原文链接:https://zhuanlan.zhihu.com/p/23249000
目录

场景分类
数据增强
数据增强对最后的识别性能和泛化能力都有着非常重要的作用。我们使用下面这些数据增强方法。
- 第一,对颜色的数据增强,包括色彩的饱和度、亮度和对比度等方面,主要从Facebook的代码里改过来的。
- 第二,PCA Jittering,最早是由Alex在他2012年赢得ImageNet竞赛的那篇NIPS中提出来的. 我们首先按照RGB三个颜色通道计算了均值和标准差,对网络的输入数据进行规范化,随后我们在整个训练集上计算了协方差矩阵,进行特征分解,得到特征向量和特征值,用来做PCA Jittering。
- 第三,在图像进行裁剪和缩放的时候,我们采用了随机的图像差值方式。
- 第四, Crop Sampling,就是怎么从原始图像中进行缩放裁剪获得网络的输入。
比较常用的有2种方法:
一是使用Scale Jittering。VGG和ResNet模型的训练都用了这种方法。
二是尺度和长宽比增强变换。最早是Google提出来训练他们的Inception网络的。我们对其进行了改进,提出Supervised Data Augmentation方法。

尺度和长宽比增强变换有个缺点,随机去选Crop Center的时候,选到的区域有时候并不包括真实目标的区域。这意味着,有时候使用了错误的标签去训练模型。如图所示,左下角的图真值标签是风车农场,但实际上裁剪的区域是蓝天白云,其中并没有任何风车和农场的信息。
我们在Bolei今年CVPR文章的启发下,提出了有监督的数据增强方法。我们首先按照通常方法训练一个模型,然后用这个模型去生成真值标签的Class Activation Map(或者说Heat Map), 这个Map指示了目标物体出现在不同位置的概率. 我们依据这个概率,在Map上随机选择一个位置,然后映射回原图,在原图那个位置附近去做Crop。

如下图所示,对比原始的尺度和长宽比增强变换,我们方法的优点在于,我们根据目标物体出现在不同位置的概率信息,去选择不同的Crop区域,送进模型训练。通过引入这种有监督的信息,我们可以利用正确的信息来更好地训练模型,以提升识别准确率。 (+0.5~0.7)

样本平衡
场景数据集有800万样本,365个类别,各个类别的样本数非常不平衡,有很多类别的样本数达到了4万,也有很多类别的样本数还不到5000。这么大量的样本和非常不均匀的类别分布,给模型训练带来了难题。
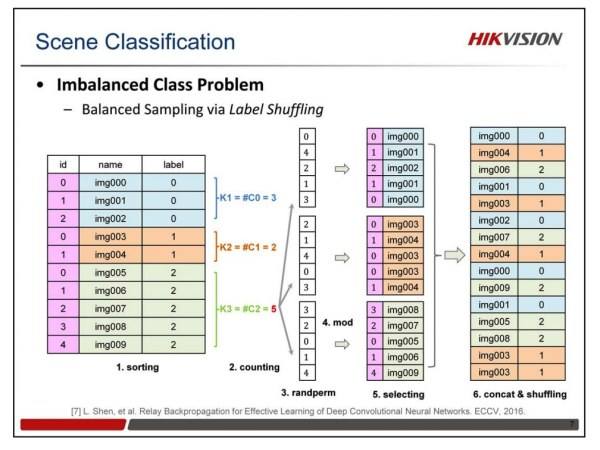
Label Shuffling平衡策略
在去年冠军团队的Class-Aware Sampling方法的启发下,我们提出了Label Shuffling的类别平衡策略。在Class-Aware Sampling方法中,他们定义了2种列表,一是类别列表,一是每个类别的图像列表,对于365类的分类问题来说,就需要事先定义366个列表,很不方便。我们对此进行了改进,只需要原始的图像列表就可以完成同样的均匀采样任务。以图中的例子来说,步骤如下:
- 首先对原始的图像列表,按照标签顺序进行排序;
- 然后计算每个类别的样本数量,并得到样本最多的那个类别的样本数。
- 根据这个最多的样本数,对每类随机都产生一个随机排列的列表;
- 然后用每个类别的列表中的数对各自类别的样本数求余,得到一个索引值,从该类的图像中提取图像,生成该类的图像随机列表;
- 然后把所有类别的随机列表连在一起,做个Random Shuffling,得到最后的图像列表,用这个列表进行训练。
每个列表,到达最后一张图像的时候,然后再重新做一遍这些步骤,得到一个新的列表,接着训练。Label Shuffling方法的优点在于,只需要原始图像列表,所有操作都是在内存中在线完成,非常易于实现。
Label Smoothing策略
我们使用的另外一个方法是Label Smoothing,是今年Google的CVPR论文中提出来的方法。根据我们的混淆矩阵(Confusion Matrix)的分析,发现存在很多跨标签的相似性问题,这可能是由于标签模糊性带来的。所以,我们对混淆矩阵进行排序,得到跟每个标签最相近的4个标签,用它们来定义标签的先验分布,将传统的 one-hot标签,变成一个平滑过的soft标签。通过这种改进,我们发现可以从某种程度上降低过拟合问题。(+0.2~0.3)

性能提升技巧
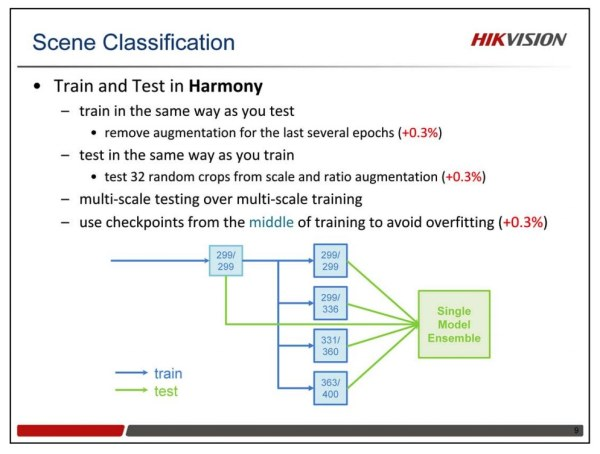
这边还有一些其他的技巧来提升性能,我们将其总结成一个原则:训练和测试要协调。在训练的时候,我们通常都需要做数据增强,在测试的时候,我们通常很少去做数据增强。这其中似乎有些不协调,因为你训练和测试之间有些不一致。通过我们的实验发现,如果你在训练的最后几个epoch,移除数据增强,然后跟传统一样测试,可以提升一点性能。同样,如果训练的时候一直使用尺度和长宽比增强数据增强,在测试的时候也同样做这个变化,随机取32个crop来测试,也可以在最后的模型上提升一点性能。还有一条,就是多尺度的训练,多尺度的测试。另外,值得指出的是,使用训练过程的中间结果,加入做测试,可以一定程度上降低过拟合。
对于模型结构,没什么特别的改进,我们主要使用了Inception v3和Inception ResNet v2,以及他们加深加宽的版本。还用到了Wide ResNet 。

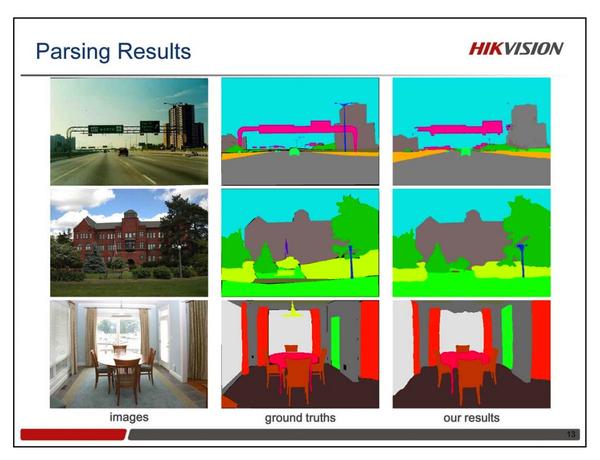
场景解析
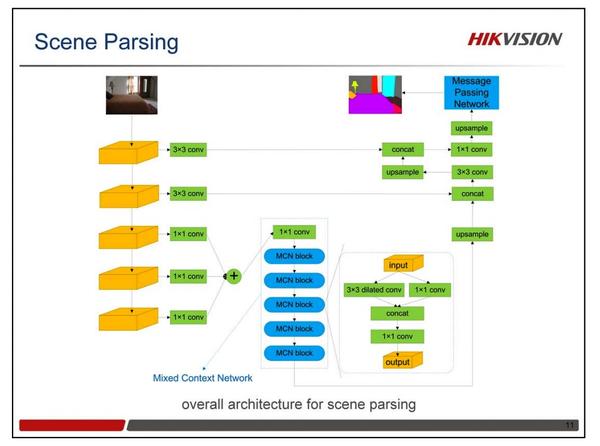
此次竞赛的语义分割任务非常具有挑战性。它一方面需要目标整体层面的信息,同时还需要每个像素的分类准确率。目前有很多语义分割的模型,但哪一种框架是最好的仍然是一个问题。我们设计了一个Mixed Context Network(MCN),它由一系列Mixed Context Blocks(MCB)堆叠而成。如图所示,每个MCB包括两个并行的卷积层:1个1x1卷积和1个3x3 Dilated卷积。Dilated卷积的采样率分别设置成了1,2,4,8,16。除了MCN之外,我们还在最后设计了一个Message Passing Network(MPN),来增强不同标签之间的空间一致性。
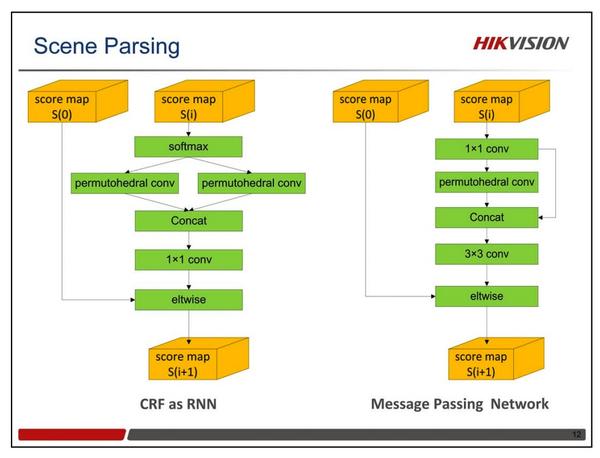
CRF as RNN可以被加到网络的最后,与CNN一起联合训练。但是CRF as RNN比较耗费显存,尤其是在类别数比较大的时候(比如ADE20K有150类)。可以通过降低输入图像的分辨率来节省显存,但是这样做也会带来一些负面影响。为了解决这个问题,我们引入了一个新的比较省显存的模块,叫做MPN。在MPN中,我们首先将Score Map的通道从150降到了32,然后接了一个Permutohedral卷积层,用于做高维的高斯滤波。我们去掉了其中的平滑项,仅仅将1x1卷积层的特征和Permutohedral卷积层的特征连接,然后接一个3x3的卷积。实验证明,这样的结构也能较好地工作。
物体检测与定位
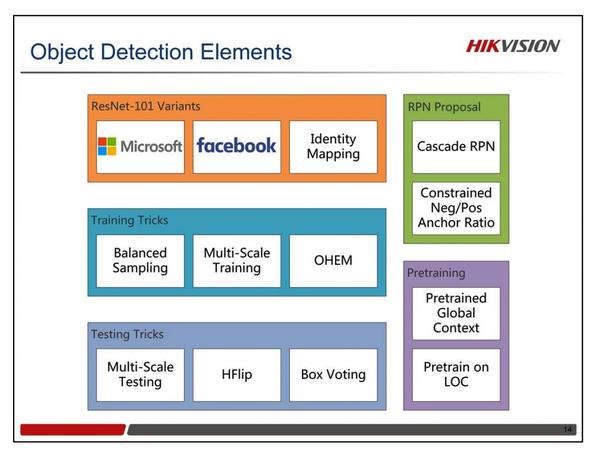
我们的检测和定位,都是基于Faster-RCNN这个框架。图中我们列出了所有用到的技巧。有很多技巧在以前的文献中都可以找到,比如多尺度的训练和测试,难样本挖掘,水平翻转和Box Voting。但我们自己也做了很多新的改进,比如样本均衡,Cascade RPN,预训练的Global Context等。至于网络结构,我们仅仅用了三个ResNet-101模型。一个来自于MSRA,一个来自于Facebook,还有一个是我们自己训练的Identity Mapping版的ResNet-101。我们最好的单模型结果,是源自我们自己训练的Identity Mapping版的ResNet-101。
我们设计了一个轻量级的Cascade RPN。2个RPN顺序堆叠在一起。 RPN 1使用滑窗Anchors,然后输出比较精确定位的Proposals。RPN 2使用RPN 1的Proposals作为Anchors。我们发现这个结构可以提升大中尺寸Proposals的定位精度,但不适合小的Proposals。所以在实际中,我们RPN1提取小的Proposals,RPN2提取大中尺寸的Proposals。注: Proposals尺寸的阈值是64 * 64。
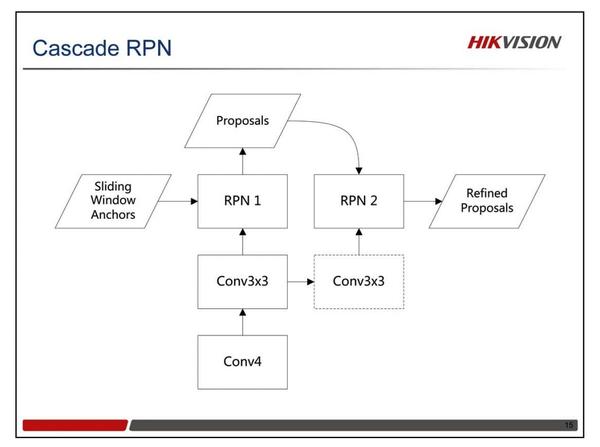
另外一个改进就是限制正负Anchor的比例。在传统的RPN中,Batch Size通常是256,理想的正负Anchor比例是1。但是在实际使用中,这个比例往往会很大,通常会大于10。所以我们缩小了Batch Size,控制最大的比例为1.5。最小的Batch Size设置为32。对比实验表明,使用Cascade RPN和限制正负Anchor比例这两个策略,在ImageNet DET的验证集上,AR提升了5.4个点,Recall@0.7提升了9.5个点,而Recall@0.5只提升1个点。这说明Proposals的定位精度得到了显著的改善。

Global Context在去年Kaiming的论文中就已经提到,他们使用这个方法得到了1个点的mAP提升。我们也实现了自己的Global Context方法:除了在在RoI上做RoIPooling 之外,我们还对全图做了RoIPooling来获得全局特征。这个全局特征仅仅被用来分类,不参加bbox回归。我们实验发现,Global Context如果使用随机初始化,其性能提升有限。当我们采用预训练的参数进行精调之后,发现mAP的性能可以提升3.8个点。

此外,我们发现,在1000类的LOC上预训练,然后再在DET数据上精调,可以 得到额外0.5个点的mAP提升。

平衡采样是去年场景分类任务中所用到的一个技巧。我们也将它用来做检测任务。左侧是一个类别的列表,对于每个类别,我们又创建了一个图像列表。训练过程中,我们先从类别列表中选择一个类别,然后从这个类对应的图像列表中采样。和分类任务不同的是,检测任务中一张图像可能包含多个类别的目标。对于这种多标签的图像我们允许它们出现在多个类别的图像列表中。使用平衡采样技术,可以在VOC2007数据集上获得0.7的mAP提升。

集成上述所列的各项技术,我们的检测模型取得了SOTA的性能。在ImageNet DET任务中,我们以65.3的mAP获得了第二名。就单个模型而言,我们的模型能以少许优势排名第一。我们使用了相同的检测框架来完成ImageNet LOC任务。在最后的竞赛中,我们以8.7的定位误差排名第二。在PASCAL VOC 2012检测任务中,我们单模型获得了87.9的 mAP,超过了去年Kaiming的模型有4个点之多。
