第一次实战,我们以博客园为例。
Cnblog是典型的静态网页,通过查看博文的源代码,可以看出很少js代码,连css代码也比较简单,很适合爬虫初学者来练习。
博客园的栗子,我们的目标是获取某个博主的所有博文,今天先将第一步。
第一步:已知某一篇文章的url,如何获取正文?
举个栗子,我们参考‘农民伯伯’的博客文章吧,哈哈。他是我关注的一个博主。
http://www.cnblogs.com/over140/p/4440137.html
这是他的一篇名为“【读书笔记】长尾理论”的文章。
我们如果想要存储这篇文章,需要保存的内容首先是文章的标题,再就是文章的正文。
文章的标题怎么获取的?
先看一下文章标题在网页源代码中的位置是如何的。
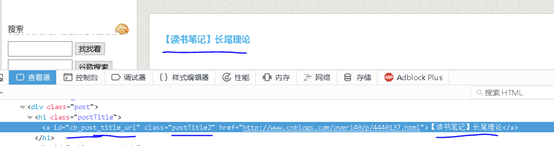
可以看出来,标题的文字内容是包含在一个a标签里面的,我们将这个标签打印出来:
<a id="cb_post_title_url" class="postTitle2" href="http://www.cnblogs.com/over140/p/4440137.html">【读书笔记】长尾理论</a>
那个标签具有id属性,值为“cb_post_title_url”,具有class属性,值为“postTitle2”,还具有一个href属性,指向了这篇文章的url。
这个标签应该是比较方便定位的,所以文章标题我们能够很快找到。
代码如下:
import urllib.request import re url='http://www.cnblogs.com/over140/p/4440137.html' req=urllib.request.Request(url) resp=urllib.request.urlopen(req) html_page=resp.read().decode('utf-8') title_pattern=r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)' title_match=re.search(title_pattern,html_page) title=title_match.group(2) #print(title)
上面的title就是我们想要爬取的这篇文章的代码
文章的正文如何获取呢?
来看一下文章的结构,正文的所有内容都在一个div标签里面,但是这个div中存在很多其他标签,并不是直接一堆文字放在div标签里面。比如有很多<p></p>标签,比如<strong>标签。
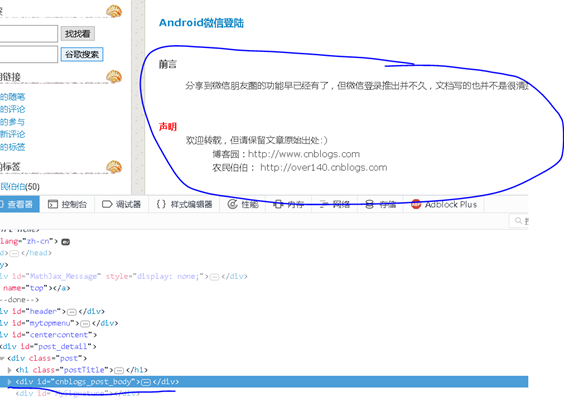
如何获取所有的内容呢?
我猜测,只要将所有><之间的内容,应该就可以获得所有的正文内容。试一下,代码如下:
div_pattern=r'<div id="cnblogs_post_body">(.*)</div>' div_match=re.search(div_pattern,html_page) div=div_match.group(1) #print(div) result_pattern=r'>(.*)<' result_match=re.findall(result_pattern,div) result='' for i in result_match: result+=str(i) print(result)
遗憾的是,失败了。。。打印出来的内容,不仅包含文字,还有一些包含在内的标签,比如<span>。
用正则表达式的缺陷这里就体现出来了。。我们还是用BeautifulSoup来解析文档吧。
使用BeautifulSoup解析内容的方法,请回顾我所写的爬虫入门的文章。
获取正文所在的div标签的代码如下:
from bs4 import BeautifulSoup soup=BeautifulSoup(html_page,'html.parser') #print(soup.prettify()) div=soup.find(id="cnblogs_post_body") #print(div.text) print(div.get_text())
哈哈,大功告成,我们获得了正文的内容。为了便于保存,我们将文章保存到当前目录下。
filename=title+'.txt' with open(filename,'w',encoding='utf-8') as f: f.write(div.text)
OK了,至此为止,我们获取并保存了这篇文章。
来,所有的代码如下所示:
import urllib.request import re from bs4 import BeautifulSoup url='http://www.cnblogs.com/over140/p/4440137.html' req=urllib.request.Request(url) resp=urllib.request.urlopen(req) html_page=resp.read().decode('utf-8') title_pattern=r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)' title_match=re.search(title_pattern,html_page) title=title_match.group(2) #print(title) ''' div_pattern=r'<div id="cnblogs_post_body">(.*)</div>' div_match=re.search(div_pattern,html_page) div=div_match.group(1) #print(div) result_pattern=r'>(.*)<' result_match=re.findall(result_pattern,div) result='' for i in result_match: result+=str(i) print(result) ''' soup=BeautifulSoup(html_page,'html.parser') #print(soup.prettify()) div=soup.find(id="cnblogs_post_body") #print(div.text) print(div.get_text()) filename=title+'.txt' with open(filename,'w',encoding='utf-8') as f: f.write(div.text)
