接进行数据库操作;其次,操作方式也不同,仓储会在提交前先对内存中的对象进行标记,最后的一次提交过程(Unit Of Work,PoEAA)则是在上层组件(比如在应用层)中完成的
层超类型(Layer Supertype,PoEAA):通常,在实现某层的特定功能时,我们会将一系列对象的公共逻辑提取出来,然后将这些逻辑置于一个抽象类型中,同时使得其它类型都继承于该抽象类型以避免逻辑重复。这样的抽象类型被称为层超类型。大多数数据访问任务可以使用层超类型以简化开发,减少代码维护成本。例如,在实现面向ADO.NET的数据库访问组件时,我们可以在层超类型中使用DbConnection、DbCommand等对象实现公用逻辑,然后在子类中继承这些逻辑并提供具体的SqlConnection、SqlCommand或者OleDbConnection、OleDbCommand实例
数据模型(Data Model):如果使用ORM来实现仓储,那么通常情况下ORM都会使用一个数据模型(比如Entity Framework)来实现需要的功能,这样的数据模型有点像实体模型,但它与数据传输对象一样,跟领域模型层的实体模型是完全不同的。数据模型甚至是一种可视化的图形描述,由专门的可视化设计工具负责维护
远程/外部服务代理:当采用外部系统来实现数据持久化机制时,远程/外部服务代理负责连接外部系统并转发数据操作请求及响应信息
基础结构层(Cross-Cutting):该层提供了能被其它各层访问的通用技术框架,比如异常捕获与处理、日志、认证、授权、验证、跟踪、监视、缓存等等。这些操作通常会横向散布在应用程序的各个层面,我们平时讨论的面向方面编程(AOP)关注的就是如何在不影响对象本身处理逻辑的基础上来实现这些横切的却又必不可少的功能点。在实践中,通过使用一些流行的Interception框架(例如Microsoft Unity、Castle DynamicProxy等)可以帮助我们方便地实现AOP。