scheduler
当Scheduler通过API server 的watch接口监听到新建Pod副本的信息后,它会检查所有符合该Pod要求的Node列表,开始执行Pod调度逻辑。调度成功后将Pod绑定到目标节点上。Scheduler在整个系统中承担了承上启下的作用,承上是负责接收创建的新Pod,为安排一个落脚的地(Node),启下是安置工作完成后,目标Node上的kubelet服务进程接管后继工作,负责Pod生命周期的后半生。具体来说,Scheduler的作用是将待调度的Pod安装特定的调度算法和调度策略绑定到集群中的某个合适的Node上,并将绑定信息传给API server 写入etcd中。整个调度过程中涉及三个对象,分别是:待调度的Pod列表,可以的Node列表,以及调度算法和策略。
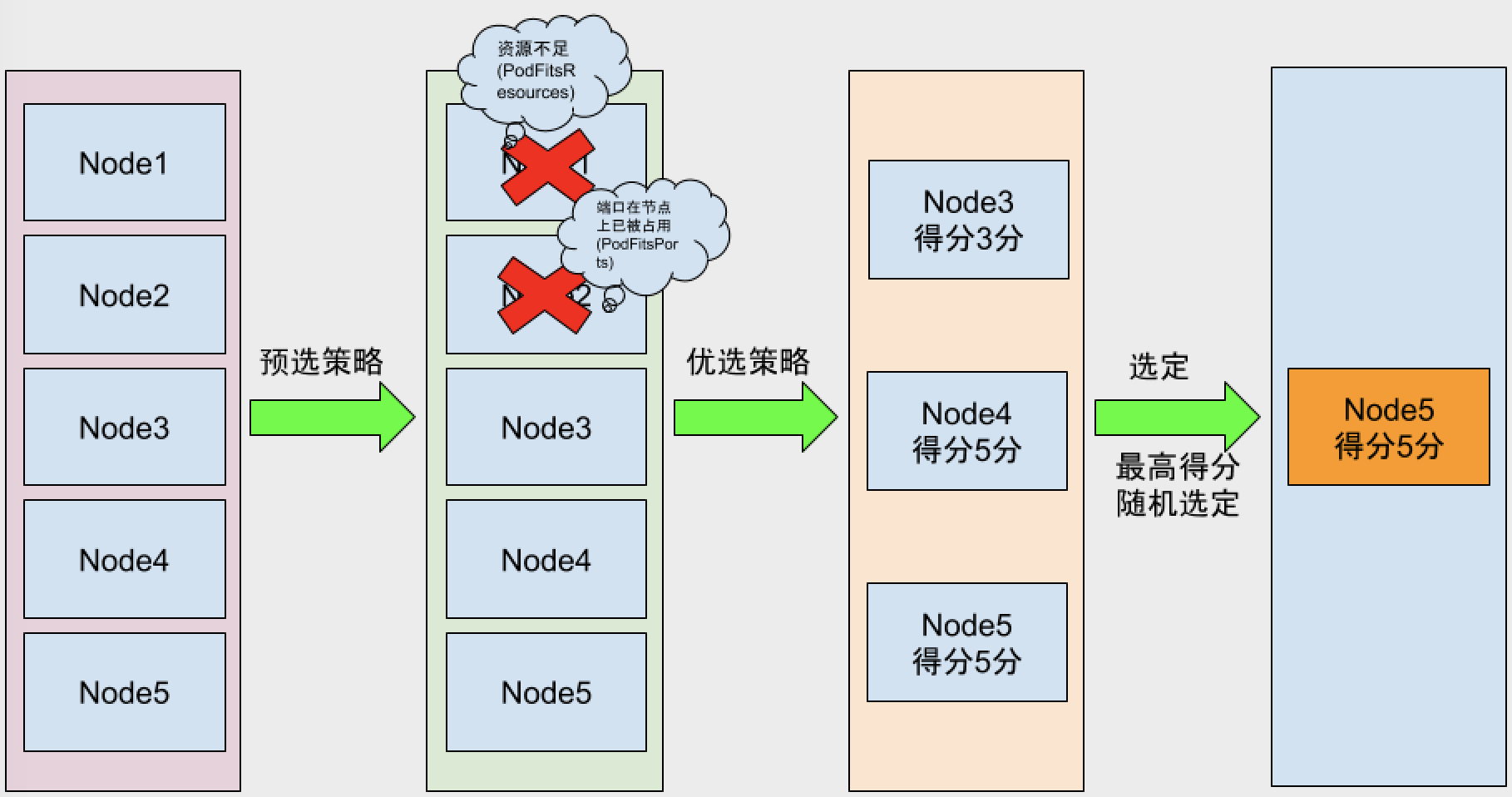
Kubernetes Scheduler 提供的调度流程分三步:
- 预选策略(predicate) 遍历nodelist,选择出符合要求的候选节点,Kubernetes内置了多种预选规则供用户选择。
- 优选策略(priority) 在选择出符合要求的候选节点中,采用优选规则计算出每个节点的积分,最后选择得分最高的。
- 选定(select) 如果最高得分有好几个节点,select就会从中随机选择一个节点。
如图:
预选策略算法的集合在官方源码
常用的预选策略(代码里的策略不一定都会被使用)
- CheckNodeConditionPred 检查节点是否正常
- GeneralPred HostName(如果pod定义hostname属性,会检查节点是否匹配。pod.spec.hostname)、PodFitsHostPorts(检查pod要暴露的hostpors是否被占用。pod.spec.containers.ports.hostPort)
- MatchNodeSelector pod.spec.nodeSelector 看节点标签能否适配pod定义的nodeSelector
- PodFitsResources 判断节点的资源能够满足Pod的定义(如果一个pod定义最少需要2C4G node上的低于此资源的将不被调度。用kubectl describe node NODE名称 可以查看资源使用情况)
- NoDiskConflict 判断pod定义的存储是否在node节点上使用。(默认没有启用)
- PodToleratesNodeTaints 检查pod上Tolerates的能否容忍污点(pod.spec.tolerations)
- CheckNodeLabelPresence 检查节点上的标志是否存在 (默认没有启动)
- CheckServiceAffinity 根据pod所属的service。将相同service上的pod尽量放到同一个节点(默认没有启动)
- CheckVolumeBinding 检查是否可以绑定(默认没有启动)
- NoVolumeZoneConflict 检查是否在一起区域(默认没有启动)
- CheckNodeMemoryPressure 检查内存是否存在压力
- CheckNodeDiskPressure 检查磁盘IO压力是否过大
- CheckNodePIDPressure 检查pid资源是否过大
优选策略
- least_requested 选择消耗最小的节点(根据空闲比率评估 cpu(总容量-sum(已使用)*10/总容量) )
高级调度方式
当我们想把调度到预期的节点,我们可以使用高级调度分为:
- 节点选择器: nodeSelector、nodeName
- 节点亲和性调度: nodeAffinity
- Pod亲和性调度:PodAffinity
- Pod反亲和性调度:podAntiAffinity
NodeSelector
我们定义一个pod,让其选择带有node=ssd这个标签的节点
apiVersion: v1 kind: Pod metadata: name: pod-1 labels: name: myapp spec: containers: - name: myapp image: ikubernetes/myapp:v1 nodeSelector: node: ssd
kubectl apply -f test.yaml
查看信息
#get一下pod 一直处于Pending状态 $ kubectl get pod NAME READY STATUS RESTARTS AGE pod-1 0/1 Pending 0 7s #查看详细信息,是没有可用的selector $ kubectl describe pod pod-1 ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 9s (x14 over 36s) default-scheduler 0/4 nodes are available: 4 node(s) didn't match node selector. #我们给node2打上这个标签 $ kubectl label node k8s-node02 node=ssd node/k8s-node02 labeled #Pod正常启动 $ kubectl describe pod pod-1 .... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 2m (x122 over 8m) default-scheduler 0/4 nodes are available: 4 node(s) didn't match node selector. Normal Pulled 7s kubelet, k8s-node02 Container image "ikubernetes/myapp:v1" already present on machine Normal Created 7s kubelet, k8s-node02 Created container Normal Started 7s kubelet, k8s-node02 Started container
nodeAffinity
kubectl explain pod.spec.affinity.nodeAffinity
- requiredDuringSchedulingIgnoredDuringExecution 硬亲和性 必须满足亲和性。
- matchExpressions 匹配表达式,这个标签可以指定一段,例如pod中定义的key为zone,operator为In(包含那些),values为 foo和bar。就是在node节点中包含foo和bar的标签中调度
- matchFields 匹配字段 和上面的意思 不过他可以不定义标签值,可以定义
- preferredDuringSchedulingIgnoredDuringExecution 软亲和性 能满足最好,不满足也没关系。
- preference 优先级
- weight 权重1-100范围内,对于满足所有调度要求的每个节点,调度程序将通过迭代此字段的元素计算总和,并在节点与对应的节点匹配时将“权重”添加到总和。
运算符包含:In,NotIn,Exists,DoesNotExist,Gt,Lt。可以使用NotIn和DoesNotExist实现节点反关联行为。
硬亲和性:
apiVersion: v1 kind: Pod metadata: name: node-affinity-pod labels: name: myapp spec: containers: - name: myapp image: ikubernetes/myapp:v1 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: zone operator: In values: - foo - bar $ kubectl apply -f pod-affinity-demo.yaml $ kubectl describe pod node-affinity-pod ..... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 33s (x25 over 1m) default-scheduler 0/4 nodes are available: 4 node(s) didn't match node selector. # 给其中一个node打上foo的标签 $ kubectl label node k8s-node03 zone=foo $ kubectl get pods NAME READY STATUS RESTARTS AGE node-affinity-pod 1/1 Running 0 8m
软亲和性:
与requiredDuringSchedulingIgnoredDuringExecution比较,这里需要注意的是preferredDuringSchedulingIgnoredDuringExecution是个列表项,而preference不是一个列表项了。
apiVersion: v1 kind: Pod metadata: name: node-affinity-pod-2 labels: name: myapp spec: containers: - name: myapp image: ikubernetes/myapp:v1 affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 50 preference: matchExpressions: - key: zone operator: In values: - foo - bar
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
node-affinity-pod 1/1 Running 0 3h 10.244.3.2 k8s-node03
node-affinity-pod-2 1/1 Running 0 1m 10.244.3.3 k8s-node03
podAffinity
Pod亲和性场景,我们的k8s集群的节点分布在不同的区域或者不同的机房,当服务A和服务B要求部署在同一个区域或者同一机房的时候,我们就需要亲和性调度了。
kubectl explain pod.spec.affinity.podAffinity 和NodeAffinity是一样的,都是有硬亲和性和软亲和性
硬亲和性:
- labelSelector 选择跟那组Pod亲和
- namespaces 选择哪个命名空间
- topologyKey 指定节点上的哪个键
样例
apiVersion: v1 kind: Pod metadata: name: node-affinity-pod1 labels: name: podaffinity-myapp tier: service spec: containers: - name: myapp image: ikubernetes/myapp:v1 --- apiVersion: v1 kind: Pod metadata: name: node-affinity-pod2 labels: name: podaffinity-myapp tier: front spec: containers: - name: myapp image: ikubernetes/myapp:v1 affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: name operator: In values: - podaffinity-myapp topologyKey: kubernetes.io/hostname
查看
kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE node-affinity-pod1 1/1 Running 0 12s 10.244.2.6 k8s-node02 node-affinity-pod2 1/1 Running 0 12s 10.244.2.5 k8s-node02
podAntiAffinity
Pod反亲和性场景,当应用服务A和数据库服务B要求尽量不要在同一台节点上的时候。
kubectl explain pod.spec.affinity.podAntiAffinity 也分为硬反亲和性和软反亲和性调度(和podAffinity一样的配置)
#首先把两个node打上同一个标签。 kubectl label node k8s-node02 zone=foo kubectl label node k8s-node03 zone=foo #反硬亲和调度 apiVersion: v1 kind: Pod metadata: name: node-affinity-pod1 labels: name: podaffinity-myapp tier: service spec: containers: - name: myapp image: ikubernetes/myapp:v1 --- apiVersion: v1 kind: Pod metadata: name: node-affinity-pod2 labels: name: podaffinity-myapp tier: front spec: containers: - name: myapp image: ikubernetes/myapp:v1 affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: name operator: In values: - podaffinity-myapp topologyKey: zone
查看一下(因为zone这个key在每个node都有会,所以第二个Pod没有办法调度,所以一直Pending状态)
$ kubectl get pod NAME READY STATUS RESTARTS AGE node-affinity-pod1 1/1 Running 0 11s node-affinity-pod2 0/1 Pending 0 11s
污点容忍调度(Taint和Toleration)
前两种方式都是pod选择那个pod,而污点调度是node选择的pod,污点就是定义在节点上的键值属性数据。举要作用是让节点拒绝pod,拒绝不合法node规则的pod。Taint(污点)和 Toleration(容忍)是相互配合的,可以用来避免 pod 被分配到不合适的节点上,每个节点上都可以应用一个或多个 taint ,这表示对于那些不能容忍这些 taint 的 pod,是不会被该节点接受的。
Taint
Taint是节点上属性,我们看一下Taints如何定义
kubectl explain node.spec.taints(对象列表)
- key 定义一个key
- value 定义一个值
- effect pod不能容忍这个污点时,他的行为是什么,行为分为三种:NoSchedule 仅影响调度过程,对现存的pod不影响。PreferNoSchedule 系统将尽量避免放置不容忍节点上污点的pod,但这不是必需的。就是软版的NoSchedule NoExecute 既影响调度过程,也影响现存的pod,不满足的pod将被驱逐。
node 打 taint
kubectl taint NODE NAME KEY_1=VAL_1:TAINT_EFFECT_1 ... KEY_N=VAL_N:TAINT_EFFECT_N [options]
增加taint
kubectl taint node k8s-node02 node-type=prod:NoSchedule
删除taint
kubectl taint node k8s-node02 node-type:NoSchedule-
tolerations
- key 被容忍的key
- tolerationSeconds 被驱逐的宽限时间,默认是0 就是立即被驱逐
- value 被容忍key的值
- operator Exists只要key在就可以调度,Equal(等值比较)必须是值要相同
- effect 节点调度后的操作
创建一个容忍
apiVersion: apps/v1 kind: Deployment metadata: name: myapp-deploy namespace: default spec: replicas: 3 selector: matchLabels: app: myapp release: dev template: metadata: labels: app: myapp release: dev spec: containers: - name: myapp-containers image: ikubernetes/myapp:v2 ports: - name: http containerPort: 80 tolerations: - key: "node-type" operator: "Equal" value: "prod" effect: "NoSchedule"