最近在书中看到多次ip检验和算法,就找度娘问了一下,结果给出的答案也都大差不离,
但是自己也不是很明白,就决定自己亲自实践计算一下,彻底的搞明白。
工具:wireshark
下面是ip首部的结构
经过抓包后得到下图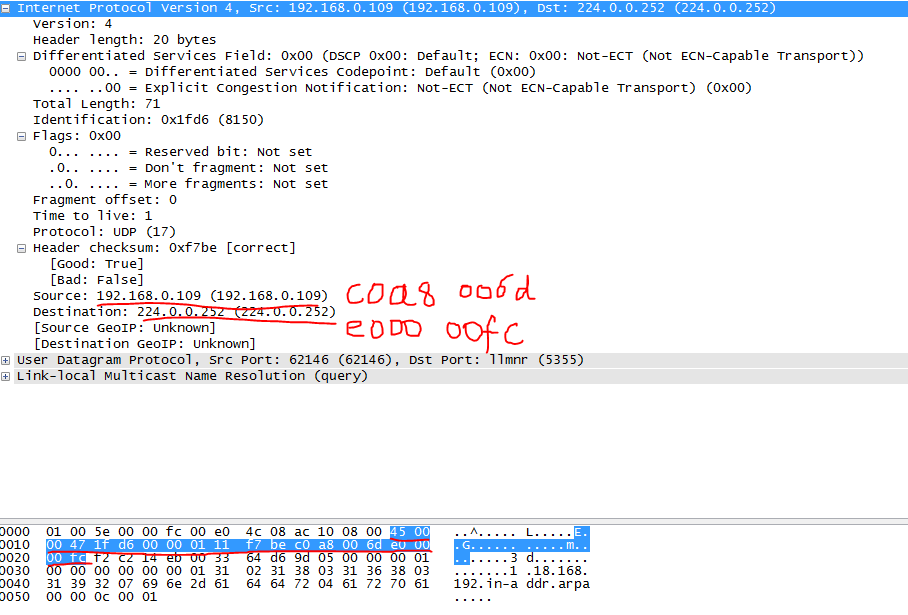
从图中可以看出,ip首部的各种数据格式
解释如下:
版本号4,占了4位,表示ipv4.
接下来是包头长度,又占了4位,指明ipv4协议包头长度的字节数包含多少个32位。由于IPv4
的包头可能包含可变数量的可选 项,所以这个字段可以用来确定IPv4数据报中数据部分的偏
移位置。IPv4包头的最小长度是20个字节,因此IHL这个字段的最小值用十进制表示就是5
(5x4(4个字节32位) = 20字节)。就是说,它表示的是包头的总字节数是4字节的倍数。
图中即为header length为20表示是20个字节,所以经过计算此处用十进制表示为5,二进制
表示为1001。
再往下是服务类型为0x00。
服务类型此处一共占了8位,涵义如下:
过程字段: 3位,设置了数据包的重要性,取值越大数据越重要,取值范围为:0(正常)~ 7(网络控制)
延迟字段: 1位,取值:0(正常)、1(期特低的延迟)
流量字段: 1位,取值:0(正常)、1(期特高的流量)
可靠性字段: 1位,取值:0(正常)、1(期特高的可靠性)
成本字段: 1位,取值:0(正常)、1(期特最小成本)
未使用: 1位
接着是总长度total length:71(十进制表示),换位十六进制是0x0047
标识字段:占16位。IP软件在存储器中维持一个计数器,每产生一个数据报,计数器就加1,并将此值赋给标识字段。
但这个“标识”不是序号,因为IP是无连接服务,数据报不存在按序接收的问题。当数据报由于长度超过网络的MTU而必须分片时,
这个标识字段的值就被复制到所有的数据报片的标识字段中。相同的标识字段的值使分片后的各数据报片最后能正确地重装成为原来的数据报
此处值为0x1fd6
标志(flag):占3位,但目前只有两位有意义。
标志字段中的最低位为MF(More Fragment)。MF=1即表示后面“还有分片”的数据报。MF=0表示这已是若干数据报片中的最后一个。
标志字段中间的一位记为DF(Don't Fragment),意思是“不能分片”。只有当DF=0时才允许分片。
此处值为0x02即010表示不能分片,即don't Fragment
段偏移量:当数据分组时,它和更多段位(MF, More fragments)进行连接,帮助目的主机将分段的包组合
此处值为0x00
在往后为ttl,生存时间8位,表示数据包在网络上生存多久,每通过一个路由器该值减一,为0时将被路由器丢弃。
协议:8位,这个字段定义了IP数据报的数据部分使用的协议类型。常用的协议及其十进制数值包括ICMP(1)、TCP(6)、UDP(17)。
此处生存时间为1,协议是17,换算为16进制是0x0111
源端ip:192.168.0.109 0xc0a8 0x006d
目标ip:224.0.0.252 0xe000 0x00fc
到此,首部的数据基本确定清楚,往下我们来计算检验和checksum
首先明确检验和的计算方法
0和0相加是0,0和1相加是1,1和1相加是0但要产生一个进位1,加到下一列.若最高位相加后产生进位,则最后得到的结果要加1.
在发送数据时,为了计算IP数据包的校验和。应该按如下步骤:
(1)把IP数据包的校验和字段置为0;
(2)把首部看成以16位为单位的数字组成,依次进行二进制反码求和;
(3)把得到的结果存入校验和字段中。
在接收数据时,计算数据包的校验和相对简单,按如下步骤:
(1)把首部看成以16位为单位的数字组成,依次进行二进制反码求和,包括校验和字段;
(2)检查计算出的校验和的结果是否等于零(反码应为16个0);
(3)如果等于零,说明被整除,校验和正确。否则,校验和就是错误的,协议栈要抛弃这个数据包。
网上找了一个简单点的例子先来看一下
原始数据为 1100 , 1010 , 0000(校验位)
那么把他们按照4bit一组进行按位取反相加。 1100取反0011 , 1010取反是0101,0011加上0101 是1000,填入到校验位后
1100 , 1010 , 1000
那么这个就是要发送的数据。收到数据后同样进行按位取反相加。0011+0101+0111 =1111;全为1表示正确
先来计算发送端:
我们这的原始数据为
十六进制:
0x4500 0x0047
0x1fd6 0x0000
0x0111 0xf7be
0xc0a8 0x006d
0xe000 0x00fc
分别对应的二进制如下:
0100 0101 0000 0000
0000 0000 0100 0111
0001 1111 1101 0110
0000 0000 0000 0000
0000 0001 0001 0001
1111 0111 1011 1110
1100 0000 1010 1000
0000 0000 0110 1101
1110 0000 0000 0000
0000 0000 1111 1100
将检验和置0为0x0000
其余分别取反:
1011 1010 1111 1111
1111 1111 1011 1000
1110 0000 0010 1001
1111 1111 1111 1111
1111 1110 1110 1110
0000 0000 0000 0000 ---〉检验和
0011 1111 0101 0111
1111 1111 1001 0010
0001 1111 1111 1111
1111 1111 0000 0011
求和后化为十六进制刚好为0xf7be
另一种方法
先直接相加在取反:
4500+0047+1fd6+0000+0111+c0a8+006d+e000+00fc=2083f
083f+2=841
化为二进制:0000 1000 0100 0001
将其取反后:1111 0111 1011 1110
也是0xf7be
由此可见两种方法均可以计算出正确的检验和。
下面再来看一下接收数据的情况。此次我们用第二种方法计算,即先求和再取反。
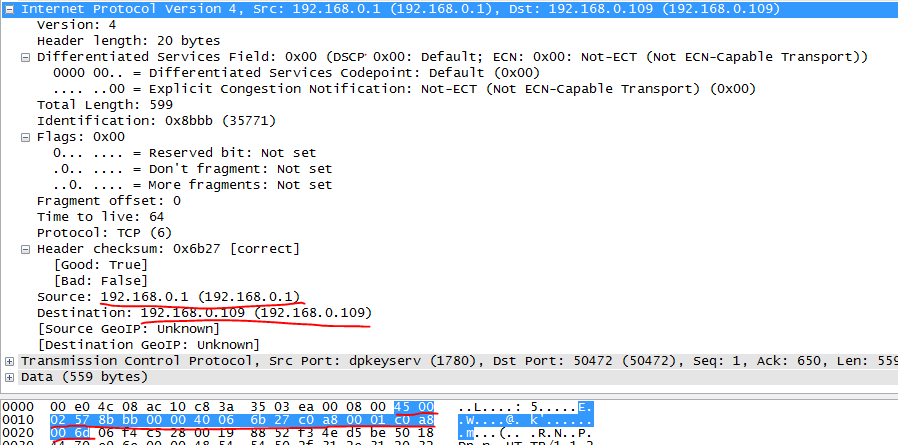
4500+0257+8bbb+0000+4006+6b27+c0a8+0001+c0a8+006d=2fffd
fffd+2=ffff
取反后为0000因此结果正确。