楔子
我们知道python的执行效率不是很高,而且由于GIL的原因,导致python不能充分利用多核CPU。一般的解决方式是使用多进程,但是多进程开销比较大,而且进程之间的通信也会比较麻烦。因此在解决效率问题上,我们会把那些比较耗时的模块使用C或者C++编写,然后编译成动态链接库,Windows上面是dll,linux上面则是so,编译好之后,交给python去调用。而且通过动态链接库的方式还可以解决python的GIL的问题,因此如果想要利用多核,我们仍然可以通过动态链接库的方式。
python如何调用动态链接库
python调用动态链接库的一种比较简单的方式就是使用ctypes这个库,这个库是python官方提供的,任何一个版本的python都可以使用,我们通过ctypes可以很轻松地调用动态链接库。
#include <stdio.h>
void test()
{
printf("hello world
");
}
我们定义了一个很简单的函数,下面我们就可以将其编译成动态链接库了。在Windows是dll,linux上是so,编译的命令是一样的。我这里以Windows 为例,记得在Windows上要安装MinGW,或者安装VsCode,我这里使用的是MinGW,因为VsCode太大了。
gcc -o dll文件或者so文件 -shared c或者c++源文件
我这里的C源文件叫做1.c,我们编译成mmp.dll吧,所以命令就可以这么写:gcc -o mmp.dll -shared 1.c

下面就可以使用python去调用了。
import ctypes
# 使用ctypes很简单,直接import进来,然后使用ctypes.CDLL这个类来加载动态链接库
# 如果在Windows上还可以使用ctypes.WinDLL。
# 因为看ctypes源码的话,会发现WinDLL也是一个类并且继承自CDLL
# 所以在linux上使用ctypes.CDLL,
# 而在Windows上既可以使用WinDLL、也可以使用CDLL加载动态链接库
lib = ctypes.CDLL("./mmp.dll") # 加载之后就得到了动态链接库对象
# 我们可以直接通过.的方式去调用里面的函数了,会发现成功打印
lib.test() # hello world
# 但是为了确定是否存在这个函数,我们一般会使用反射去获取
# 因为如果函数不存在通过.的方式调用会抛异常的
func = getattr(lib, "test", None)
if func:
print(func) # <_FuncPtr object at 0x0000029F75F315F0>
func() # hello world
# 不存在test_xx这个函数,所以得到的结果为None
func1 = getattr(lib, "test_xx", None)
print(func1) # None
所以使用ctypes去调用动态链接库非常方便
1.通过ctypes.CDLL("dll或者so的路径"),如果是Windows还可以使用ctypes.WinDLL("dll路径")。另外这两种加载方式分别等价于:ctypes.CDLL("dll或者so的路径") == ctypes.cdll.LoadLibrary("dll或者so的路径"),ctypes.WinDLL("dll路径") == ctypes.windll.LoadLibrary("dll路径")。但是注意的是:linux上只能使用ctypes.CDLL和ctypes.cdll.LoadLibrary,而Windows上ctypes.CDLL、ctypes.cdll.LoadLibrary、ctypes.WinDLL、ctypes.windll.LoadLibrary都可以使用。但是一般我们都使用ctypes.CDLL即可,另外注意的是:dll或者so文件的路径最好是绝对路径,即便不是也要表明层级,比如我们这里的py文件和dll文件是在同一个目录下,但是我们加载的时候不可以写mmp.dll,这样会报错找不到,要写成./mmp.dll。2.加载动态链接库之后会返回一个对象,我们上面起名为lib,这个lib就是得到的动态链接库了。3.然后可以直接通过lib调用里面的函数,但是一般我们会使用反射的方式来获取,因为不知道函数到底存不存在,如果不存在直接调用会抛出异常,如果存在这个函数我们才会执行。
python类型与C语言类型之间的转换
我们知道可以使用ctypes调用动态链接库,主要是调用动态链接库中使用C编写好的函数,但这些函数肯定都是需要参数的,还有返回值,不然编写动态链接库有啥用呢。那么问题来了,不同的语言变量类型不同,所以python能够直接往C编写的函数中传参吗?显然不行,所以ctypes还提供了大量的类,帮我们将python中的类型转成C语言中的类型。
我们说了,python中类型不能直接往C语言的函数中传递(整型是个例外),那么ctypes就提供了很多的类可以帮助我们将python的类型转成C语言的类型。常见的类型分为以下几种:数值、字符、指针
数值类型转换
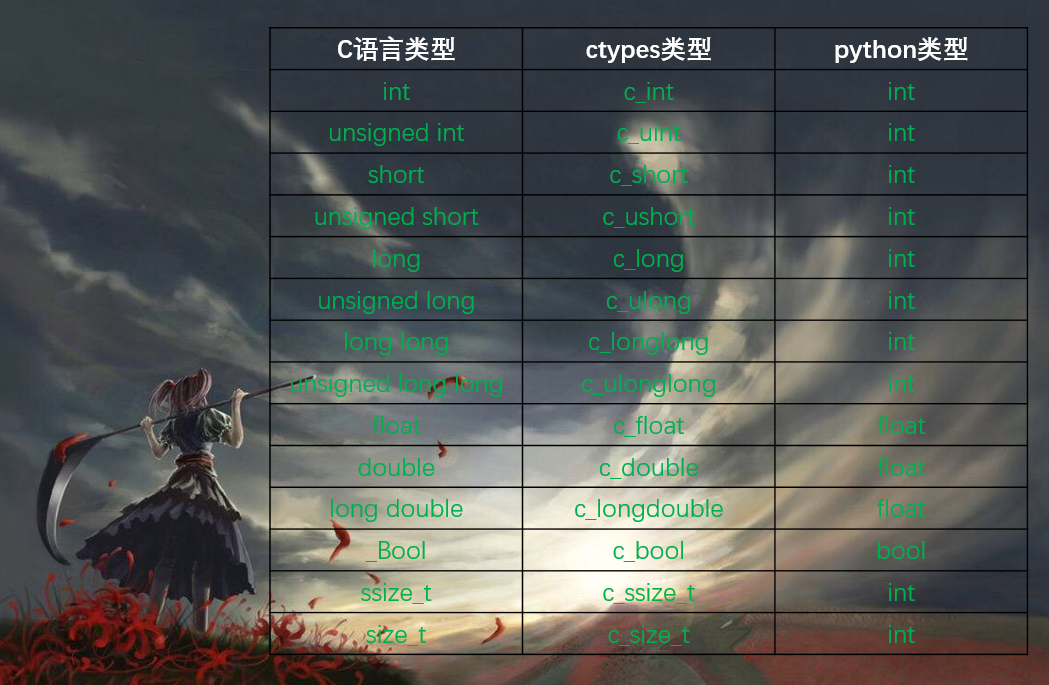
c语言的数值类型分为如下:
int:整型unsigned int:无符号整型short:短整型unsigned short:无符号短整型long:长整形unsigned long:无符号长整形long long:64位机器上等同于longunsigned long long:等同于unsigned longfloat:单精度浮点型double:双精度浮点型long double:看成是double即可_Bool:布尔类型ssize_t:等同于long或者long longsize_t:等同于unsigned long或者unsigned long long
import ctypes
# 下面都是ctypes中提供的类,将python中的对象传进去,就可以转换为C语言能够识别的类型
print(ctypes.c_int(1)) # c_long(1)
print(ctypes.c_uint(1)) # c_ulong(1)
print(ctypes.c_short(1)) # c_short(1)
print(ctypes.c_ushort(1)) # c_ushort(1)
print(ctypes.c_long(1)) # c_long(1)
print(ctypes.c_ulong(1)) # c_ulong(1)
# c_longlong等价于c_long,c_ulonglong等价于c_ulong
print(ctypes.c_longlong(1)) # c_longlong(1)
print(ctypes.c_ulonglong(1)) # c_ulonglong(1)
print(ctypes.c_float(1.1)) # c_float(1.100000023841858)
print(ctypes.c_double(1.1)) # c_double(1.1)
# 在64位机器上,c_longdouble等于c_double
print(ctypes.c_longdouble(1.1)) # c_double(1.1)
print(ctypes.c_bool(True)) # c_bool(True)
# 相当于c_longlong和c_ulonglong
print(ctypes.c_ssize_t(10)) # c_longlong(10)
print(ctypes.c_size_t(10)) # c_ulonglong(10)
字符类型转换
c语言的字符类型分为如下:
char:一个ascii字符或者-128~127的整型wchar:一个unicode字符unsigned char:一个ascii字符或者0~255的一个整型

import ctypes
# 必须传递一个ascii字符并且是字节,或者一个int,来代表c里面的字符
print(ctypes.c_char(b"a")) # c_char(b'a')
print(ctypes.c_char(97)) # c_char(b'a')
# 传递一个unicode字符,当然ascii字符也是可以的,并且不是字节形式
print(ctypes.c_wchar("憨")) # c_wchar('憨')
# 和c_char类似,但是c_char既可以传入字符、也可以传整型,而这里的c_byte则要求必须传递整型。
print(ctypes.c_byte(97)) # c_byte(97)
print(ctypes.c_ubyte(97)) # c_ubyte(97)
指针类型转换
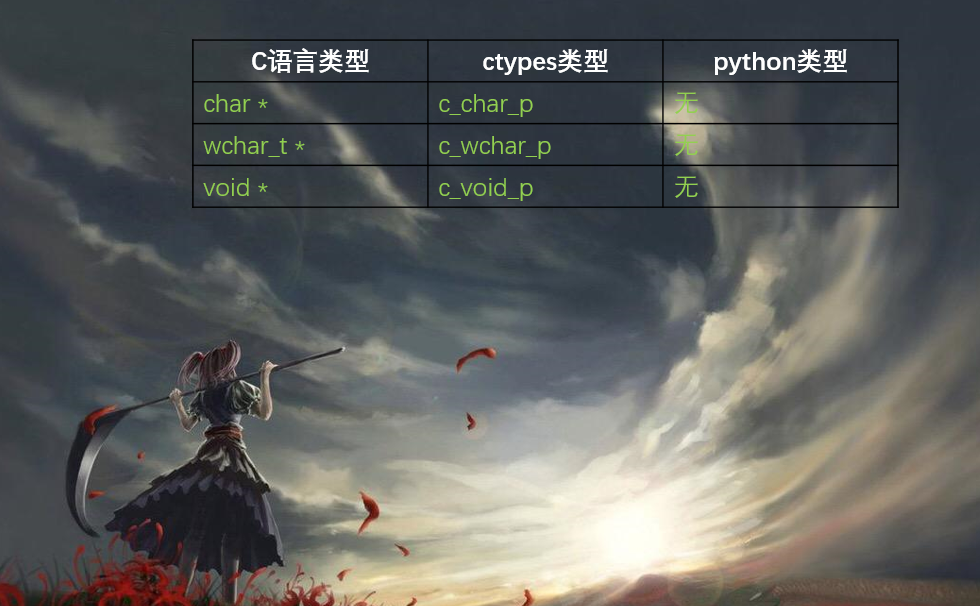
c语言的指针类型分为如下:
char *:字符指针wchar_t *:字符指针void *:空指针
import ctypes
# c_char_p就是c里面字符数组指针了
# char *s = "hello world";
# 那么这里面也要传递一个bytes类型的字符串,返回一个地址
print(ctypes.c_char_p(b"hello world")) # c_char_p(2082736374464)
# 直接传递一个unicode,同样返回一个地址
print(ctypes.c_wchar_p("憨八嘎~")) # c_wchar_p(2884583039392)
# ctypes.c_void_p后面演示
至于其他的类型,比如整型指针啊、数组啊、结构体啊、回调函数啊,ctypes都支持,我们后面会介绍。
参数传递
下面我们来看看如何传递参数。
#include <stdio.h>
void test(int a, float f, char *s)
{
printf("a = %d, b = %.2f, s = %s
", a, f, s);
}
这是一个很简单的C文件,然后编译成dll之后,让python去调用。这里我们编译之后的文件名叫做mmp.dll
import ctypes
from ctypes import *
lib = ctypes.CDLL("./mmp.dll")
try:
lib.test(1, 1.2, "hello world")
except Exception as e:
print(e) # argument 2: <class 'TypeError'>: Don't know how to convert parameter 2
# 我们看到一个问题,那就是报错了,告诉我们不知道如何转化第二个参数
# 正如我们之前说的,整型是会自动转化的,但是浮点型是不会自动转化的
# 因此我们需要使用ctypes来包装一下,当然还有整型,即便整型会自动转,我们还是建议手动转化一下
# 这里传入c_int(1)和1都是一样的,但是建议传入c_int(1)
lib.test(c_int(1), c_float(1.2), c_char_p(b"hello world")) # a = 1, b = 1.20, s = hello world
我们看到完美的打印出来了
我们再来试试布尔类型
#include <stdio.h>
void test(_Bool flag)
{
//布尔类型本质上是一个int
printf("a = %d
", flag);
}
import ctypes
from ctypes import *
lib = ctypes.CDLL("./mmp.dll")
lib.test(c_bool(True)) # a = 1
lib.test(c_bool(False)) # a = 0
# 可以看到True被解释成了1,False被解释成了0
# 我们说整型会自动转化,而布尔类型继承自整型所以布尔类型也可以直接传递
lib.test(True) # a = 1
lib.test(False) # a = 0
ctypes类型
关于ctypes转化之后的类型:
from ctypes import *
v = c_int(1)
# 我们看到c_int(1)它的类型就是ctypes.c_long
print(type(v)) # <class 'ctypes.c_long'>
# 当然你把c_int,c_long,c_longlong这些花里胡哨的都当成是整型就完事了
# 此外我们还能够拿到它的值,调用value方法
print(v.value, type(v.value)) # 1 <class 'int'>
v = c_char(b"a")
print(type(v)) # <class 'ctypes.c_char'>
print(v.value, type(v.value)) # b'a' <class 'bytes'>
v = c_char_p(b"hello world")
print(type(v)) # <class 'ctypes.c_char_p'>
print(v.value, type(v.value)) # b'hello world' <class 'bytes'>
调用value方法能够拿到对应python类型的值。
字符与字符数组的传递
来看一个稍微复杂点的例子:
#include <stdio.h>
#include <string.h>
void test(int age, char *gender)
{
if (age >= 18)
{
if (strcmp(gender, "female") == 0)
{
printf("社会人,合情合理
");
}
else
{
printf("抱歉,打扰了
");
}
}
else
{
if (strcmp(gender, "female") == 0)
{
printf("虽然担些风险,但也值得一试
");
}
else
{
printf("可爱的话也是没有问题的
");
}
}
}
import ctypes
from ctypes import *
lib = ctypes.CDLL("./mmp.dll")
lib.test(c_int(20), c_char_p(b"female")) # 社会人,合情合理
lib.test(c_int(20), c_char_p(b"male")) # 抱歉,打扰了
lib.test(c_int(14), c_char_p(b"female")) # 虽然担些风险,但也值得一试
lib.test(c_int(14), c_char_p(b"male")) # 可爱的话也是没有问题的
# 我们看到C中的字符数组,我们直接通过c_char_p来传递即可
# 至于单个字符,使用c_char即可。
然后看看unicode字符的传递,我们说char *传递的是ascii字符数组,如果想传入unicode的话需要使用wchar_t *。
#include <stdio.h>
#include <locale.h>
//当然里面可以定义多个函数
void test1(char a, char *b)
{
printf("a = %c, b = %s", a, b);
}
void test2(wchar_t a, wchar_t *b)
{
//打印宽字符需要引入一个头文件<locale.h>
setlocale(LC_ALL, "chs");
//wchar_t叫做宽字符,打印宽字符需要使用wprintf,占位符也要改成lc或者ls
//并且要改成L""的格式
wprintf(L"a = %lc, b = %ls", a, b);
}
import ctypes
from ctypes import *
lib = ctypes.CDLL("./mmp.dll")
lib.test1(c_char(b"a"), c_char_p(b"hello")) # a = a, b = hello
lib.test2(c_wchar("憨"), c_wchar_p("憨八嘎")) # a = 憨, b = 憨八嘎
# 当然我们说C中的char,还可以使用c_byte来传递,只不过接收的是对应的ascii码,不再是字符
lib.test1(c_byte(97), c_char_p(b"hello")) # a = a, b = hello
字符串的修改
我们知道C中不存在字符串这个概念,python中的字符串在C中也是通过字符数组来实现的。我们说在C中创建一个字符数组有两种方式:
char *s1 = "hello world";
char s2[] = "hello world";
这两种方式虽然打印的结果是一样的,并且s1、s2都指向了对应字符数组的首地址,但是内部的结构确是不同的。
1.char *s1 = "hello world";此时这个字符数组是存放在静态存储区里面的,程序编译的时候这块区域就已经确定好了,静态存储区在程序的整个运行期间都是存在的,主要用来存放一些静态变量、全局变量、常量。因此s1只能够访问这个字符数组,却不能够改变它,因为它是一个常量。而char s2[] = "hello world";,这种方式创建的字符数组是存放在栈当中的,可以通过s2这个指针去修改它。2.char *s1 = "hello world";是在编译的时候就已经确定了,因为是一个常量。而char s2[] = "hello world";则是在运行时才确定。3.char *s1 = "hello world";创建的字符数组存于静态存储区,char s2[] = "hello world";创建的字符数组存储于栈区,所以s1访问的速度没有s2快。
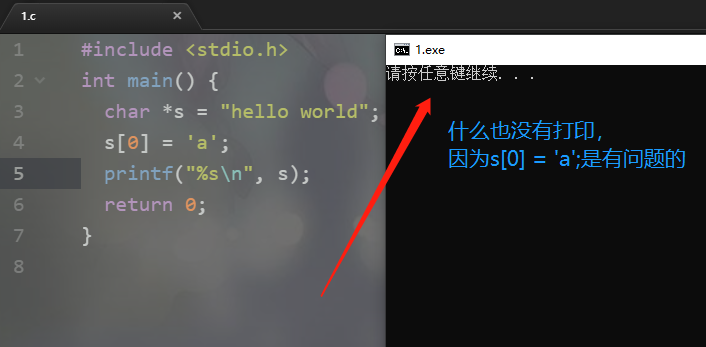
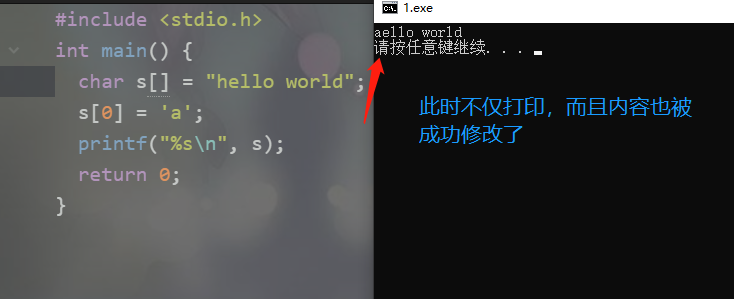
所以我们说char *s这种方式创建的字符数组在C中是不能修改的,但是我们通过ctypes却可以做到对char *s进行修改:
#include <stdio.h>
int test(char *s1, char s2[6])
{
//两种方式都进行修改
s1[0] = 'a';
s2[0] = 'a';
printf("s1 = %s, s2 = %s
", s1, s2);
}
我们还是将C文件编译成mmp.dll
import ctypes
from ctypes import *
lib = ctypes.CDLL("./mmp.dll")
# 我们看到无论是char *s1,还是char s2[...],我们都可以使用c_char_p这种方式传递
lib.test(c_char_p(b"hello"), c_char_p(b"hello")) # s1 = aello, s2 = aello
我们看到两种方式都成功修改了,但是即便能修改,我们不建议这么做。不是说不让修改,而是应该换一种方式。如果是需要修改的话,那么不要使用c_char_p的方式来传递,而是建议通过create_string_buffer来给C语言传递可以修改字符的空间。
create_string_buffer
create_string_buffer是ctypes提供的一个函数,表示创建具有一定大小的字符缓存,就理解为字符数组即可。
from ctypes import *
# 传入一个int,表示创建一个具有固定大小的字符缓存,这里是10个
s = create_string_buffer(10)
# 直接打印就是一个对象
print(s) # <ctypes.c_char_Array_10 object at 0x000001E2E07667C0>
# 也可以调用value方法打印它的值,可以看到什么都没有
print(s.value) # b''
# 并且它还有一个raw方法,表示C语言中的字符数组,由于长度为10,并且没有内容,所以全部是x00,就是C语言中的�
print(s.raw) # b'x00x00x00x00x00x00x00x00x00x00'
# 还可以查看长度
print(len(s)) # 10
当然create_string_buffer如果只传一个int,那么表示创建对应长度的字符缓存。除此之外,还可以指定字节串,此时的字符缓存大小和指定的字节串大小是一致的:
from ctypes import *
# 此时我们直接创建了一个字符缓存
s = create_string_buffer(b"hello")
print(s) # <ctypes.c_char_Array_6 object at 0x0000021944E467C0>
print(s.value) # b'hello'
# 我们知道在C中,字符数组是以�作为结束标记的,所以结尾会有一个�,因为raw表示C中的字符数组
print(s.raw) # b'hellox00'
# 长度为6,b"hello"五个字符再加上�一共6个
print(len(s))
当然create_string_buffer还可以指定字节串的同时,指定空间大小。
from ctypes import *
# 此时我们直接创建了一个字符缓存,如果不指定容量,那么默认和对应的字符数组大小一致
# 但是我们还可以同时指定容量,记得容量要比前面的字节串的长度要大。
s = create_string_buffer(b"hello", 10)
print(s) # <ctypes.c_char_Array_10 object at 0x0000019361C067C0>
print(s.value) # b'hello'
# 长度为10,剩余的5个显然是�
print(s.raw) # b'hellox00x00x00x00x00'
print(len(s)) # 10
下面我们来看看如何使用create_string_buffer来传递:
#include <stdio.h>
int test(char *s)
{
//变量的形式依旧是char *s
//下面的操作就是相当于把字符数组的索引为5到11的部分换成" satori"
s[5] = ' ';
s[6] = 's';
s[7] = 'a';
s[8] = 't';
s[9] = 'o';
s[10] = 'r';
s[11] = 'i';
printf("s = %s
", s);
}
from ctypes import *
lib = CDLL("./mmp.dll")
s = create_string_buffer(b"hello", 20)
lib.test(s) # s = hello satori
此时就成功地修改了,我们这里的b"hello"占五个字节,下一个正好是索引为5的地方,然后把索引为5到11的部分换成对应的字符。但是需要注意的是,一定要小心�,我们知道C语言中一旦遇到了�就表示这个字符数组结束了。
from ctypes import *
lib = CDLL("./mmp.dll")
# 这里把"hello"换成"hell",看看会发生什么
s = create_string_buffer(b"hell", 20)
lib.test(s) # s = hell
# 我们看到这里只打印了"hell",这是为什么?
# 我们看一下这个s
print(s.raw) # b'hellx00 satorix00x00x00x00x00x00x00x00'
# 我们看到这个create_string_buffer返回的对象是可变的,在将s传进去之后被修改了
# 如果没有传递的话,我们知道它是长这样的。
"""
b'hellx00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00'
hell的后面全部是C语言中的�
修改之后变成了这样
b'hellx00 satorix00x00x00x00x00x00x00x00'
我们看到确实是把索引为5到11(包含11)的部分变成了"satori"
但是我们知道C语言中扫描字符数组的时候一旦遇到了�,就表示结束了,而hell后面就是�,
因为即便后面还有内容也不会输出了,所以直接就只打印了hell
"""
另外除了create_string_buffer之外,还有一个create_unicode_buffer,针对于wchar_t,用法和create_string_buffer一样。
C语言中查看字符数组的长度
C语言中如何查看字符数组的长度呢?有两种方法,一种是通过sizeof,一种是通过strlen。话说我说这个干什么?算了,不管了。
#include <stdio.h>
#include <string.h>
int main() {
char s[] = "hello world";
//C语言中查看字符串的长度可以使用strlen,这个需要导入string.h头文件。strlen计算的就是字符的个数,不包括�
//使用sizeof计算的结果是包含�的,所以会比strlen计算的结果多1
printf("%d %d
", strlen(s), sizeof(s) / sizeof(s[0])); // 11 12
return 0;
}
但是我们发现字符数组的创建方式是通过char s[]这种形式,如果是char *s呢?
#include <stdio.h>
#include <string.h>
int main() {
char *s = "hello world";
printf("%d %d
", strlen(s), sizeof(s) / sizeof(s[0])); // 11 8
return 0;
}
我们看到使用strlen计算的结果是一样的,但是使用sizeof得到的结果却是不一样的。因为char *s,这个s我们虽然可以使用它来打印字符数组,但它本质上是一个指针,一个指针在64位机器上占8个字节,所以结果是8。而char s[]中的s虽然也指向字符数组的首地址,但它本质上是一个数组名,我们使用sizeof查看得到的结果还是字符数组中所有元素的总大小。
艾玛,你扯到C上面干啥。。。。。。你又不会C。。。。。。

调用操作系统的库函数
我们知道python解释器本质上就是使用C语言写出来的一个软件,那么操作系统呢?操作系统本质上它也是一个软件,不管是Windows、linux、macOS都自带了大量的共享库,那么我们就可以使用python去调用。
from ctypes import *
import platform
# 判断当前的操作系统平台。
# Windows平台返回"Windows",linux平台返回"Linux",macOS平台返回"Darwin"
system = platform.system()
# 不同的平台共享库不同
if system == "Windows":
libc = cdll.msvcrt
elif system == "Linux":
libc = CDLL("libc.so.6")
elif system == "Darwin":
libc = CDLL("libc.dylib")
else:
print("不支持的平台,程序结束")
import sys
sys.exit(0)
# 调用对应的函数,比如printf,注意里面需要传入字节
libc.printf(b"my name is %s, age is %d
", b"van", 37) # my name is van, age is 37
# 如果包含汉字就不能使用b""这种形式了,因为这种形式只适用于ascii字符,我们需要手动encode成utf-8
libc.printf("姓名: %s, 年龄: %d
".encode("utf-8"), "古明地觉".encode("utf-8"), 17) # 姓名: 古明地觉, 年龄: 17
我们上面是在Windows上调用的,这段代码即便拿到linux上也可以正常执行。

至于Mac,我这里没有Mac,就不演示了。

当然这里面还支持其他的函数,我们这里以Windows为例:
from ctypes import *
libc = cdll.msvcrt
# 创建一个大小为10的buffer
s = create_string_buffer(10)
# strcpy表示将字符串进行拷贝
libc.strcpy(s, c_char_p(b"hello satori"))
# 由于buffer只有10个字节大小,所以无法完全拷贝
print(s.value) # b'hello sato'
# 创建unicode buffer
s = create_unicode_buffer(10)
libc.strcpy(s, c_wchar_p("我也觉得很变态啊"))
print(s.value) # 我也觉得很变态啊
# 比如puts函数
libc.puts(b"hello world") # hello world
Windows系统的其他函数
对于Windows来说,我们还可以调用一些其它的函数,但是不再是通过cdll.msvcrt这种方式了。在Windows上面有一个user32这么个东西,我们来看一下:
from ctypes import *
# 我们通过cdll.user32本质上还是加载了Windows上的一个共享库
# 这个库给我们提供了很多方便的功能
win = cdll.user32
# 比如查看屏幕的分辨率
print(win.GetSystemMetrics(0)) # 1920
print(win.GetSystemMetrics(1)) # 1080
我们还可以用它来打开MessageBoxA:
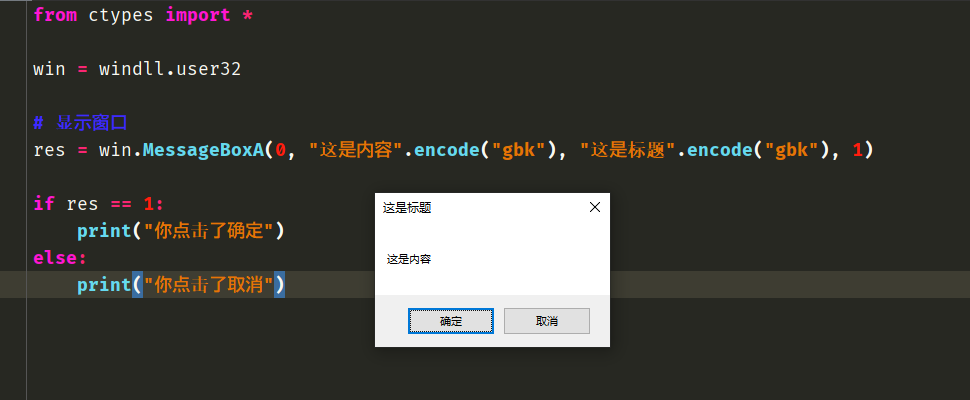
可以看到我们通过windll.user32就可以很轻松地调用Windows的api,具体有哪些api可以去网上查找,搜索win32 api
关于Windows的其它模块
除了ctypes,还有几个专门用来操作win32服务的模块,win32gui、win32con、win32api、win32com、win32process。直接pip install pywin32即可,或者pip install pypiwin32。
显示窗体和隐藏窗体
import win32gui
import win32con
# 首先查找窗体,这里查找qq。需要传入 窗口类名 窗口标题名,至于这个怎么获取可以使用spy工具查看
qq = win32gui.FindWindow("TXGuifoundation", "QQ")
# 然后让窗体显示出来
win32gui.ShowWindow(qq, win32con.SW_SHOW)
# 还可以隐藏
win32gui.ShowWindow(qq, win32con.SW_HIDE)
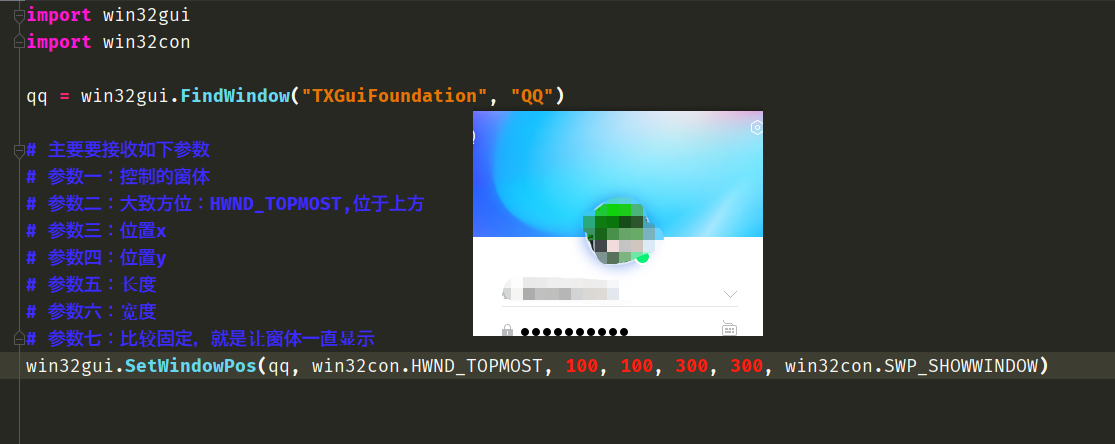
控制窗体的位置和大小
import win32gui
import win32con
qq = win32gui.FindWindow("TXGuiFoundation", "QQ")
# 主要要接收如下参数
# 参数一:控制的窗体
# 参数二:大致方位:HWND_TOPMOST,位于上方
# 参数三:位置x
# 参数四:位置y
# 参数五:长度
# 参数六:宽度
# 参数七:比较固定,就是让窗体一直显示
win32gui.SetWindowPos(qq, win32con.HWND_TOPMOST, 100, 100, 300, 300, win32con.SWP_SHOWWINDOW)
那么我们还可以让窗体满屏幕乱跑
import win32gui
import win32con
import random
qqWin = win32gui.FindWindow("TXGuiFoundation", "QQ")
# 将位置变成随机数
while True:
x = random.randint(1, 800)
y = random.randint(1, 400)
win32gui.SetWindowPos(qqWin, win32con.HWND_TOPMOST, x, y, 300, 300, win32con.SWP_SHOWWINDOW)
语音播放
import win32com.client
# 直接调用操作系统的语音接口
speaker = win32com.client.Dispatch("SAPI.SpVoice")
# 输入你想要说的话,前提是操作系统语音助手要认识。一般中文和英文是没有问题的
speaker.Speak("他能秒我,他能秒杀我?他要是能把我秒了,我当场······")
python中win32模块的api非常多,几乎可以操作整个windows提供的服务,win32模块就是相当于把Windows服务封装成了一个一个的接口。不过这些服务、或者调用这些服务具体都能干些什么,可以自己去研究,这里就到此为止了。毕竟本来是介绍python和静态语言之间的结合的,所以感觉这一篇文章似乎有点多余,但是多了解点总归是好的。

ctypes获取返回值
我们前面已经看到了,通过ctypes向动态链接库中的函数传参时是没有问题的,但是我们如何拿到返回值呢?我们之前都是使用printf直接打印的,但是这样显然不行,我们肯定是要拿到返回值去做一些别的事情的。那么我们看看如何使用ctypes获取函数的返回值。
获取整型返回值
int test1(int a, int b)
{
int c;
c = a + b;
return c;
}
void test2()
{
}
我们定义了两个函数,下面编译成dll文件,dll文件名叫做mmp.dll
from ctypes import *
lib = CDLL("./mmp.dll")
print(lib.test1(25, 33)) # 58
print(lib.test2()) # 125387149
我们看到对于test1的结果是正常的,但是对于test2来说即便返回的是void,在python中依旧会得到一个整型,但是这个结果肯定是不正确的。不过对于整型来说,是完全没有问题的。
当然我们后面还会遇到一个问题,这里提前说一下。动态链接库中的函数不要说返回void,即便返回一个char *,那么在python中得到的依旧是一个整型。这个是不同语言的类型不同造成的,正如我们传递参数一样,需要使用ctypes转化一下,那么在获取返回值的时候,也需要提前使用ctypes指定一下返回值到底是什么类型,只有这样才能拿到动态链接库中函数的正确的返回值。
获取字符数组返回值
#include <wchar.h>
char * test1()
{
char *s = "hello satori";
return s;
}
wchar_t * test2()
{
//遇到wchar_t的时候,一定要导入wchar.h头文件
wchar_t *s = L"憨八嘎";
return s;
}
我们定义了两个函数,一个返回char *,一个返回wchar_t *。
from ctypes import *
lib = CDLL("./mmp.dll")
# 我们看到神奇的事情发生了,我们在动态链接库中返回的是一个字符数组的首地址,我们希望拿到指向的字符串
# 然而python拿到的确是一个整型,而且一看感觉这像是一个地址。如果是地址的话那么从理论上讲是对的,返回地址、获取地址
print(lib.test1()) # 1801207808
# 但我们希望的是获取地址指向的字符数组,所以我们需要指定一下返回的类型
# 指定为c_char_p,告诉ctypes我们不要地址,而是要通过这个地址获取其指向的字符数组
lib.test1.restype = c_char_p
# 此时就没有问题了
print(lib.test1()) # b'hello satori'
# 同理对于unicode也是一样的,如果不指定类型,得到的依旧是一个整型
lib.test2.restype = c_wchar_p
print(lib.test2()) # 憨八嘎
因此我们就将python中的类型和C语言中的类型通过ctypes关联起来了,我们传参的时候需要转化,同理获取返回值的时候也要使用ctypes来声明一下类型。因为默认python调用动态链接库的函数返回的都是整型,至于返回的整型的值到底是什么?从哪里来的?我们不需要关心,你可以理解为地址、或者某块内存的脏数据,但是不管怎么样,结果肯定是不正确的(如果函数返回的就是整形除外)。因此我们需要提前声明一下返回值的类型。声明方式:
lib.CFunction.restype = ctypes类型
我们说lib就是ctypes调用dll或者so得到的动态链接库,而里面的函数就相当于是一个个的CFunction,然后设置内部的restype(返回值类型),就可以得到正确的返回值了。另外即便返回值设置的不对,比如:test1返回一个char *,但是我们将类型设置为c_float,调用的时候也不会报错而且得到的也是一个float,但是这个结果肯定是不对的。
from ctypes import *
lib = CDLL("./mmp.dll")
lib.test1.restype = c_char_p
print(lib.test1()) # b'hello satori'
# 设置为c_float
lib.test1.restype = c_float
# 获取了不知道从哪里来的脏数据
print(lib.test1()) # 2.5420596244190436e+20
# 另外ctypes调用还有一个特点
lib.test2.restype = c_wchar_p
print(lib.test2(123, c_float(1.35), c_wchar_p("呼呼呼"))) # 憨八嘎
# 我们看到test2是不需要参数的,如果我们传了那么就会忽略掉,依旧能得到正常的返回值
# 但是不要这么做,因为没准就出问题了,所以还是该传几个参数就传几个参数
获取浮点型返回值
下面我们来看看浮点类型的返回值怎么获取,当然方法和上面是一样的。
#include <math.h>
float test1(int a, int b)
{
float c;
c = sqrt(a * a + b * b);
return c;
}
from ctypes import *
lib = CDLL("./mmp.dll")
# 得到的结果是一个整型,默认都是整型。
# 我们不知道这个整型是从哪里来的,就把它理解为地址吧,但是不管咋样,结果肯定是不对的
print(lib.test1(3, 4)) # 1084227584
# 我们需要指定返回值的类型,告诉ctypes返回的是一个float
lib.test1.restype = c_float
# 此时结果就是对的
print(lib.test1(3, 4)) # 5.0
# 如果指定为double呢?
lib.test1.restype = c_double
# 得到的结果也有问题,总之类型一定要匹配
print(lib.test1(3, 4)) # 5.356796015e-315
# 至于int就不用说了,因为默认就是int。所以和第一个结果是一样的
lib.test1.restype = c_int
print(lib.test1(3, 4)) # 1084227584
所以类型一定要匹配,该是什么类型就是什么类型。即便动态链接库中返回的是float,我们在python中通过ctypes也要指定为float,而不是指定为double,尽管都是浮点数并且double的精度还更高,但是结果依旧不是正确的。至于整型就不需要关心了,但即便如此,int、long也不要混用,而且也建议传参的时候进行转化。

ctypes给动态链接库中的函数传递指针
我们使用ctypes可以创建一个字符数组并且拿到首地址,但是对于整型、浮点型我们怎么创建指针呢?下面就来揭晓。另外,一旦涉及到指针操作的时候就要小心了,因为这往往是比较危险的,所以python、java等语言把指针给隐藏掉了,当然不是说没有指针,肯定是有指针的。只不过操作指针的权限没有暴露给程序员,能够操作指针的只有对应的解释器。
ctypes.byref和ctypes.pointer创建指针
from ctypes import *
v = c_int(123)
# 我们知道可以通过value属性获取相应的值
print(v.value)
# 但是我们还可以修改
v.value = 456
print(v) # c_long(456)
s = create_string_buffer(b"hello")
s[3] = b'>'
print(s.value) # b'hel>o'
# 如何创建指针呢?通过byref和pointer
v2 = c_int(123)
print(byref(v2)) # <cparam 'P' (000001D9DCF86888)>
print(pointer(v2)) # <__main__.LP_c_long object at 0x000001D9DCF868C0>
我们看到byref和pointer都可以创建指针,那么这两者有什么区别呢?byref返回的指针相当于右值,而pointer返回的指针相当于左值。举个栗子:
//以整型的指针为例:
int num = 123;
int *p = &num
对于上面的例子,如果是byref,那么结果相当于&num,拿到的就是一个具体的值。如果是pointer,那么结果相当于p。这两者在传递的时候是没有区别的,只是对于pointer来说,它返回的是一个左值,我们是可以继续拿来做文章的。
from ctypes import *
n = c_int(123)
# 拿到变量n的指针
p1 = byref(n)
p2 = pointer(n)
# pointer返回的是左值,我们可以继续做文章,比如继续获取指针,此时获取的就是p2的指针
print(byref(p2)) # <cparam 'P' (0000023953796888)>
# 但是p1不行,因为byref返回的是一个右值
try:
print(byref(p1))
except Exception as e:
print(e) # byref() argument must be a ctypes instance, not 'CArgObject'
因此两者的区别就在这里,但是还是那句话,我们在传递的时候是无所谓的,传递哪一个都可以
传递指针
我们知道了可以通过ctypes.byref、ctypes.pointer的方式传递指针,但是如果函数返回的也是指针呢?我们知道除了返回int之外,都要指定返回值类型,那么指针如何指定呢?答案是通过ctypes.POINTER。
//接收两个float *,返回一个float *
float *test1(float *a, float *b)
{
static float c;
c = *a + *b;
return &c;
}
from ctypes import *
lib = CDLL("./mmp.dll")
# 声明一下,返回的类型是一个POINTER(c_float),也就是float的指针类型
lib.test1.restype = POINTER(c_float)
# 别忘了传递指针,因为函数接收的是指针,两种传递方式都可以
res = lib.test1(byref(c_float(3.14)), pointer(c_float(5.21)))
print(res) # <__main__.LP_c_float object at 0x000001FFF1F468C0>
print(type(res)) # <class '__main__.LP_c_float'>
# 我们可以调用contents方法拿到对应的值,这个值是ctypes类型,那么显然就还可以在基础上再调用value方法拿到python中的值
print(res.contents) # c_float(8.350000381469727)
print(res.contents.value) # 8.350000381469727
因此我们看到了如果返回的是指针类型可以使用POINTER(类型)来声明。也就是说POINTER是用来声明指针类型的,而byref、pointer则是用来获取指针的。另外我们调用动态链接库中的函数返回的是一个指针类型的话,那么返回的类型就是一个pointer返回值对应的类型。
from ctypes import *
lib = CDLL("./mmp.dll")
lib.test1.restype = POINTER(c_float)
print(type(lib.test1(byref(c_float(1.1)), byref(c_float(2.2))))) # <class '__main__.LP_c_float'>
# 返回的类型,和调用pointer函数返回结果是同一个类型
print(type(pointer(c_float(1.1)))) # <class '__main__.LP_c_float'>
声明类型
我们知道可以事先声明返回值的类型,这样才能拿到正确的返回值。而我们传递的时候,直接传递正确的类型即可,但是其实也是可以事先声明的。
from ctypes import *
lib = CDLL("./mmp.dll")
# 通过argtypes,我们可以事先指定需要传入两个float的指针类型
lib.test1.argtypes = (POINTER(c_float), POINTER(c_float))
lib.test1.restype = POINTER(c_float)
# 但是和restype不同,argtypes实际上是可以不要的
# 因为返回的默认是一个整型,我们才需要通过restype事先声明返回值的类型,这是有必要的
# 但是对于argtypes来说,我们传参的时候已经直接指定类型了,所以argtypes即便没有也是可以的
# 所以argtypes的作用就类似于其他静态语言中的类型声明,先把类型定好,如果你传的类型不对,直接给你报错
try:
# 这里第二个参数传c_int
res = lib.test1(byref(c_float(3.21)), c_int(123))
except Exception as e:
# 所以直接就给你报错了
print(e) # argument 2: <class 'TypeError'>: expected LP_c_float instance instead of c_long
# 此时正确执行
res1 = lib.test1(byref(c_float(3.21)), byref(c_float(666)))
print(res1.contents.value) # 669.2100219726562

传递数组
下面我们来看看如何使用ctypes传递数组,这里我们只讲传递,不讲返回。因为C语言返回数组给python实际上会存在很多问题,比如:返回的数组的内存由谁来管理,不用了之后空间由谁来释放,事实上ctypes内部对于返回数组支持的也不是很好。因此我们一般不会向python返回一个C语言中的数组,因为C语言中的数组传递给python涉及到效率的问题,python中的列表传递直接传递一个引用即可,但是C语言中的数组过来肯定是要拷贝一份的,所以这里我们只讲python如何通过ctypes给动态链接库传递数组,不会介绍动态链接库如何返回数组给python。
如何传递
我们知道python中没有数组,或者说C中的数组在python中是一个list,我们可以通过list来得到数组,方式也很简单。
from ctypes import *
# 创建一个数组,假设叫[1, 2, 3, 4, 5]
a5 = (c_int * 5)(1, 2, 3, 4, 5)
print(a5) # <__main__.c_long_Array_5 object at 0x00000162428968C0>
# 上面这种方式就得到了一个数组
# 当然还可以使用list
a5 = (c_int * 5)(*range(1, 6))
print(a5) # <__main__.c_long_Array_5 object at 0x0000016242896940>
下面演示一下。
//字符数组默认是以�作为结束的,我们可以通过strlen来计算长度。
//但是对于整型的数组来说我们不知道有多长
//因此有两种声明参数的方式,一种是int a[n],指定数组的长度
//另一种是通过指定int *a的同时,再指定一个参数int size,调用函数的时候告诉函数这个数组有多长
int test1(int a[5])
{
//可能有人会问了,难道不能通过sizeof计算吗?答案是不能,无论是int *a还是int a[n]
//当它作为函数的参数,我们调用的时候,传递的都是指针,指针在64位机器上默认占8个字节。
//所以int a[] = {...}这种形式,如果直接在当前函数中计算的话,那么sizeof(a)就是数组里面所有元素的总大小,因为a是一个数组名
//但是当把a传递给一个函数的时候,那么等价于将a的首地址拷贝一份传过去,此时在新的函数中再计算sizeof(a)的时候就是一个指针的大小
//至于int *a这种声明方式,不管在什么地方,sizeof(a)则都是一个指针的大小
int i;
int sum = 0;
a[3] = 10;
a[4] = 20;
for (i = 0;i < 5; i++){
sum += a[i];
}
return sum;
}
from ctypes import *
lib = CDLL("./mmp.dll")
# 创建5个元素的数组,但是只给3个元素
arr = (c_int * 5)(1, 2, 3)
# 在动态链接库中,设置剩余两个元素
# 所以如果没问题的话,结果应该是1 + 2 + 3 + 10 + 20
print(lib.test1(arr)) # 36
传递结构体
定义一个结构体
有了前面的数据结构还不够,我们还要看看结构体是如何传递的,有了结构体的传递,我们就能发挥更强大的功能。那么我们来看看如何使用ctypes定义一个结构体:
from ctypes import *
# 对于这样一个结构体应该如何定义呢?
"""
struct Girl {
//姓名
char *name;
//年龄
int age;
//性别
char *gender;
//班级
int class;
};
"""
# 定义一个类,必须继承自ctypes.Structure
class Girl(Structure):
# 创建一个_fields_变量,必须是这个名字,注意开始和结尾都只有一个下划线
# 然后就可以写结构体的字段了,具体怎么写估计一看就清晰了
_fields_ = [
("name", c_char_p),
("age", c_int),
("gender", c_char_p),
("class", c_int)
]
如何传递
我们向C中传递一个结构体,然后再返回:
struct Girl {
char *name;
int age;
char *gender;
int class;
};
//接收一个结构体,返回一个结构体
struct Girl test1(struct Girl g){
g.name = "古明地觉";
g.age = 17;
g.gender = "female";
g.class = 2;
return g;
}
from ctypes import *
lib = CDLL("./mmp.dll")
class Girl(Structure):
_fields_ = [
("name", c_char_p),
("age", c_int),
("gender", c_char_p),
("class", c_int)
]
# 此时返回值类型就是一个Girl类型,另外我们这里的类型和C中结构体的名字不一样也是可以的
lib.test1.restype = Girl
# 传入一个实例,拿到返回值
g = Girl()
res = lib.test1(g)
print(res, type(res)) # <__main__.Girl object at 0x0000015423A06840> <class '__main__.Girl'>
print(res.name, str(res.name, encoding="utf-8")) # b'xe5x8fxa4xe6x98x8exe5x9cxb0xe8xa7x89' 古明地觉
print(res.age) # 17
print(res.gender) # b'female'
print(getattr(res, "class")) # 2
如果是结构体指针呢?
struct Girl {
char *name;
int age;
char *gender;
int class;
};
//接收一个指针,返回一个指针
struct Girl *test1(struct Girl *g){
g -> name = "mashiro";
g -> age = 17;
g -> gender = "female";
g -> class = 2;
return g;
}
from ctypes import *
lib = CDLL("./mmp.dll")
class Girl(Structure):
_fields_ = [
("name", c_char_p),
("age", c_int),
("gender", c_char_p),
("class", c_int)
]
# 此时指定为Girl类型的指针
lib.test1.restype = POINTER(Girl)
# 传入一个实例,拿到返回值
# 如果lib.test1.restype指定的类型不是结构体指针,那么函数返回的就是该结构体(Girl)实例
# 但返回的是指针,我们还需要手动调用一个contents才可以拿到对应的值。
g = Girl()
res = lib.test1(byref(g))
print(str(res.contents.name, encoding="utf-8")) # mashiro
print(res.contents.age) # 16
print(res.contents.gender) # b'female'
print(getattr(res.contents, "class")) # 3
# 另外我们不仅可以通过返回的res去调用,因为我们传递的是g的指针
# 修改指针指向的内存就相当于修改g
# 所以我们通过g来调用也是可以的
print(str(g.name, encoding="utf-8")) # mashiro
因此对于结构体来说,我们先创建一个结构体(Girl)实例g,如果动态链接库的函数中接收的是结构体,那么直接把g传进去等价于将g拷贝了一份,此时函数中进行任何修改都不会影响原来的g。但如果函数中接收的是结构体指针,我们传入byref(g)相当于把g的指针拷贝了一份,在函数中修改是会影响g的。而返回的res也是一个指针,所以我们除了通过res.contents来获取结构体中的值之外,还可以通过g来获取。再举个栗子对比一下:
struct Num {
int x;
int y;
};
struct Num test1(struct Num n){
n.x += 1;
n.y += 1;
return n;
}
struct Num *test2(struct Num *n){
n->x += 1;
n->y += 1;
return n;
}
from ctypes import *
lib = CDLL("./mmp.dll")
class Num(Structure):
_fields_ = [
("x", c_int),
("y", c_int),
]
# 我们在创建的时候是可以传递参数的
num = Num(x=1, y=2)
print(num.x, num.y) # 1 2
lib.test1.restype = Num
res = lib.test1(num)
# 我们看到通过res得到的结果是修改之后的值
# 但是对于num来说没有变
print(res.x, res.y) # 2 3
print(num.x, num.y) # 1 2
"""
因为我们将num传进去之后,相当于将num拷贝了一份。
函数里面的结构体和这里的num尽管长得一样,但是没有任何关系,自增1之后返回交给res。
所以res获取的结果是自增之后的结果,但是num还是之前的num
"""
# 我们来试试传递指针,将byref(num)再传进去
lib.test2.restype = POINTER(Num)
res = lib.test2(byref(num))
print(num.x, num.y) # 2 3
"""
我们看到将指针传进去之后,相当于把num的指针拷贝了一份。
然后在函数中修改,相当于修改指针指向的内存,所以是会影响外面的num的
而动态链接库的函数中返回的是参数中的结构体指针,而我们传递的byref(num)也是这里的num的指针
尽管传递指针的时候也是拷贝了一份,两个指针本身来说虽然也没有任何联系,但是它们存储的地址是一样的
那么通过res.contents获取到的内容就相当于是这里的num
因此此时我们通过res.contents获取和通过num来获取都是一样的。
"""
print(res.contents.x, res.contents.y) # 2 3
# 另外还需要注意的一点就是:如果传递的是指针,一定要先创建一个变量
# 比如这里,一定是:先要num = Num(),然后再byref(num)。不可以直接就byref(Num())
# 原因很简单,因为Num()这种形式在创建完Num实例之后就销毁了,因为没有变量保存它,那么此时再修改指针指向的内存就会有问题,因为内存的值已经被回收了
# 如果不是指针,那么可以直接传递Num(),因为拷贝了一份
传递结构体数组
我们来一个难度高的,其实也不难,我们可以传递一个结构体数组。
#include <stdio.h>
typedef struct {
char *name;
int age;
char *gender;
}Girl;
void print_info(Girl *g, int size)
{
int i;
for (i=0;i<size;i++){
printf("%s %d %s
", g[i].name, g[i].age, g[i].gender);
}
}
from ctypes import *
lib = CDLL("./mmp.dll")
class Girl(Structure):
_fields_ = [
("name", c_char_p),
("age", c_int),
("gender", c_char_p),
]
g1, g2, g3 = Girl(c_char_p(b"mashiro"), 16, c_char_p(b"female")),
Girl(c_char_p(b"satori"), 17, c_char_p(b"female")),
Girl(c_char_p(b"koishi"), 16, c_char_p(b"female"))
g = (Girl * 3)(*[g1, g2, g3])
# 指定返回值类型
lib.print_info.restype = (Girl * 3)
lib.print_info(g, 3)
"""
mashiro 16 female
satori 17 female
koishi 16 female
"""
因此我们发现对于数组结构体的传递也是很简单的

回调函数
什么是回调函数我就不介绍了,我们先来看看C语言中如何使用回调函数。
函数指针
不过在看回调函数之前,我们先看看如何把一个函数赋值给一个变量。准确的说,是让一个指针指向一个函数,这个指针叫做函数指针。通常我们说的指针变量是指向一个整型、字符型或数组等变量,而函数指针是指向函数。函数指针可以像一般函数一样,用于调用函数、传递参数。
#include <stdio.h>
int add(int a, int b){
int c;
c = a + b;
return c;
}
int main(int argc, char const *argv[]) {
//创建一个指针变量p,让p等于指向add
//我们看到就类似声明函数一样,指定返回值类型和变量类型即可
//但是注意的是,中间一定是*p,不是p,因为这是一个函数指针,所以要有*
int (*p)(int, int) = add;
printf("1 + 3 = %d
", p(1, 3)); //1 + 3 = 4
return 0;
}
除此之外我们还以使用typedef
#include <stdio.h>
int add(int a, int b){
int c;
c = a + b;
return c;
}
//相当于创建了一个类型,名字叫做func。这个func表示的是一个函数指针类型
typedef int (*func)(int, int);
int main(int argc, char const *argv[]) {
//声明一个func类型的函数指针p,指向add函数
func p = add;
printf("2 + 3 = %d
", p(2, 3)); //2 + 3 = 5
return 0;
}
使用回调函数
下面来看看如何使用回调函数,说白了就是把一个函数指针作为函数的参数
#include <stdio.h>
char *evaluate(int score){
if (score < 60 && score >= 0){
return "不及格";
}else if (score < 80){
return "及格";
}else if (score < 90){
return "不错";
}else if (score <=100){
return "真棒";
}else {
return "无效的成绩";
}
}
//接收一个整型和一个函数,函数接收一个整型返回char *
char *execute1(int score, char *(*f)(int)){
return f(score);
}
//除了上面那种方式,我们还可以跟之前一样通过typedef
typedef char *(*func)(int);
//这样声明也是可以的。
char *execute2(int score, func f){
return f(score);
}
int main(int argc, char const *argv[]) {
printf("%s
", execute1(88, evaluate)); //不错
printf("%s
", execute2(70, evaluate)); //及格
}
python向C语言传递回调函数
我们知道了在C中传入一个函数,那么在python中如何定义一个C语言可以识别的函数呢?毫无疑问,类似于结构体,我们肯定是要先定义一个python的函数,然后再把python的函数转化成C语言可以识别的函数。
int add(int a, int b, int (*f)(int *, int *)){
return f(&a, &b);
}
我们就以这个函数为例,add函数返回一个int,接收两个int,和一个函数指针,那么我们如何在python中定义这样的函数并传递呢?我们来看一下,不过我们记得要编译成动态链接库:gcc -o dll或者so -shared c源文件,这里编译成mmp.dll
from ctypes import *
lib = CDLL("./mmp.dll")
# 动态链接库中的函数接收的函数的参数是两个int *,所以我们这里的a和b也是一个pointer
def add(a, b):
return a.contents.value + b.contents.value
# 此时我们把C中的函数用python表达了,但是这样肯定是不可能直接传递的,能传就见鬼了
# 那我们要如何转化呢?
# 可以通过ctypes里面的函数CFUNCTYPE转化一下,这个函数接收任意个参数
# 但是第一个参数是函数的返回值类型,然后函数的参数写在后面,有多少写多少。
# 比如这里的函数返回一个int,接收两个int *,所以就是
t = CFUNCTYPE(c_int, POINTER(c_int), POINTER(c_int))
# 如果函数不需要返回值,那么写一个None即可
# 然后得到一个类型t,此时的类型t就等同于C中的 typedef int (*t)(int*, int*);
# 将我们的函数传进去,就得到了C语言可以识别的函数func
func = t(add)
# 然后调用,别忘了定义返回值类型,当然这里是int就无所谓了
lib.add.restype = c_int
print(lib.add(88, 96, func))
print(lib.add(59, 55, func))
print(lib.add(94, 105, func))
"""
184
114
199
"""
