官网传送门:
https://docs.mongodb.com/manual/core/replica-set-write-concern/
https://docs.mongodb.com/manual/core/transactions/#read-concern-write-concern-read-preference
MongoDB ACID 多文档事务支持
| 事务属性 | 支持程度 |
| Atomocity 原子性 | 单表单文档 : 1.x 就支持 复制集多表多行:4.0 复制集 分片集群多表多行4.2 |
| Consistency 一致性 | writeConcern, readConcern (3.2) |
| Isolation 隔离性 | readConcern (3.2) |
| Durability 持久性 | Journal and Replication |
Atomocity 原子性
一个事务作为一个提交单位,要么一起成功要么一起失败,分布式关注的重点就是多节点之间数据的原子性控制。
Consistency 一致性
读和写的一致性,会不会读到脏数据。
Isolation 隔离性
每个事务相互之间是独立的,每个事务内与主表之间也是互不影响、相互独立的。
Durability 持久性
数据落盘持久化,通过记录Journal日志文件和备份副本。
先从mongoDB的一致性相关的writeConcern, readConcern说。
什么是 writeConcern ?
writeConcern 决定一个写操作落到多少个节点上才算成功。writeConcern 的取值包括:
• 0:发起写操作,不关心是否成功;
• 1~集群最大数据节点数:写操作需要被复制到指定节点数才算成功;默认是1。
• majority:写操作需要被复制到大多数节点上才算成功。
• all:写入所有节点才算成功。
发起写操作的程序将阻塞到写操作到达指定的节点数为止
默认情况 w:“1”
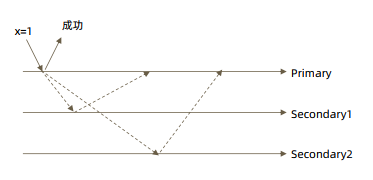
大多数节点确认(即一半以上节点) w: “majority”
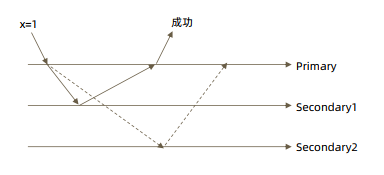
全部节点确认 w: “all”
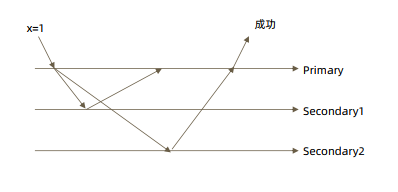
j:true
writeConcern 可以决定写操作到达多少个节点才算成功,journal 则定义如何才算成
功。取值包括:
• true: 写操作落到 journal 文件中才算成功;
• false: 写操作到达内存即算作成功。
数据库数据写入的顺序 数据在内存中先写日志文件(journal 中落地持久化日志文件),再写数据文件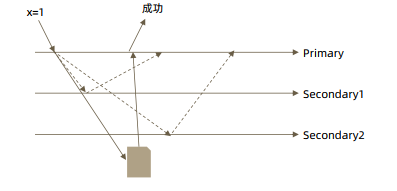
mongoDB shell中使用
db.test.insert( {count: 1}, {writeConcern: {w: "majority"}})
db.test.insert( {count: 1}, {writeConcern: {w: 3 }})
db.test.insert( {count: 1}, {writeConcern: {w: 4 }})
readPreference与readConcern
readPreference 设置 分布式数据库从哪里读
readConcern 什么样的数据可以读
readPreference
readPreference 决定使用哪一个节点来满足正在发起的读请求。可选值包括:
• primary: 只选择主节点;
• primaryPreferred:优先选择主节点,如果不可用则选择从节点;
• secondary:只选择从节点;
• secondaryPreferred:优先选择从节点,如果从节点不可用则选择主节点;
• nearest:选择最近的节点;
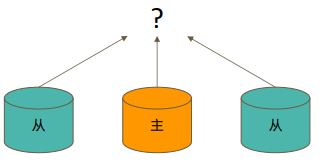
场景举例:大量高并发读取的数据场景可以选择从节点,写入数据的时候,用主节点。
readPreference的 配置方式
通过 MongoDB 的连接串参数: • mongodb://host1:27107,host2:27107,host3:27017/?replicaSet=rs&readPreference=secondary 通过 MongoDB 驱动程序 API: • MongoCollection.withReadPreference(ReadPreference readPref) Mongo Shell: • db.collection.find({}).readPref( “secondary” )
readConcern
在 readPreference 选择了指定的节点后,readConcern 决定这个节点上的数据哪些是可读的,类似于关系数据库的隔离级别。可选值包括:
• available:读取所有可用的数据;
• local:读取所有可用且属于当前分片的数据;
• majority:读取在大多数节点上提交完成的数据;
• linearizable:可线性化读取文档;
• snapshot:读取最近快照中的数据;
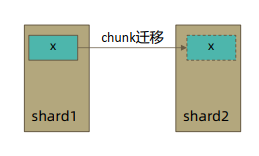
在复制集中 local 和 available 是没有区别的。两者的区别主要体现在分片集上。考虑以下场景:
• 一个 chunk x 正在从 shard1 向 shard2 迁移;
• 整个迁移过程中 chunk x 中的部分数据会在 shard1 和 shard2 中同时存在,但源分片 shard1仍然是chunk x 的负责方:
所有对 chunk x 的读写操作仍然进入 shard1;
config 中记录的信息 chunk x 仍然属于 shard1;
• 此时如果读 shard2,则会体现出 local 和 available 的区别:
local:只取应该由 shard2 负责的数据(不包括 x);
available:shard2 上有什么就读什么(包括 x);
注意事项: • 虽然看上去总是应该选择 local,但毕竟对结果集进行过滤会造成额外消耗。在一些无关紧要的场景(例如统计)下,也可以考虑 available; • MongoDB <=3.6 不支持对从节点使用 {readConcern: "local"}; • 从主节点读取数据时默认 readConcern 是 local,从从节点读取数据时默认readConcern 是 available(向前兼容原因)。
readConcern : ”majority” vs “local”
majority 如果有如下场景:
应业务需要做读写分离,主节点A主要做写入操作,从节点做读取操作;向主节点写入一条数据;立即从从节点读取这条数据。
如果用默认配置local,有的复制集从节点B到主A可能是有延时的,而导致在主节点A上修改数据后,立刻在从节点读取,发现有脏数据,主从数据不同步。所以需要majority配置,和其他节点互交确认大多数据节点上都是一样的数据才返回。
#注意配置文件内server参数开启
enableMajorityReadConcern:ture
#这种方式读取不到刚写入的数据
db.orders.insert({ oid: 101, sku: ”kite", q: 1}) //主节点写入
db.orders.find({oid:101}).readPref("secondary") //从节点读取
#使用 writeConcern + readConcern majority来解决
db.orders.insert({ oid: 101, sku: "kiteboar", q: 1}, {writeConcern:{w: "majority”}}) //主节点写入
db.orders.find({oid:101}).readPref(“secondary”).readConcern("majority") //从节点读取
readConcern: majority 与脏读
MongoDB 中的回滚:
• 写操作到达大多数节点之前都是不安全的,一旦主节点崩溃,而从节还没复制到该次操作,刚才的写操作就丢失了;
• 把一次写操作视为一个事务,从事务的角度,可以认为事务被回滚了。所以从分布式系统的角度来看,事务的提交被提升到了分布式集群的多个节点级别的“提交”,而不再是单个节点上的“提交”。在可能发生回滚的前提下考虑脏读问题:
• 如果在一次写操作到达大多数节点前读取了这个写操作,然后因为系统故障该操作回滚了,则发生了脏读问题;
使用 {readConcern: “majority”} 可以有效避免脏读
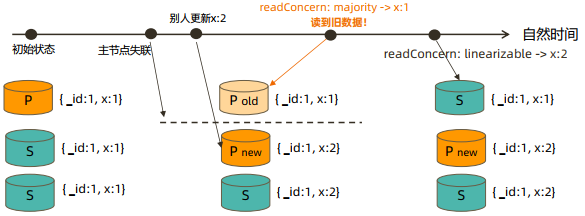
readConcern: linearizable
只读取大多数节点确认过的数据。和 majority 最大差别是保证绝对的操作线性顺序:
在写操作自然时间后面的发生的读,一定可以读到之前的写(会在读取的节点,向其他所有节点发起确认请求)
- 只对读取单个文档时有效;
- 可能导致非常慢的读,因此总是建议配合使用 maxTimeMS;
下图情况是在主节点网络异常时,从节点发起选举期间发生的脏读
readConcern: snapshot(最高级别)
{readConcern: “snapshot”} 只在多文档事务中生效。将一个事务的 readConcern
设置为 snapshot,将保证在事务中的读:
• 不出现脏读;
• 不出现不可重复读;
• 不出现幻读。
因为所有的读都将使用同一个快照,直到事务提交为止该快照才被释放。
官网mongoDB Java Client 事务使用示例:
final MongoClient client = MongoClients.create(uri); /* Prereq: Create collections. CRUD operations in transactions must be on existing collections. */ client.getDatabase("mydb1").getCollection("foo") .withWriteConcern(WriteConcern.MAJORITY).insertOne(new Document("abc", 0)); client.getDatabase("mydb2").getCollection("bar") .withWriteConcern(WriteConcern.MAJORITY).insertOne(new Document("xyz", 0)); /* Step 1: Start a client session. */ final ClientSession clientSession = client.startSession(); /* Step 2: Optional. Define options to use for the transaction. */ TransactionOptions txnOptions = TransactionOptions.builder() .readPreference(ReadPreference.primary()) .readConcern(ReadConcern.LOCAL) .writeConcern(WriteConcern.MAJORITY) .build(); /* Step 3: Define the sequence of operations to perform inside the transactions. */ TransactionBody txnBody = new TransactionBody<String>() { public String execute() { MongoCollection<Document> coll1 = client.getDatabase("mydb1").getCollection("foo"); MongoCollection<Document> coll2 = client.getDatabase("mydb2").getCollection("bar"); /* Important:: You must pass the session to the operations. */ coll1.insertOne(clientSession, new Document("abc", 1)); coll2.insertOne(clientSession, new Document("xyz", 999)); return "Inserted into collections in different databases"; } }; try { /* Step 4: Use .withTransaction() to start a transaction, execute the callback, and commit (or abort on error). */ clientSession.withTransaction(txnBody, txnOptions); } catch (RuntimeException e) { // some error handling } finally { clientSession.close(); }
java 示例2:
//MongoDB 多文档事务的使用方式与关系数据库非常相似: try (ClientSession clientSession = client.startSession()) { clientSession.startTransaction(); collection.insertOne(clientSession, docOne); collection.insertOne(clientSession, docTwo); clientSession.commitTransaction(); }
db.fsyncLock() 与db.fsyncUnlock() 可以锁定/解锁节点的写入,可以用来做事务代码的测试。