我原来已经安装了anaconda,在此基础上进入cmd进行pip install tensorflow和pip install gym就可以了. 在win10的pycharm做的。
policy_gradient.py
1 # -*- coding: UTF-8 -*- 2 3 """ 4 Policy Gradient 算法(REINFORCE)。做决策的部分,相当于机器人的大脑 5 """ 6 7 import numpy as np 8 import tensorflow as tf 9 10 try: 11 xrange = xrange # Python 2 12 except: 13 xrange = range # Python 3 14 15 16 # 策略梯度 类 17 class PolicyGradient: 18 def __init__(self, 19 lr, # 学习速率 20 s_size, # state/observation 的特征数目 21 a_size, # action 的数目 22 h_size, # hidden layer(隐藏层)神经元数目 23 discount_factor=0.99 # 折扣因子 24 ): 25 self.gamma = discount_factor # Reward 递减率 26 27 # 神经网络的前向传播部分。大脑根据 state 来选 action 28 self.state_in = tf.placeholder(shape=[None, s_size], dtype=tf.float32) 29 30 # 第一层全连接层 31 hidden = tf.layers.dense(self.state_in, h_size, activation=tf.nn.relu) 32 33 # 第二层全连接层,用 Softmax 来算概率 34 self.output = tf.layers.dense(hidden, a_size, activation=tf.nn.softmax) 35 36 # 直接选择概率最大的那个 action 37 self.chosen_action = tf.argmax(self.output, 1) 38 39 # 下面主要是负责训练的一些过程 40 # 我们给神经网络传递 reward 和 action,为了计算 loss 41 # 再用 loss 来调节神经网络的参数 42 self.reward_holder = tf.placeholder(shape=[None], dtype=tf.float32) 43 self.action_holder = tf.placeholder(shape=[None], dtype=tf.int32) 44 45 self.indexes = tf.range(0, tf.shape(self.output)[0]) * tf.shape(self.output)[1] + self.action_holder 46 self.outputs = tf.gather(tf.reshape(self.output, [-1]), self.indexes) 47 48 # 计算 loss(和平时说的 loss 不一样)有一个负号 49 # 因为 TensorFlow 自带的梯度下降只能 minimize(最小化)loss 50 # 而 Policy Gradient 里面是要让这个所谓的 loss 最大化 51 # 因此需要反一下。对负的去让它最小化,就是让它正向最大化 52 self.loss = -tf.reduce_mean(tf.log(self.outputs) * self.reward_holder) 53 54 # 得到可被训练的变量 55 train_vars = tf.trainable_variables() 56 57 self.gradient_holders = [] 58 59 for index, var in enumerate(train_vars): 60 placeholder = tf.placeholder(tf.float32, name=str(index) + '_holder') 61 self.gradient_holders.append(placeholder) 62 63 # 对 loss 以 train_vars 来计算梯度 64 self.gradients = tf.gradients(self.loss, train_vars) 65 66 optimizer = tf.train.AdamOptimizer(learning_rate=lr) 67 # apply_gradients 是 minimize 方法的第二部分,应用梯度 68 self.update_batch = optimizer.apply_gradients(zip(self.gradient_holders, train_vars)) 69 70 # 计算折扣后的 reward 71 # 公式: E = r1 + r2 * gamma + r3 * gamma * gamma + r4 * gamma * gamma * gamma ... 72 def discount_rewards(self, rewards): 73 discounted_r = np.zeros_like(rewards) 74 running_add = 0 75 for t in reversed(xrange(0, rewards.size)): 76 running_add = running_add * self.gamma + rewards[t] 77 discounted_r[t] = running_add 78 return discounted_r
play.py
1 # -*- coding: UTF-8 -*- 2 3 """ 4 游戏的主程序,调用机器人的 Policy Gradient 决策大脑 5 """ 6 7 import numpy as np 8 import gym 9 import tensorflow as tf 10 11 from policy_gradient import PolicyGradient 12 13 14 # 伪随机数。为了能够复现结果 15 np.random.seed(1) 16 17 env = gym.make('CartPole-v0') 18 env = env.unwrapped # 取消限制 19 env.seed(1) # 普通的 Policy Gradient 方法, 回合的方差比较大, 所以选一个好点的随机种子 20 21 print(env.action_space) # 查看这个环境中可用的 action 有多少个 22 print(env.observation_space) # 查看这个环境中 state/observation 有多少个特征值 23 print(env.observation_space.high) # 查看 observation 最高取值 24 print(env.observation_space.low) # 查看 observation 最低取值 25 26 update_frequency = 5 # 更新频率,多少回合更新一次 27 total_episodes = 3000 # 总回合数 28 29 # 创建 PolicyGradient 对象 30 agent = PolicyGradient(lr=0.01, 31 a_size=env.action_space.n, # 对 CartPole-v0 是 2, 两个 action,向左/向右 32 s_size=env.observation_space.shape[0], # 对 CartPole-v0 是 4 33 h_size=8) 34 35 with tf.Session() as sess: 36 # 初始化所有全局变量 37 sess.run(tf.global_variables_initializer()) 38 39 # 总的奖励 40 total_reward = [] 41 42 gradient_buffer = sess.run(tf.trainable_variables()) 43 for index, grad in enumerate(gradient_buffer): 44 gradient_buffer[index] = grad * 0 45 46 i = 0 # 第几回合 47 while i < total_episodes: 48 # 初始化 state(状态) 49 s = env.reset() 50 51 episode_reward = 0 52 episode_history = [] 53 54 while True: 55 # 更新可视化环境 56 env.render() 57 58 # 根据神经网络的输出,随机挑选 action 59 a_dist = sess.run(agent.output, feed_dict={agent.state_in: [s]}) 60 a = np.random.choice(a_dist[0], p=a_dist[0]) 61 a = np.argmax(a_dist == a) 62 63 # 实施这个 action, 并得到环境返回的下一个 state, reward 和 done(本回合是否结束) 64 s_, r, done, _ = env.step(a) # 这里的 r(奖励)不能准确引导学习 65 66 x, x_dot, theta, theta_dot = s_ # 把 s_ 细分开, 为了修改原配的 reward 67 68 # x 是车的水平位移。所以 r1 是车越偏离中心, 分越少 69 # theta 是棒子离垂直的角度, 角度越大, 越不垂直。所以 r2 是棒越垂直, 分越高 70 r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8 71 r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5 72 r = r1 + r2 # 总 reward 是 r1 和 r2 的结合, 既考虑位置, 也考虑角度, 这样学习更有效率 73 74 episode_history.append([s, a, r, s_]) 75 76 episode_reward += r 77 s = s_ 78 79 # Policy Gradient 是回合更新 80 if done: # 如果此回合结束 81 # 更新神经网络 82 episode_history = np.array(episode_history) 83 84 episode_history[:, 2] = agent.discount_rewards(episode_history[:, 2]) 85 86 feed_dict = { 87 agent.reward_holder: episode_history[:, 2], 88 agent.action_holder: episode_history[:, 1], 89 agent.state_in: np.vstack(episode_history[:, 0]) 90 } 91 92 # 计算梯度 93 grads = sess.run(agent.gradients, feed_dict=feed_dict) 94 95 for idx, grad in enumerate(grads): 96 gradient_buffer[idx] += grad 97 98 if i % update_frequency == 0 and i != 0: 99 feed_dict = dictionary = dict(zip(agent.gradient_holders, gradient_buffer)) 100 101 # 应用梯度下降来更新参数 102 _ = sess.run(agent.update_batch, feed_dict=feed_dict) 103 104 for index, grad in enumerate(gradient_buffer): 105 gradient_buffer[index] = grad * 0 106 107 total_reward.append(episode_reward) 108 break 109 110 # 每 50 回合打印平均奖励 111 if i % 50 == 0: 112 print("回合 {} - {} 的平均奖励: {}".format(i, i + 50, np.mean(total_reward[-50:]))) 113 114 i += 1
启动训练:
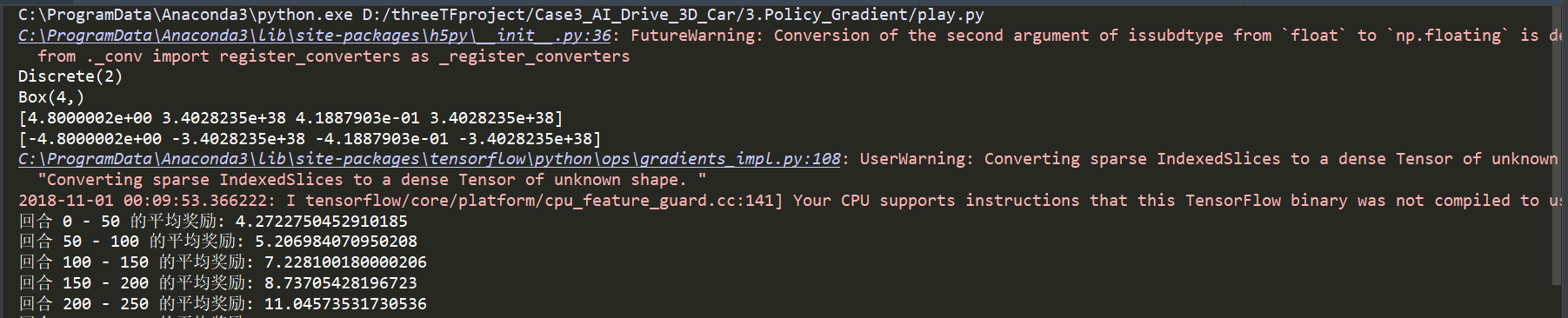
会报一些警告,不用理会,训练到奖励大概有300分的时候,就比较稳定了,能较好的平衡杠子了
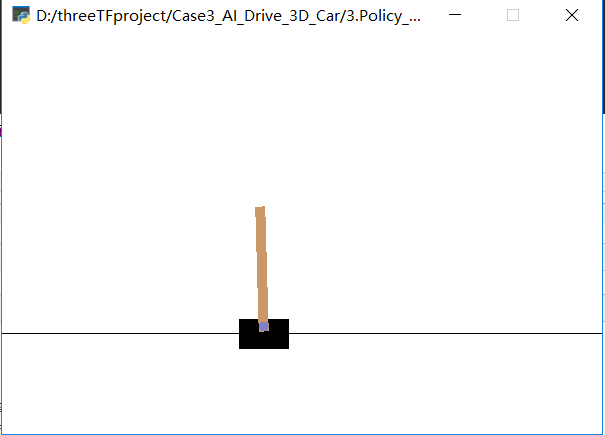
还有另外一个游戏Mountain-car小游戏也可以基于策略梯度来做, 这个小游戏的说明见“基于核方法的强化学习算法-----何源,张文生”里面有一段说明了这个小游戏:

这个具体的实现下回继续。。。