一、MapReduce插件使用(参见https://www.cnblogs.com/yangy1/p/12420047.html)
二、示例
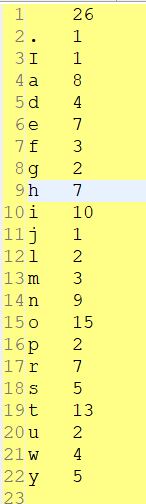
1、CharCount示例
数据文件
I am happy to join with you today in what will go down in history as
the greatest demonstration for freedom in the history of our nation.
CharCountMapper
package com.blb.CharCount; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class CharCountMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ @Override protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException { char[] cs=value.toString().toCharArray(); for (char c : cs) { context.write(new Text(c+""), new LongWritable(1)); } } }
CharCountReducer
package com.blb.CharCount; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class CharCountReducer extends Reducer<Text,LongWritable,Text,LongWritable>{ @Override protected void reduce(Text key,Iterable<LongWritable> values,Context context) throws IOException, InterruptedException { long sum=0; for (LongWritable val : values) { sum+=val.get(); } context.write(key, new LongWritable(sum)); } }
CharCountDriver
package com.blb.CharCount; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class CharCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job job=Job.getInstance(new Configuration()); job.setJarByClass(CharCountDriver.class); job.setMapperClass(CharCountMapper.class); job.setReducerClass(CharCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileInputFormat.addInputPath(job, new Path("hdfs://192.168.0.32:9000/MapReduce/CharCount.txt")); FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.32:9000/MapReduce/CharCount")); job.waitForCompletion(true); } }
输出文件
2、WordCount示例
数据文件
The man who thinks he can by Walter Wintle If you think you are beaten, you are; If you think you dare not, you don’t. If you’d like to win, but you think you can’t, It is almost a certain — you won’t. If you think you’ll lose, you’re lost; For out in this world we find Success begins with a fellow’s will It’s all in the state of mind. If you think you’re outclassed, you are; You’ve got to think high to rise. You’ve got to be sure of yourself before You can ever win the prize. Life’s battles don’t always go To the stronger or faster man; But sooner or later the man who wins Is the one who thinks he can!
WordCountMapper
package com.blb.WordCount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{ String[] arr = value.toString().split(" "); for (String s : arr) { context.write(new Text(s), new IntWritable(1)); } } }
WordCountReducer
package com.blb.WordCount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum=0; for (IntWritable value : values) { sum+=value.get(); } context.write(key, new IntWritable(sum)); } }
WordCountDriver
package com.blb.WordCount; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(WordCountDriver.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setCombinerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("hdfs://192.168.0.32:9000/MapReduce/WordCount.txt")); FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.32:9000/MapReduce/WordCount")); job.waitForCompletion(true); } }
输出文件

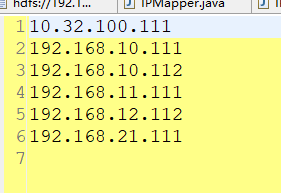
3、IP去重示例
数据文件
192.168.10.111 192.168.10.111 10.32.100.111 192.168.21.111 192.168.10.112 192.168.10.111 192.168.11.111 192.168.12.112 192.168.11.111
IPMapper
package com.blb.IP; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class IPMapper extends Mapper<LongWritable, Text, Text, NullWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(value, NullWritable.get()); } }
IPReducer
package com.blb.IP; import java.io.IOException; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class IPReducer extends Reducer<Text, NullWritable, Text, NullWritable> { @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } }
IPDriver
package com.blb.IP; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class IPDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(IPDriver.class); job.setMapperClass(IPMapper.class); job.setReducerClass(IPReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.addInputPath(job, new Path("hdfs://192.168.0.32:9000/MapReduce/IP.txt")); FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.32:9000/MapReduce/IP")); job.waitForCompletion(true); } }
输出文件
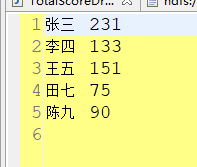
4、TotleScore示例
数据文件
张三 78 李四 66 王五 73 张三 88 田七 75 张三 65 陈九 90 李四 67 王五 78
TotleScoreMapper
package com.blb.TotalScore; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class TotalScoreMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] arr = value.toString().split(" "); context.write(new Text(arr[0]),new IntWritable(Integer.parseInt(arr[1]))); } }
TotleScoreReducer
package com.blb.TotalScore; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class TotalScoreReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum+=value.get(); } context.write(key, new IntWritable(sum)); } }
TotleScoreDriver
package com.blb.TotalScore; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TotalScoreDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(TotalScoreDriver.class); job.setMapperClass(TotalScoreMapper.class); job.setReducerClass(TotalScoreReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("hdfs://192.168.0.32:9000/MapReduce/TotalScore.txt")); FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.32:9000/MapReduce/TotalScore")); job.waitForCompletion(true); } }
输出文件