相关文章链接
CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令
CentOS6安装各种大数据软件 第三章:Linux基础软件的安装
CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
CentOS6安装各种大数据软件 第五章:Kafka集群的配置
CentOS6安装各种大数据软件 第六章:HBase分布式集群的配置
CentOS6安装各种大数据软件 第七章:Flume安装与配置
CentOS6安装各种大数据软件 第八章:Hive安装和配置
CentOS6安装各种大数据软件 第九章:Hue大数据可视化工具安装和配置
CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
1. Hive概述
1.1. 什么是Hive
hive是有Facebook开源用于解决海量结构化日志的数据统计,Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL查询功能.Hive是构建在Hadoop之上的数据仓库,使用HQL作为查询接口,使用HDFS进行存储,使用MapReduce进行计算.其本质是将HQL转化成MapReduce程序,灵活性和扩展性比较好,支持UDF,自定义存储格式等,适合做离线数据处理。
1.2. Hive在Hadoop生态系统中的位置
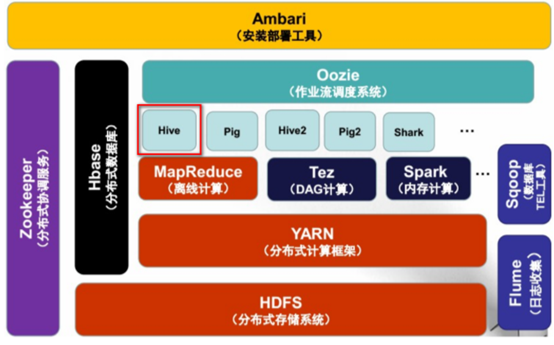
1.3. Hive架构设计

Ø Client:用户接口
n CLI(hive shell)
n JDBC/ODBC(Java访问hive)
n WEBUI(浏览器访问hive)
Ø Meta store:元数据
n 元数据主要包括,表名,表所属的数据库(默认是default),表的拥有者,列/分区字段,表的类型(是否是外部表),表的数据所在目录等,默认存储在自带的derby数据库中,推荐使用采用MySQL存储Metastore;
Ø Hadoop
n 使用HDFS进行存储,使用MapReduce进行计算
Ø Driver:驱动器(包含:解析器,编译器,优化器,执行器)
n 解析器:将SQL字符串转换成抽象语法树AST,这一步,一般都是使用第三方工具库完成,比如antlr,对AST进行语法分析,比如表是否存在,字段是否存在,SQL语义是否有误(比如select语句中被判定为聚合的字段在group by中是否有出现)
n 编译器:将AST编译生成逻辑执行计划
n 优化器:对逻辑执行计划进行优化
n 执行器:把逻辑执行计划转换成可以运行的物理计划,对于hive来说,就是MR
1.4. Hive的优点以及应用场景
Ø 操作接口采用类SQL语法,提供快速开发的能力(简单,容易上手)
Ø 避免了去写MapReduce,减少开发人员的学习成本
Ø 统一的元数据管理,可以与impala/spark等共享数据
Ø 易扩展(HDFS+MapReduce:可以扩展集群规模,支持自定义函数)
Ø 数据的离线处理:比如:日志分析,海量结构化数据离线分析
Ø Hive的执行延迟比较高,因此hive常用于数据分析的,对实时性要求不高的场合
Ø Hive的优势在于处理大数据,对于处理小数据没有优势,因此Hive的执行延迟比较高

2. Hive下载和安装
2.1. Hive的下载
Apache官网:https://archive.apache.org/dist/
Cloudera版本:http://archive-primary.cloudera.com/cdh5/cdh/5/
这里选择下载Apache稳定版本apache-hive-0.13.1-bin.tar.gz,并上传至spark-node04.ouyang.com节点的/opt/softwares/目录下
2.2. Hive的安装
解压即安装:tar -zxvf apache-hive-0.13.1-bin.tar.gz -C /opt/modules/
3. Hive配置
3.1. 在hive-log4j.properties中配置日志存储目录
步骤一:重命名该文件
步骤二:创建存储hive日志的目录
步骤三:配置hive的日志信息的的日志目录(大概20行左右)
hive.log.dir=/export/logs/hive
3.2. 在hive-env.sh中配置Hadoop的安装目录和Hive的配置文件所在位置
# 步骤一:重命名该文件
# 步骤二:修改配置文件
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=/opt/modules/hadoop-2.7.4
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/modules/hive-0.13.1/conf
3.3. 将Hive加入环境变量
export HIVE_HOME=/export/servers/hive
export PATH=${HIVE_HOME}/bin:$PATH
4. Hive启动验证
# 步骤一:启动HDFS服务
bin/hadoop-daemon.sh start namenode
bin/hadoop-daemon.sh start datanode
# 步骤二:创建hive相关目录
bin/hdfs dfs -mkdir -p /user/root/warehouse
# 步骤三:给用户组增加一个写的权限
bin/hdfs dfs -chmod g+w /user/root/warehouse
# 步骤四:启动hive服务
./bin/hive
# 步骤五:进行hive的基本操作(跟MySQL操作基本类似)
show databases;
5. Hive和MySQL集成
5.1 配置MySQL作为元数据库
Hive默认是将元数据存储在本地,但是这样的话,就会导致元数据不同步.不利于我们以后的操作,所以,我们一般情况下都是使用MySQL作为元数据库,用来存放元数据。
首先需要在hive安装目录下的conf目录下创建一个文件hive-site.xml,也可以将hive-default.xml.template这个文件修改为hive-site.xml.在这个文件中主要配置连接数据库的一些信息。
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!--数据库的连接--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node01.ouyang.com:3306/hive?createDatabaseIfNotExist=true</value> </property> <!--驱动名称--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!--数据库用户名称--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!--数据库密码--> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> </configuration>
5.2. 设置MySQL的远程连接
#登陆mysql数据库服务器
mysql -uroot -p
#切换到mysql数据库
use mysql
#查看user表中的host,user,password三个字段
select user,host,password from user;
#更新用户信息
update user set host = '%' where user = 'root' and host = 'localhost';
#删除其他用户
delete from user where password = '';
#刷新权限修改
flush privileges;
5.3. 将MySQL驱动添加到hive的lib目录

6. Hive服务启动与测试
6.1. 启动HDFS服务
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
6.2. 启动hive服务
bin/hive
6.3. hive服务创建表
create table student(id Int,name String) row format delimited fields terminated by ' ';
6.4. 准备数据文件
vim /opt/datas/student.txt
1 zhangsan
2 lisi
3 wangwu
4 tingting
5 nana
6 haha
6.5. 加载数据到hive表
# 在hive的窗口下执行如下命令:
load data local inpath '/opt/datas/student.txt' into table student
7. 使用sql developer连接Hive
7.1. 解压hive驱动
将“hive_jdbc_2.6.2.1002.zip”进行解压,之后进入解压的目录,再解压“ClouderaHiveJDBC4-2.6.2.1002.zip”,里面有一个文件“HiveJDBC4.jar”这个文件就是后续在配置时候需要使用到的。
7.2. 安装sql developer
解压“sqldeveloper-17.2.0.188.1159-no-jre.zip”;之后进入解压处理的目录双击“sqldeveloper.exe”文件;在弹出的视图中指定jdk1.8的路径即可。
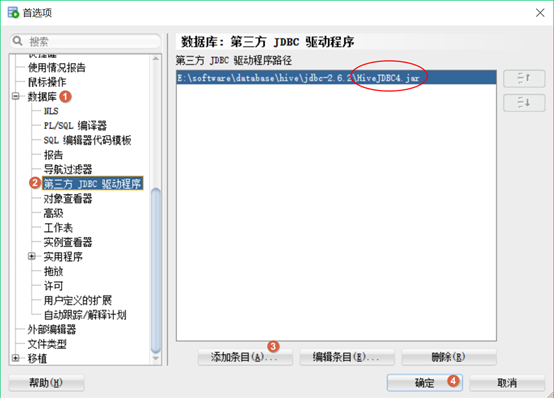
7.3. 配置sql developer
配置首选项,将hive_jdbc的jar包配置进去:

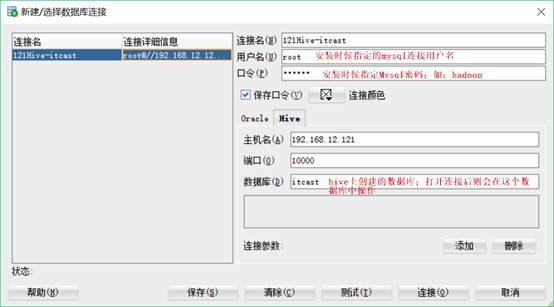
7.4. 使用sql developer连接hive
8. Hive与HBase进行集成
8.1. 在hive-site.xml中配置zookeeper
<!--hive通过zookeeper去连接hbase--> <!-- 整合zookeeper --> <property> <name>hbase.zookeeper.quorum</name> <value>spark-node04.ouyang.com,spark-node05.ouyang.com,spark-node06.ouyang.com</value> </property> <!—在命令行启动hive时,会显示当前数据库和列名等选项 --> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property>
8.2. 整合包引入
将HBase中9个jar包拷贝到hive/lib目录下,因为hive需要用到HBase,所以要导入,如果是CDH版,已经集成好不需要导包。
# 步骤一:在/etc/profile中配置好HBase和Hive的环境变量
export HIVE_HOME=/export/servers/hive
export HBASE_HOME=/export/servers/hbase
# 步骤二:创建软链接(请注意包的版本)
ln -s $HBASE_HOME/lib/hbase-server-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-server-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-client-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-client-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-protocol-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-protocol-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-it-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-it-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/htrace-core-2.04.jar $HIVE_HOME/lib/htrace-core-2.04.jar
ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-hadoop2-compat-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compat-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-hadoop-compat-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/high-scale-lib-1.1.1.jar $HIVE_HOME/lib/high-scale-lib-1.1.1.jar
ln -s $HBASE_HOME/lib/hbase-common-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-common-0.98.6-cdh5.3.0.jar
8.3. 创建与HBase集成的HIve的外部表(Hive和HBase集成,就是使用Hive操作HBase中的表,相对于Hive来说是外部,所以是外部表)
--创建hbase的外部表
--HBase中的表可以在Hive中进行操作,创建的表的列与HBase中表的列的对应关系如下设置,可以在Hive中进行表的操作,会更新到HBase中
CREATE EXTERNAL TABLE access(id string,datatime string,userid string,searchname string,retorder string,cliorder string,cliurl string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:datatime,info:userid,info:searchname,info:retorder,info:cliorder,info:cliurl") TBLPROPERTIES ("hbase.table.name" = "access");
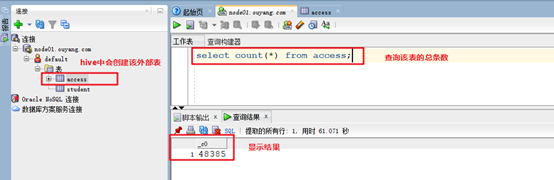
8.4. 使用Hive查看HBase中access表
在Hive中和在HBase中查看的条数会有一点差异,但获取的日志条数为海量数据,该差异可以忽略不计。
9. hive的beeline和hiveserver2的使用
9.1. 启动hiveserver2
#启动hive的server2服务
bin/hiveserver2

9.2. 启动beeline
#启动beeline服务
bin/beeline

9.3. 使用beeline连接hiveserver2服务
#连接hiveserver2服务
!connect jdbc:hive2://spark-node04.ouyang.com:10000

9.4. hive相关操作(类sql语句)
#查看所有的表
show tables;
#查看前10名
select * from access limit 10;
#查看总的记录树
select count(*) from access;
9.5. 创建后台一键启动hiveserver2脚本
vim starthiveserver2.sh ssh node01.ouyang.com "source /etc/profile;nohup sh ${HIVE_HOME}/bin/hiveserver2 >/dev/null 2>&1 &" # 执行该脚本就会后台启动hive服务,可以使用beeline和sql seveloper连接hive