目标网站:https://www.88ys.cc/vod-play-id-58547-src-1-num-1.html 反贪风暴4
对电影进行分析
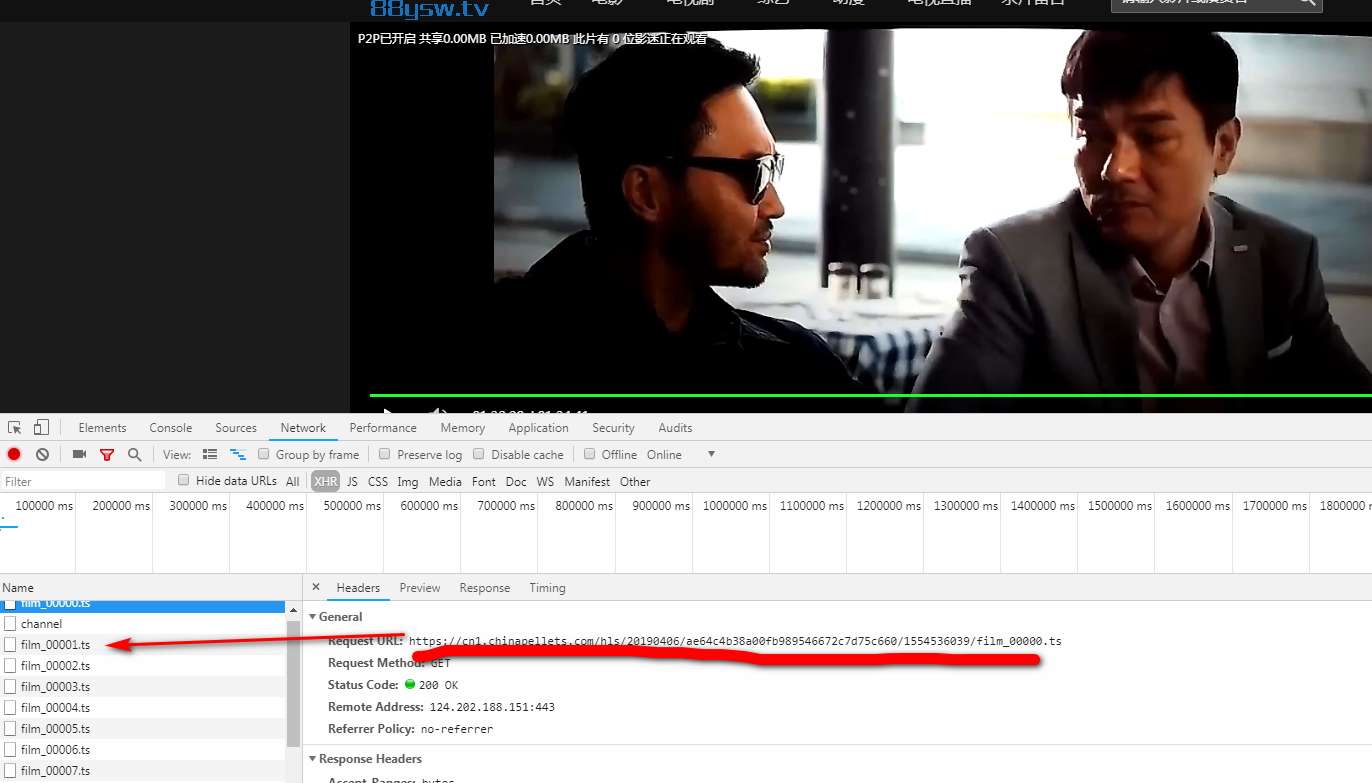
我们发现,电影是按片段一点点加载出来的,我们分别抓取所有ts文件,然后合并成一个完整的文件即可下载到完整电影
代码如下:
# https://www.88ys.cc/vod-play-id-58547-src-1-num-1.html 电影地址 import requests import os import time from multiprocessing import Pool def run(i): url = 'https://cn1.chinapellets.com/hls/20190406/ae64c4b38a00fb989546672c7d75c660/1554536039/film_0%04d.ts'%i print("开始下载:"+url) headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36"} r = requests.get(url, headers = headers) # print(r.content) with open('./mp4/{}'.format(url[-10:]),'wb') as f: f.write(r.content) def merge(t,cmd): time.sleep(t) res=os.popen(cmd) print(res.read()) if __name__ == '__main__': # 创建进程池,执行10个任务 pool = Pool(10) for i in range(2790): pool.apply_async(run, (i,)) #执行任务 pool.close() pool.join() #调用合并 merge(5,"copy /b mp4\*.ts mp4\new.mp4") print('ok!处理完成')
因为单个进程下载太慢了,这里用到了进程池,这样基本达到了,最大网速
运行过程:
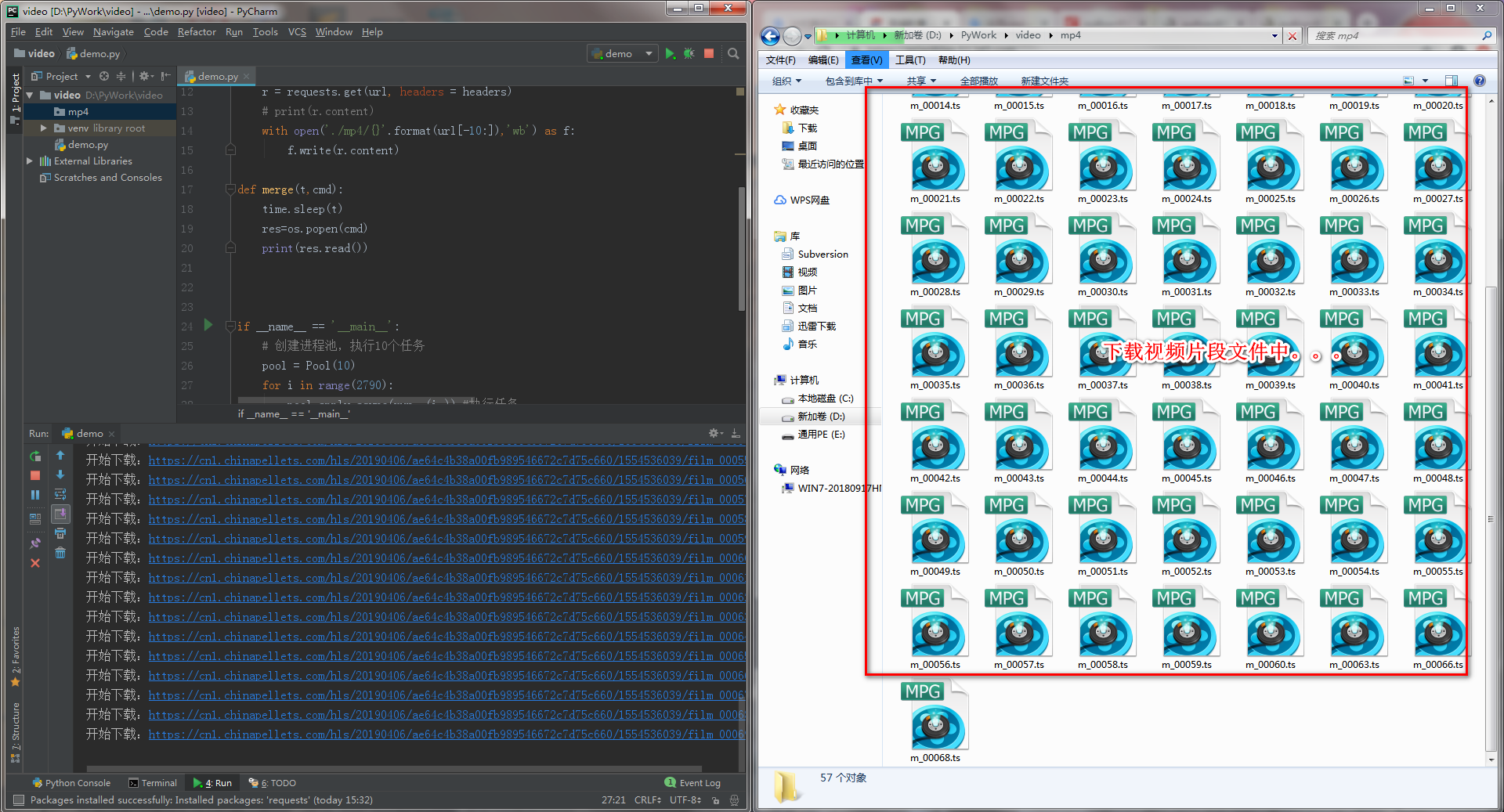
下载完成:
