流量真的惹不起!我爬了1700条评论数据,包括了评论者评论内容、性别、微博认证与否、所属地区等指标,结果只是一分钟之间的事情~
我还在分析者一分钟的评论时,赵姐跟我说,评论已经破百万了~~
鹅鹅鹅,管他的,已经大于30个样本了,我切入正题吧。
现在有一个可以直接进行微博爬取评论的包,名字是rwda(就是R语言微博数据分析的简称),函数很简单,百度作者直接教你用。获得评论数据的函数是get_comments(access_token, weiboid, maxpage = 10),参数就3个!从简单的说起:maxpage就是你要摘取的评论页数;weiboid的获取如下:进入微博正业,右击查看源代码,ctrl+F找到“mid=”,后面的那串数字就是weiboid。此处有一个坑,源代码里通常可以找到十几个weiboid,因为这个页面进来,旁边还有些小广告什么的,你注意跟你想要爬取内容相关的那个id就行;access_token稍麻烦一点,你得去http://open.weibo.com/tools/console 这里,成为一个开发者,创建好应用之后,平台才给你一个access_token。这里也有一个坑,就是这串数字一定要节约的用,因为用多了好像就失效了。你就得重新创建个应用获取新的接入码。(也不知道我理解得对不对,反正就是这里花了点时间。)
从整体角度、followers前20、男女、地区、微博认证这几个方面进行了可视化,成果如图:

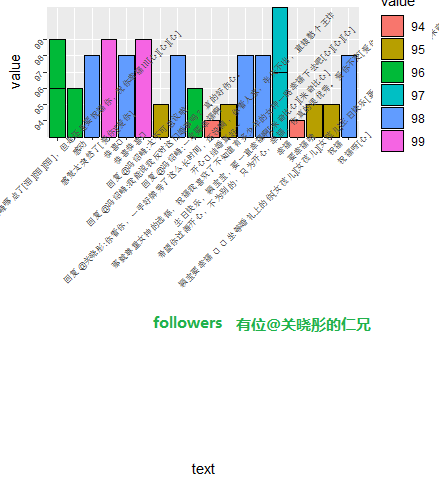
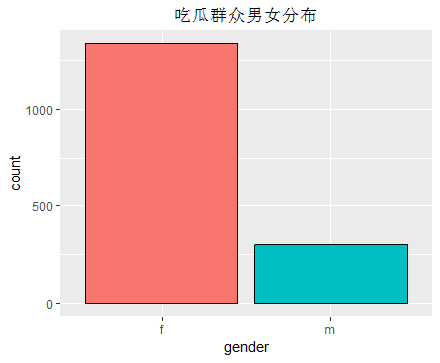

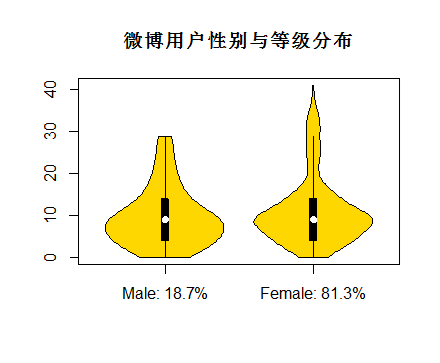

其实,还有其他可以分析的。这里获取评论者的地区信息,是这样子的:(我只展示了重庆地区的评论,但应该懂我的意思哈,各省下面的各市评论数据都有记载~)
