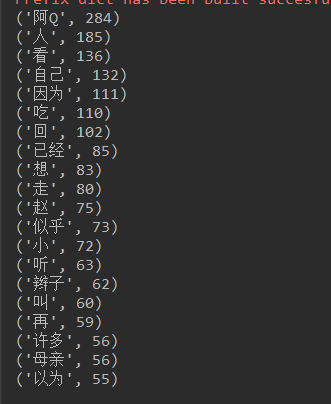
# -*- coding: UTF-8 -*- # -*- coder: mzp -*- import jieba import re with open('test.txt', 'r', encoding='UTF-8') as story: test = story.read() miss_word = "了|他|说|我|你|就|着|又|的|在|是|有|把|到|也|不|都|她|这|便|去|们|还|但|一个|和|却|里|来|要|没|很|"" "|那|么|一|将|呢|起|于|上|只|得|而|而且|对|所以|见|些|才|从|过|被|并|时|且|给|道|虽然|可以|出" test = re.sub("[s+.!/_",$%^*+—()?【】“《;》”!-:,。?、~@#¥%……&*()]+", "", test) test = re.sub(miss_word + '+', "", test) words = list(jieba.cut(test)) # test =''.join(re.findall(u'[u4e00-u9fff]+', test)) # 简单粗暴的中文筛选 key_words = {} for i in set(words): # 统计出词频 key_words[i] = words.count(i) sort_word = sorted(key_words.items(), key = lambda d:d[1], reverse = True) # 排序 for i in range(20): # 输出 print(sort_word[i])