一,无监督学习(Unsupervised learning)
无监督学习就是给定一系列没有标签的训练数据,找出训练数据之间的关系,最典型的就是聚类算法(Clustering Algorithm)
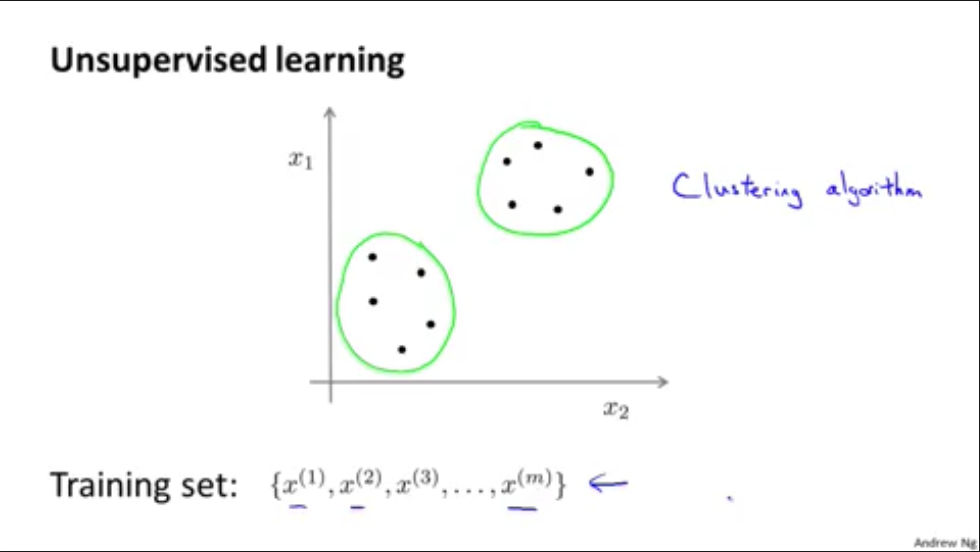
无监督学习的工程应用

二,K均值法(K Means Algorithm),
1,K均值法是常用聚类算法之一,把训练数据分为K个聚类


2,算法过程
1),随机寻找K个数据作为聚类中心
2),给每个数据分配一个离它最近的聚类中心
3),计算分配给同一个聚类中心的所有数据的均值,聚类中心更改至均值
4),如果所有聚类中心都等于均值,结束,否则跳至第2步
P.S 如果某个聚类中心没有其他数据分配给它,移除该中心
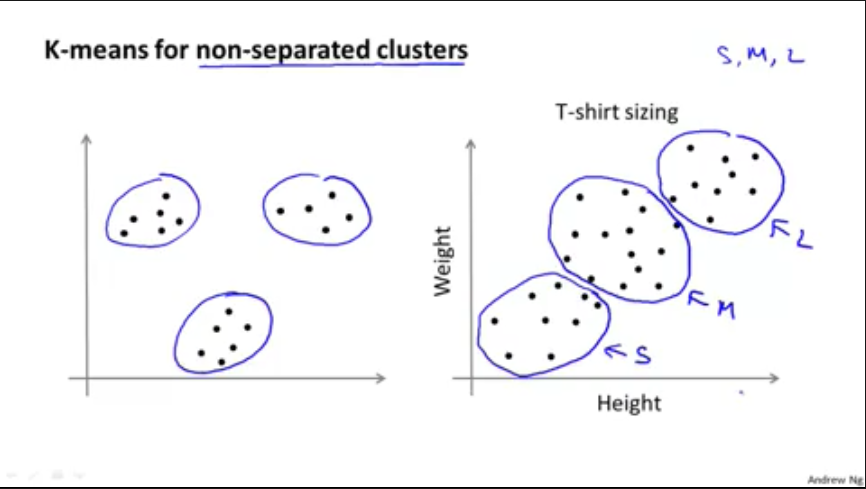
3,市场细分的一个例子
4,代价函数
K均值法的优化目标是使所有数据到各自的聚类中心的距离的和最小

K均值法的算法过程其实就是求使代价函数最小的聚类中心的过程

随机寻找K个数据作为聚类中心,有可能会找到代价函数的局部最小值,
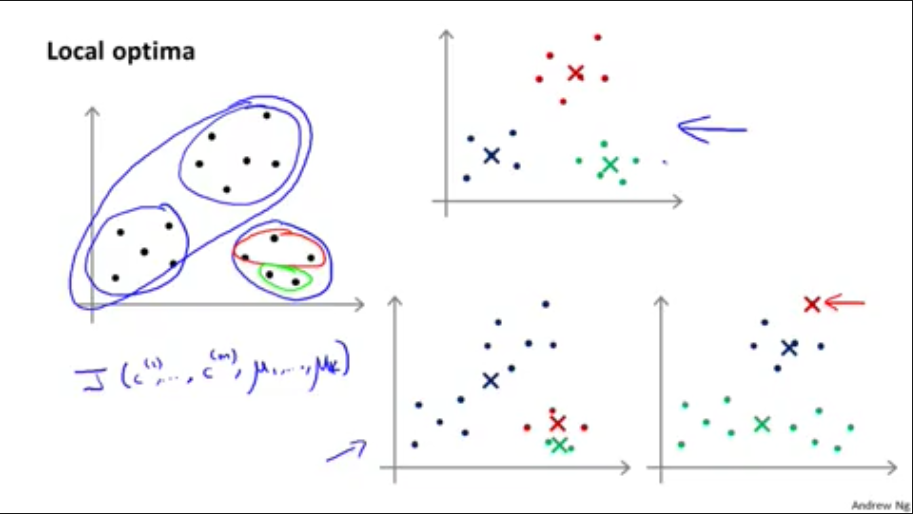
所以需要多次随机初始化运行K均值法,计算代价函数最小值

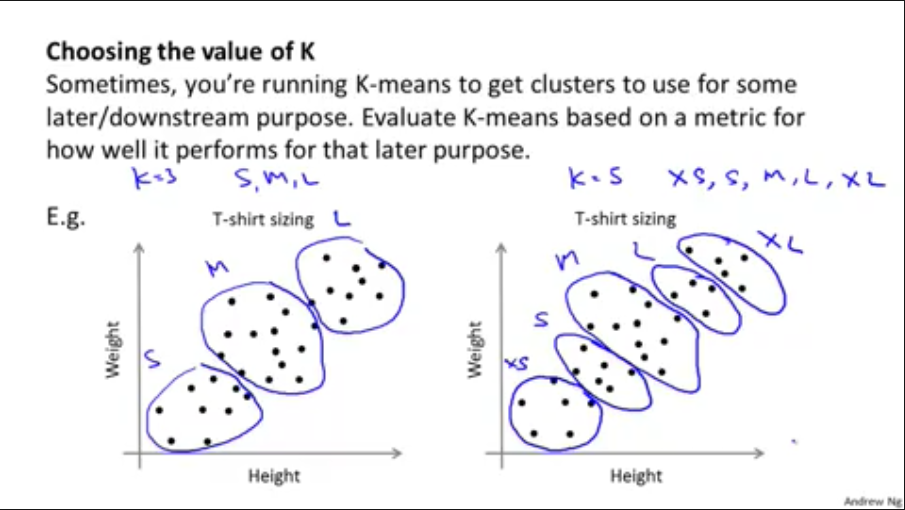
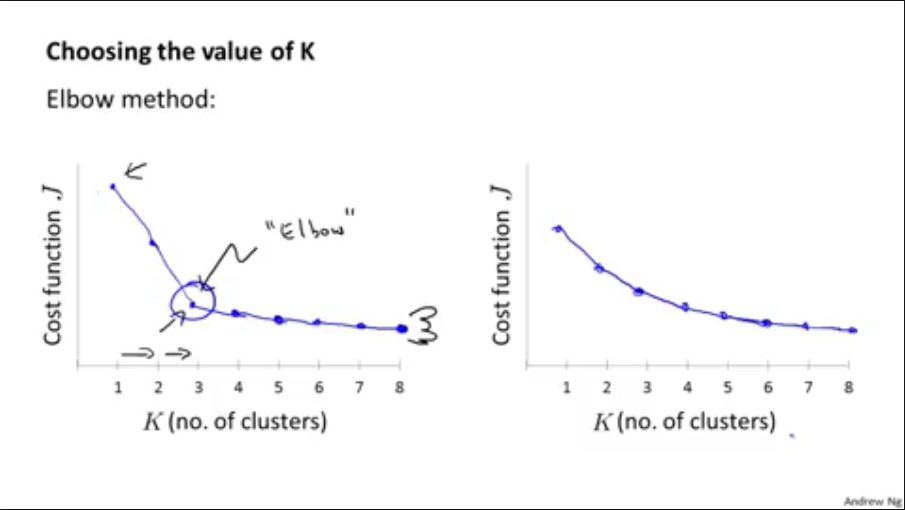
5,如何选择聚类中心数量K
肘部方法(Elbow Method),画出K和代价函数J的二次图,选用使斜率急剧变化(肘部)的K,但如第二幅图所示,斜率变化不大,肘部方法就就没用
T我们还应该根据聚类的目的来决定聚类的数量K,以制造T恤为例,我们是想制造更多的尺寸类型来使顾客更满意,还是更少的尺寸类型使T恤卖的更便宜