https://study.163.com/course/courseMain.htm?courseId=1006383008&share=2&shareId=400000000398149(博主录制)

原创,机器学习,统计项目合作QQ:231469242,版权所有
GitHub 官网
https://github.com/amueller/word_cloud
Anaconda3,Python3
英文标签云
# -*- coding: utf-8 -*- """
Python3.0 Created on Sat Nov 26 08:54:26 2016 需要的安装包 pip install pytagcloud pip install pygame pip install simplejson @author: daxiong """ import pytagcloud #wordcounts 是一个列表,元素是元组 wordcounts=[("python",5),("love",2),("work",1)] tags = pytagcloud.make_tags(wordcounts) pytagcloud.createtag_image(tags, 'cloud_large.png', size=(900, 600))
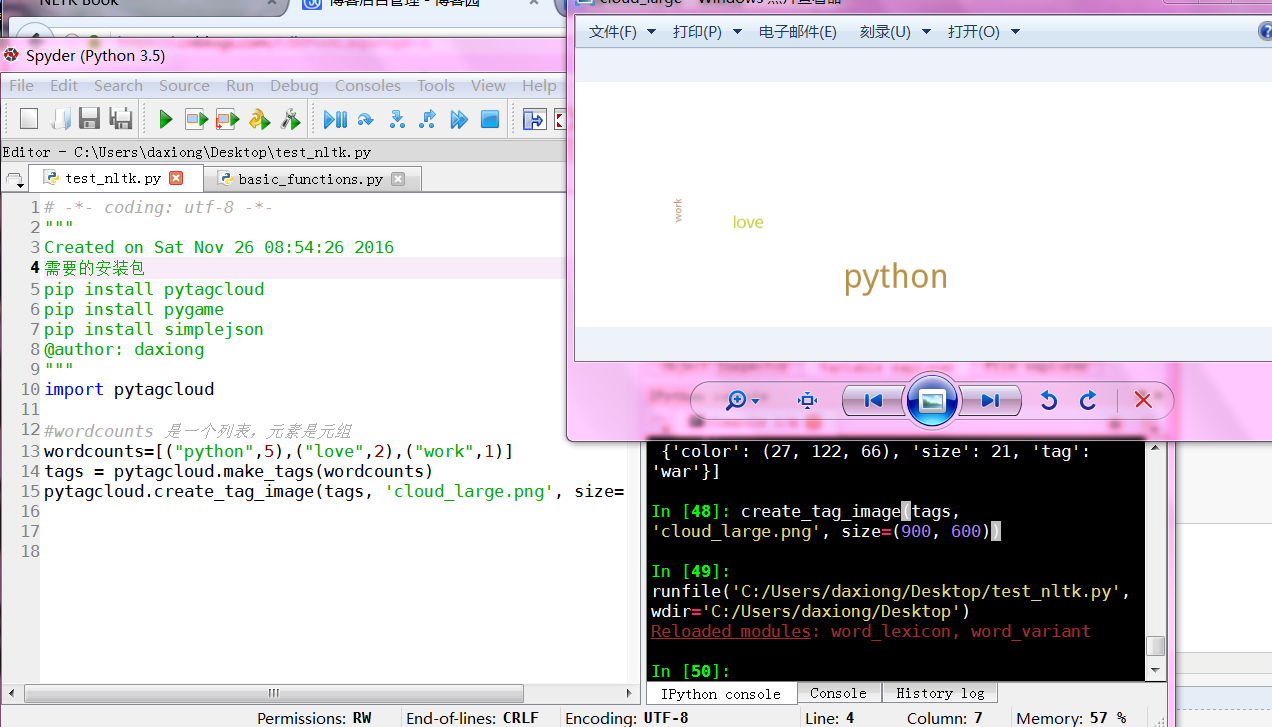
说明文档
中文标签云
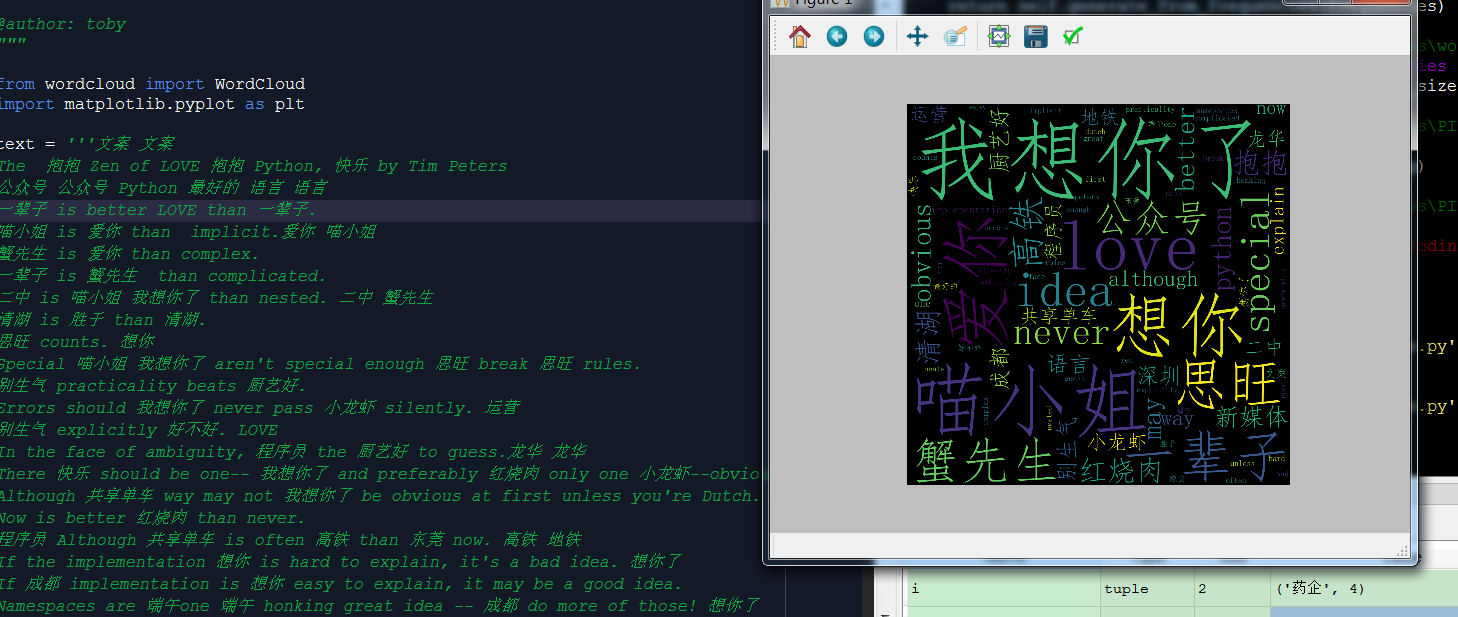
# -*- coding: utf-8 -*-
"""
Created on Mon Aug 14 15:55:43 2017
@author: toby
"""
from wordcloud import WordCloud
import matplotlib.pyplot as plt
text = '''文案 文案
The 抱抱 Zen of LOVE 抱抱 Python, 快乐 by Tim Peters
公众号 公众号 Python 最好的 语言 语言
一辈子 is better LOVE than 一辈子.
喵小姐 is 爱你 than implicit.爱你 喵小姐
蟹先生 is 爱你 than complex.
一辈子 is 蟹先生 than complicated.
二中 is 喵小姐 我想你了 than nested. 二中 蟹先生
清湖 is 胜于 than 清湖.
思旺 counts. 想你
Special 喵小姐 我想你了 aren't special enough 思旺 break 思旺 rules.
别生气 practicality beats 厨艺好.
Errors should 我想你了 never pass 小龙虾 silently. 运营
别生气 explicitly 好不好. LOVE
In the face of ambiguity, 程序员 the 厨艺好 to guess.龙华 龙华
There 快乐 should be one-- 我想你了 and preferably 红烧肉 only one 小龙虾--obvious way to do it.运营
Although 共享单车 way may not 我想你了 be obvious at first unless you're Dutch. 新媒体 地铁
Now is better 红烧肉 than never.
程序员 Although 共享单车 is often 高铁 than 东莞 now. 高铁 地铁
If the implementation 想你 is hard to explain, it's a bad idea. 想你了
If 成都 implementation is 想你 easy to explain, it may be a good idea.
Namespaces are 端午one 端午 honking great idea -- 成都 do more of those! 想你了
深圳 晚安 深圳 新媒体
'''
# the font from github: https://github.com/adobe-fonts
font = r'C:WindowsFontssimfang.ttf'
wc = WordCloud(collocations=False, font_path=font, width=1400, height=1400, margin=2).generate(text.lower())
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file('show_Chinese.png') # 把词云保存下来
爬虫+正则+标签云+pandas保存Excel
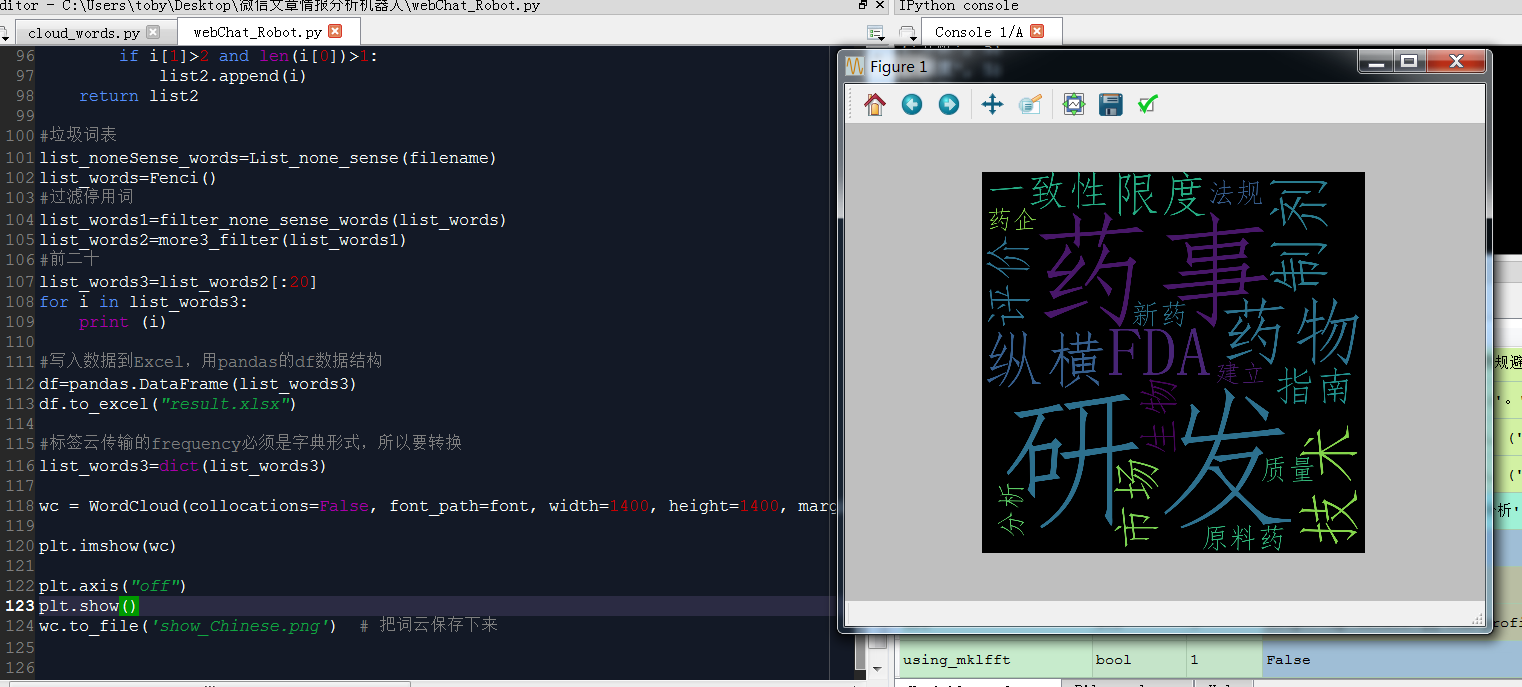
# -*- coding: utf-8 -*-
"""
Created on Mon Aug 14 08:57:21 2017
@author: toby
"""
import jieba
import pandas
import urllib
import re
from bs4 import BeautifulSoup
from wordcloud import WordCloud
import matplotlib.pyplot as plt
#引用微软的中文字体
font = r'C:WindowsFontssimfang.ttf'
'''
#赛柏蓝
url="http://mp.weixin.qq.com/profile?src=3×tamp=1502674891&ver=1&signature=wDxrEoM1f5I3Js7rVZL7XeAOVS5q6FoHLVuMdM*iJLccLjB80A1BESmnMfk62BrS9Uz4VyJ05uzI8aJoW6r6Vw=="
#医药魔方
url="http://mp.weixin.qq.com/profile?src=3×tamp=1502690954&ver=1&signature=*jfLnFfVyfWmIcIyMN*R4*av27A-ubJUNLoiD2B17*Zqj9W*HPoPKdtFegntGr0Ft7jVfdMcW9tLMjBXf7r4vQ=="
'''
url="http://mp.weixin.qq.com/profile?src=3×tamp=1502691348&ver=1&signature=piBaU5ZN*TbBiF41yhw-D4sDK9*mY8TOht4snXuo6Hrm3UKMe5I7wpU*zgCa2Bk3DS-joq3oSNOXboucANMwWg=="
html = urllib.request.urlopen(url).read()
text = BeautifulSoup(html,"lxml").get_text()
#正则表达式规则
#标题名
regex = re.compile(r'"title":"(.+?)"')
#摘要
regex1 = re.compile(r'"digest":"(.+?)"')
#print(regex.findall(text))
#print(regex1.findall(text))
len1=len(regex.findall(text))
list_tilte=regex.findall(text)
list_digest=regex1.findall(text)
#把标题和摘要合并在一起
list_allWords=list_tilte+list_digest
filename="nonesense_words.txt"
#list_noneSense_words=["赛柏蓝","出品","我们","一个","工作","问题","中国","大家"]
#垃圾词库
def List_none_sense(filename):
file_noneSense_words=open(filename,'r')
list_noneSense_words=[]
for line in file_noneSense_words:
line_list=line.split()
for word in line_list:
list_noneSense_words.append(word)
return list_noneSense_words
#判断一个单词是否在垃圾词表里
def none_sense_words_Judeg(word):
if word in list_noneSense_words:
return True
else:
return False
#过滤停用词列表
def filter_none_sense_words(list1):
list2=[]
for i in list1:
#如果不在垃圾词库里或不是数字,汉字长度大于1
if none_sense_words_Judeg(i[0])==False and i[0].isdigit()==False and len(i[0])>1:
#print("remove",i)
list2.append(i)
return list2
def Fenci():
list_total=[]
for i in list_allWords:
seg_list = list(jieba.cut(i,cut_all=False))
list_total+=seg_list
#生成一个字典,每个单词排名
tf={}
for seg in list_total :
#print seg
seg = ''.join(seg.split())
if (seg != '' and seg != "
" and seg != "
") :
if seg in tf :
tf[seg] += 1
else :
tf[seg] = 1
return sorted(tf.items(),key=lambda item:item[1],reverse=True)
#筛选排名大于三的,并且名词长度大于1
def more3_filter(list1):
list2=[]
for i in list1:
if i[1]>2 and len(i[0])>1:
list2.append(i)
return list2
#垃圾词表
list_noneSense_words=List_none_sense(filename)
list_words=Fenci()
#过滤停用词
list_words1=filter_none_sense_words(list_words)
list_words2=more3_filter(list_words1)
#前二十
list_words3=list_words2[:20]
for i in list_words3:
print (i)
#写入数据到Excel,用pandas的df数据结构
df=pandas.DataFrame(list_words3)
df.to_excel("result.xlsx")
#标签云传输的frequency必须是字典形式,所以要转换
list_words3=dict(list_words3)
wc = WordCloud(collocations=False, font_path=font, width=1400, height=1400, margin=2).generate_from_frequencies(list_words3)
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file('show_Chinese.png') # 把词云保存下来
https://study.163.com/provider/400000000398149/index.htm?share=2&shareId=400000000398149(博主视频教学主页)
